如何更改 pandas dataframe 中两列的位置
如何更改 pandas dataframe 中两列的位置:
把其中的某列移到第一列的位置。
原来的 df 是:
df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01.csv')
Net Upper Lower Mid Zsore
Answer option
More than once a day 0% 0.22% -0.12% 2 65
Once a day 0% 0.32% -0.19% 3 45
Several times a week 2% 2.45% 1.10% 4 78
Once a week 1% 1.63% -0.40% 6 65
要将 Mid 这一列移动到第一列?
Mid Upper Lower Net Zsore Answer option More than once a day 2 0.22% -0.12% 0% 65 Once a day 3 0.32% -0.19% 0% 45 Several times a week 4 2.45% 1.10% 2% 78 Once a week 6 1.63% -0.40% 1% 65
解决办法:(使用 ix )
法一:
In [27]:
# get a list of columns
cols = list(df)
# move the column to head of list using index, pop and insert
cols.insert(0, cols.pop(cols.index('Mid')))
cols
Out[27]:
['Mid', 'Net', 'Upper', 'Lower', 'Zsore']
In [28]:
# use ix to reorder
df = df.ix[:, cols]
df
Out[28]:
Mid Net Upper Lower Zsore
Answer_option
More_than_once_a_day 2 0% 0.22% -0.12% 65
Once_a_day 3 0% 0.32% -0.19% 45
Several_times_a_week 4 2% 2.45% 1.10% 78
Once_a_week 6 1% 1.63% -0.40% 65
法二:
In [39]:
mid = df['Mid']
df.drop(labels=['Mid'], axis=1,inplace = True)
df.insert(0, 'Mid', mid)
df
Out[39]:
Mid Net Upper Lower Zsore
Answer_option
More_than_once_a_day 2 0% 0.22% -0.12% 65
Once_a_day 3 0% 0.32% -0.19% 45
Several_times_a_week 4 2% 2.45% 1.10% 78
Once_a_week 6 1% 1.63% -0.40% 65
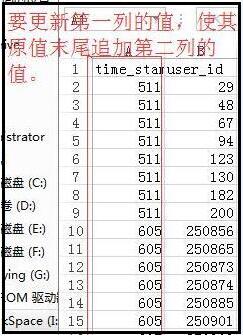
#### full data
df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01.csv')
def func(x):
return str(x['time_stamp'])+str(x['user_id'])
df['session_id'] = df.apply(func, axis=1)
del df['time_stamp']
sessionID=df['session_id']
df.drop(labels=['session_id'],axis=1,inplace=True)
df.insert(0,'session_id',sessionID)
df.to_csv('I:/Papers/consumer/codeandpaper/TmallData/result02.csv')
最终的处理结果:
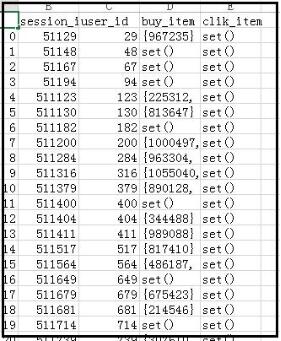
以上这篇如何更改 pandas dataframe 中两列的位置就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
python dataframe向下向上填充,fillna和ffill的方法
首先新建一个dataframe: In[8]: df = pd.DataFrame({'name':list('ABCDA'),'house':[1,1,2,3,3],'date':['2010-01-01','2010-06-09','2011-12-03','2011-04-05','2012-03-23']}) In[9]: df Out[9]: date house name 0 2010-01-01 1 A 1 2010-06-09 1 B 2 2011-12-03 2 C 3 201
-
pandas对dataFrame中某一个列的数据进行处理的方法
背景:dataFrame的数据,想对某一个列做逻辑处理,生成新的列,或覆盖原有列的值 下面例子中的df均为pandas.DataFrame()的数据 1.增加新列,或更改某列的值 df["列名"]=值 如果值为固定的一个值,则dataFrame中该列所有值均为这个数据 2.处理某列 df["列名"]=df.apply(lambda x:方法名(x,入参2),axis=1) 说明: 1.方法名为单独的方法名,可以处理传入的x数据 2.x为每一行的数据,做为方法的入参1
-
Pandas 解决dataframe的一列进行向下顺移问题
最近做比赛,有时候需要造出新的特征,而这次遇到的问题是将一列数据往下顺移一位.同时将开头缺失的那一个数据用其他方式填充. df['feature'].shift(1)向下顺移一位,这时第一位会置为nan,需要填充. ----------------------历史分割线----------------- 错误方案: 当时首先想到的是用loc来直接进行替换,也就是 i = len(dt) dt_new = pd.DataFrame() dt_new.loc[0, 'test'] = 0 dt_ne
-
如何更改 pandas dataframe 中两列的位置
如何更改 pandas dataframe 中两列的位置: 把其中的某列移到第一列的位置. 原来的 df 是: df = pd.read_csv('I:/Papers/consumer/codeandpaper/TmallData/result01.csv') Net Upper Lower Mid Zsore Answer option More than once a day 0% 0.22% -0.12% 2 65 Once a day 0% 0.32% -0.19% 3 45 Sever
-

Python 处理 Pandas DataFrame 中的行和列
目录 处理列 处理行 前言: 数据框是一种二维数据结构,即数据以表格的方式在行和列中对齐.我们可以对行/列执行基本操作,例如选择.删除.添加和重命名.在本文中,我们使用的是nba.csv文件. 处理列 为了处理列,我们对列执行基本操作,例如选择.删除.添加和重命名. 列选择:为了在 Pandas DataFrame 中选择一列,我们可以通过列名调用它们来访问这些列. # Import pandas package import pandas as pd # 定义包含员工数据的字典 data =
-
详解Pandas如何高效对比处理DataFrame的两列数据
目录 楔子 combine_first combine update 楔子 我们在用 pandas 处理数据的时候,经常会遇到用其中一列数据替换另一列数据的场景.比如 A 列和 B 列,对 A 列中不为空的数据不作处理,对 A 列中为空的数据使用 B 列对应索引的数据进行替换.这一类的需求估计很多人都遇到,当然还有其它更复杂的. 解决这类需求的办法有很多,这里我们来推荐几个. combine_first 这个方法是专门用来针对空值处理的,我们来看一下用法. import pandas as pd
-
对pandas将dataframe中某列按照条件赋值的实例讲解
在数据处理过程中,经常会出现对某列批量做某些操作,比如dataframe df要对列名为"values"做大于等于30设置为1,小于30设置为0操作,可以这样使用dataframe的apply函数来实现, 具体实现代码如下: def fun(x): if x >= 30: return 1 else: return 0 values= feature['values'].apply(lambda x: fun(x)) 具体的逻辑可以修改fun函数来实现,但是按照某些条件选择列不是
-
在Pandas DataFrame中插入一列的方法实例
目录 引言 示例1:插入新列作为第一列 示例2:插入新列作为中间列 示例3:插入新列作为最后一列 补充:按条件选择分组分别赋值 总结 引言 通常,您可能希望在 Pandas DataFrame 中插入一个新列.幸运的是,使用 pandas insert()函数很容易做到这一点,该函数使用以下语法: insert(loc, column, value, allow_duplicates=False) 在哪里: loc: