Redis的4种缓存模式分享
目录
- 概述
- 缓存策略的选择
- Cache Aside
- Read Through
- Write Through
- Write-Behind
- 小结
概述
在系统架构中,缓存可谓提供系统性能的最简单方法之一,稍微有点开发经验的同学必然会与缓存打过交道,最起码也实践过。
如果使用得当,缓存可以减少响应时间、减少数据库负载以及节省成本。但如果缓存使用不当,则可能出现一些莫名其妙的问题。
在不同的场景下,所使用的缓存策略也是有变化的。如果在你的印象和经验中,缓存还只是简单的查询、更新操作,那么这篇文章真的值得你学习一下。
在这里,为大家系统地讲解4种缓存模式以及它们的使用场景、流程以及优缺点。
缓存策略的选择
本质上来讲,缓存策略取决于数据和数据访问模式。换句话说,数据是如何写和读的。
例如:
- 系统是写多读少的吗?(例如,基于时间的日志)
- 数据是否是只写入一次并被读取多次?(例如,用户配置文件)
- 返回的数据总是唯一的吗?(例如,搜索查询)
选择正确的缓存策略才是提高性能的关键。
常用的缓存策略有以下五种:
- Cache-Aside Pattern:旁路缓存模式
- Read Through Cache Pattern:读穿透模式
- Write Through Cache Pattern:写穿透模式
- Write Behind Pattern:又叫Write Back,异步缓存写入模式
上述缓存策略的划分是基于对数据的读写流程来区分的,有的缓存策略下是应用程序仅和缓存交互,有的缓存策略下应用程序同时与缓存和数据库进行交互。因为这个是策略划分比较重要的一个维度,所以在后续流程学习时大家需要特别留意一下。
Cache Aside
Cache Aside是最常见的缓存模式,应用程序可直接与缓存和数据库对话。Cache Aside可用来读操作和写操作。
读操作的流程图:
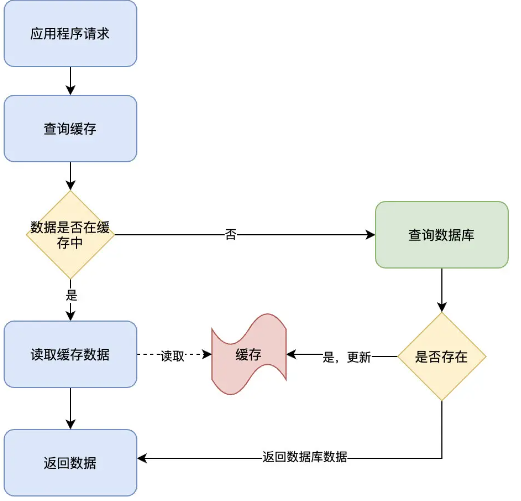
读操作的流程:
- 应用程序接收到数据查询(读)请求;
- 应用程序所需查询的数据是否在缓存上:
- 如果存在(Cache hit),从缓存上查询出数据,直接返回;
- 如果不存在(Cache miss),则从数据库中检索数据,并存入缓存中,返回结果数据;
这里我们需要留意一个操作的边界,也就是数据库和缓存的操作均由应用程序直接进行操作。
写操作的流程图:

这里的写操作,包括创建、更新和删除。在写操作的时候,Cache Aside模式是先更新数据库(增、删、改),然后直接删除缓存。
Cache Aside模式可以说适用于大多数的场景,通常为了应对不同类型的数据,还可以有两种策略来加载缓存:
- 使用时加载缓存:当需要使用缓存数据时,从数据库中查询出来,第一次查询之后,后续请求从缓存中获得数据;
- 预加载缓存:在项目启动时或启动后通过程序预加载缓存信息,比如”国家信息、货币信息、用户信息,新闻信息“等不是经常变更的数据。
Cache Aside适用于读多写少的场景,比如用户信息、新闻报道等,一旦写入缓存,几乎不会进行修改。该模式的缺点是可能会出现缓存和数据库双写不一致的情况。
Cache Aside也是一个标准的模式,像Facebook便是采用的这种模式。
Read Through
Read-Through和Cache-Aside很相似,不同点在于程序不需要关注从哪里读取数据(缓存还是数据库),它只需要从缓存中读数据。而缓存中的数据从哪里来是由缓存决定的。
Cache Aside是由调用方负责把数据加载入缓存,而Read Through则用缓存服务自己来加载,从而对应用方是透明的。Read-Through的优势是让程序代码变得更简洁。
这里就涉及到我们上面所说的应用程序操作边界问题了,直接来看流程图:

在上述流程图中,重点关注一下虚线框内的操作,这部分操作不再由应用程序来处理,而是由缓存自己来处理。也就是说,当应用从缓存中查询某条数据时,如果数据不存在则由缓存来完成数据的加载,最后再由缓存返回数据结果给应用程序。
Write Through
在Cache Aside中,应用程序需要维护两个数据存储:一个缓存,一个数据库。这对于应用程序来说,有一些繁琐。
Write-Through模式下,所有的写操作都经过缓存,每次向缓存中写数据时,缓存会把数据持久化到对应的数据库中去,且这两个操作在一个事务中完成。因此,只有两次都写成功了才是最终写成功了。坏处是有写延迟,好处是保证了数据的一致性。
可以理解为,应用程序认为后端就是一个单一的存储,而存储自身维护自己的Cache。
因为程序只和缓存交互,编码会变得更加简单和整洁,当需要在多处复用相同逻辑时这点就变得格外明显。
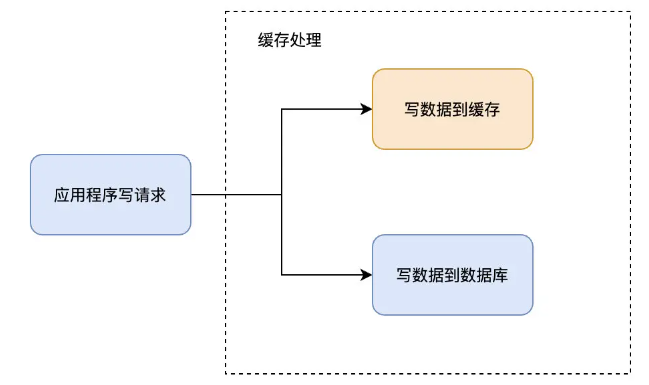
当使用Write-Through时,一般都配合使用Read-Through来使用。Write-Through的潜在使用场景是银行系统。
Write-Through适用情况有:
- 需要频繁读取相同数据
- 不能忍受数据丢失(相对Write-Behind而言)和数据不一致
在使用Write-Through时要特别注意的是缓存的有效性管理,否则会导致大量的缓存占用内存资源。甚至有效的缓存数据被无效的缓存数据给清除掉。
Write-Behind
Write-Behind和Write-Through在”程序只和缓存交互且只能通过缓存写数据“这方面很相似。不同点在于Write-Through会把数据立即写入数据库中,而Write-Behind会在一段时间之后(或是被其他方式触发)把数据一起写入数据库,这个异步写操作是Write-Behind的最大特点。
数据库写操作可以用不同的方式完成,其中一个方式就是收集所有的写操作并在某一时间点(比如数据库负载低的时候)批量写入。另一种方式就是合并几个写操作成为一个小批次操作,接着缓存收集写操作一起批量写入。
异步写操作极大的降低了请求延迟并减轻了数据库的负担。同时也放大了数据不一致的。比如有人此时直接从数据库中查询数据,但是更新的数据还未被写入数据库,此时查询到的数据就不是最新的数据。
小结
不同的缓存模式有不同的考量点和特征,根据应用程序需求场景的不同,需要灵活的选择适配的缓存模式。在实践的过程中往往也是多种模式相结合来使用。
到此这篇关于Redis的4种缓存模式分享的文章就介绍到这了,更多相关Redis缓存模式内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

利用Redis进行数据缓存的项目实践
目录 1. 引言 2. 将信息添加到缓存的业务流程 3. 实现代码 3.1 代码实现(信息添加到缓存中) 3.2 缓存更新策略 3.3 实现主动更新 4. 缓存穿透 4.1 解决缓存穿透(使用空对象进行解决) 5. 缓存雪崩 6. 缓存击穿 6.1 互斥锁代码 6.2 逻辑过期实现 1. 引言 缓存有啥用? 降低对数据库的请求,减轻服务器压力 提高了读写效率 缓存有啥缺点? 如何保证数据库与缓存的数据一致性问题? 维护缓存代码 搭建缓存一般是以集群的形式进行搭建,需要运维的成本 2. 将信息添加
-
详解Spring Cache使用Redisson分布式锁解决缓存击穿问题
目录 1 什么是缓存击穿 2 为什么要使用分布式锁 3 什么是Redisson 4 Spring Boot集成Redisson 4.1 添加maven依赖 4.2 配置yml 4.3 配置RedissonConfig 5 使用Redisson的分布式锁解决缓存击穿 1 什么是缓存击穿 一份热点数据,它的访问量非常大.在其缓存失效的瞬间,大量请求直达存储层,导致服务崩溃. 2 为什么要使用分布式锁 在项目中,当共享资源出现竞争情况的时候,为了防止出现并发问题,我们一般会采用锁机制来控制.在单机环境
-
Redis缓存三大异常的处理方案梳理总结
目录 前言 一.背景 二.缓存雪崩 (一)是什么 (二)为什么 (三)怎么办 三.缓存击穿 (一)是什么 (二)为什么 (三)怎么办 四.缓存穿透 (一)是什么 (二)为什么 (三)怎么办 五.其他 (一)缓存预热 (二)缓存降级 六.总结 前言 Redis作为一个高性能的内存中的key-value数据结构存储系统,在我们日常开发中广泛应用于缓存.计数器.消息队列.排行榜等场景中,尤其是作为最常用的缓存方式,在提高数据查询效率.保护数据库等方面起到了不可磨灭的作用,但实际应用中,可能会出现一些R
-
GoFrame gredis缓存DoVar Conn连接对象 自动序列化
目录 整体介绍 小技巧 基本使用 HSET/HGETALL操作 HMSET/HMGET操作 基本使用 Send批量指令 订阅/发布 map存取 打印结果 struct存取 打印结果 上一篇文章为大家介绍了 GoFrame gcache使用实践 | 缓存控制 淘汰策略 ,得到了大家积极的反馈. 后续几篇文章再接再厉,仍然为大家介绍GoFrame框架缓存相关的知识点,以及自己项目使用中的一些总结思考,GoFrame框架下文简称gf. 这篇文章比较硬核,爆肝2千字,阅读大约需要5~8分钟. 详细的介绍
-
基于Redis缓存数据常见的三种问题及解决
目录 1.缓存穿透 1.1 问题描述 1.2 解决方法 2.缓存击穿 2.1 问题描述 2.2 解决方法 3.缓存雪崩 3.1 问题描述 3.2 解决方法 1.缓存穿透 1.1 问题描述 缓存穿透是在客户端/浏览器端请求一个不存在的key,这个key在redis中不存在,在数据库中也不存在数据源,每次对此key的请求从缓存获取不到,就会请求数据源. 如使用一个不存在的用户id去访问用户信息,redis和数据库中都没有,多次进行请求可能会压垮数据源 1.2 解决方法 一个一定不存在缓存及查询不到的
-
Redis三种常用的缓存读写策略步骤详解
目录 一.Redis三种常用的缓存读写策略 二.旁路缓存模式(Cache Aside Pattern) 读写步骤 写: 读: 自我思考 缺点 三.读写穿透(Read/Write Through Pattern) 读写步骤 写: 读: 四.异步缓存写入(Write Behind Pattern) 一.Redis三种常用的缓存读写策略 Redis有三种读写策略分别是:旁路缓存模式策略.读写穿透策略.异步缓存写入策略. 这三种缓存读写策略各有优势,不存在最佳,需要我们根据实际的业务场景选择最合适的.
-
Redis+Caffeine两级缓存的实现
目录 优点与问题 准备工作 V1.0版本 V2.0版本 V3.0版本 在高性能的服务架构设计中,缓存是一个不可或缺的环节.在实际的项目中,我们通常会将一些热点数据存储到Redis或MemCache这类缓存中间件中,只有当缓存的访问没有命中时再查询数据库.在提升访问速度的同时,也能降低数据库的压力. 随着不断的发展,这一架构也产生了改进,在一些场景下可能单纯使用Redis类的远程缓存已经不够了,还需要进一步配合本地缓存使用,例如Guava cache或Caffeine,从而再次提升程序的响应速度与
-
Redis做预定库存缓存功能设计使用
目录 最近在自己的工作中,把其中一个PHP项目的缓存从以前的APC缓存逐渐切换到Redis中,并且根据Redis所支持的数据结构做了库存维护功能.缓存是在业务层做的,准确讲应该是在MVC模型中Model的ORM里面.主要逻辑就是先查缓存,查不到的话再查数据库.不过这些不是本文的主要内容,下面我把库存管理功能的缓存设计思路分享一下,希望能带给大家一些收获,有不足之处或者有更好方案的,也希望各位多多指教. 一.业务背景 为了略去我们公司项目背景,我决定把这次的问题类比成一个考卷上的问题.至于业务细节
-
Redis的4种缓存模式分享
目录 概述 缓存策略的选择 Cache Aside Read Through Write Through Write-Behind 小结 概述 在系统架构中,缓存可谓提供系统性能的最简单方法之一,稍微有点开发经验的同学必然会与缓存打过交道,最起码也实践过. 如果使用得当,缓存可以减少响应时间.减少数据库负载以及节省成本.但如果缓存使用不当,则可能出现一些莫名其妙的问题. 在不同的场景下,所使用的缓存策略也是有变化的.如果在你的印象和经验中,缓存还只是简单的查询.更新操作,那么这篇文章真的值得你学
-
浅谈django三种缓存模式的使用及注意点
django是动态网页,一般来说需要实时的生成访问的页面,展示给访问者,这样,内容可以随时变化,也就说请求到达视图函数之后,然后进行模板渲染,将字符串返回给用户,用户会看到相应的html页面.但是如果每次请求都从数据库中请求并获取数据,并且当用户并发量十分大的时候,这将服务器性能将大大受到影响.因此使用缓存能有效的解决这类问题.如果能将渲染后的结果放到速度更快的缓存中,每次有请求过来,先检查缓存中是否有对应的资源,如果有,直接从缓存中取出来返回响应,节省取数据和渲染的时间,不仅能大大提高系统性能
-
分享ajax的三种解析模式
一.Ajax中的JSON格式 html代码: <html> <body> <input type="button" value="Ajax" id="btn"> <script> var btn = document.getElementById("btn"); btn.onclick = function(){ var xhr = getXhr(); xhr.open(&quo
-
分享JavaScript的 3 种工厂模式的用法
目录 一.简单工厂模式 二.工厂方法模式 抽象工厂模式 三.小结 前言; 工厂模式(Factory Pattern)是设计模式中最常用的设计模式之一. 这种类型的设计模式属于创建型模式,它提供了一种创建对象的最佳方式. 在工厂模式中,我们在创建对象时不会对客户端暴露创建逻辑,并且是通过使用一个共同的接口来指向新创建的对象. 工厂模式分为: 简单工厂模式 工厂方法模式 抽象工厂模式 一.简单工厂模式 简单工厂模式,也可以叫静态工厂模式,用一个工厂对象创建同一类对象类的实例. 比如: // 0.0.
-
redis的2种持久化方案深入讲解
前言 Redis是一种高级key-value数据库.它跟memcached类似,不过数据可以持久化,而且支持的数据类型很丰富.有字符串,链表,集 合和有序集合.支持在服务器端计算集合的并,交和补集(difference)等,还支持多种排序功能.所以Redis也可以被看成是一个数据结构服务 器. Redis的所有数据都是保存在内存中,然后不定期的通过异步方式保存到磁盘上(这称为"半持久化模式"):也可以把每一次数据变化都写入到一个append only file(aof)里面(这称为&q
-
php使用redis的几种常见操作方式和用法示例
本文实例讲述了php使用redis的几种常见操作方式和用法.分享给大家供大家参考,具体如下: 一.简单的字符串缓存 比如针对一些sql查询较慢,更新不频繁的数据进行缓存. <?php $redis = new Redis(); $redis->connect('127.0.0.1', 6379, 60); $sql = 'select * from tb_order order by id desc limit 10'; //伪代码,从数据库中获取数据 $data = $db->quer
-
一文掌握Redis的三种集群方案(小结)
在开发测试环境中,我们一般搭建Redis的单实例来应对开发测试需求,但是在生产环境,如果对可用性.可靠性要求较高,则需要引入Redis的集群方案.虽然现在各大云平台有提供缓存服务可以直接使用,但了解一下其背后的实现与原理总还是有些必要(比如面试), 本文就一起来学习一下Redis的几种集群方案. Redis支持三种集群方案 主从复制模式 Sentinel(哨兵)模式 Cluster模式 主从复制模式 1. 基本原理 主从复制模式中包含一个主数据库实例(master)与一个或多个从数据库实例(sl
-
详解Spring Boot 访问Redis的三种方式
目录 前言 开始准备 RedisTemplate JPA Repository Cache 总结 前言 最近在极客时间上面学习丁雪丰老师的<玩转 Spring 全家桶>,其中讲到访问Redis的方式,我专门把他们抽出来,在一起对比下,体验一下三种方式开发上面的不同, 分别是这三种方式 RedisTemplate JPA Repository Cache 开始准备 开始之前我们需要有Redis安装,我们采用本机Docker运行Redis, 主要命令如下 docker pull redis doc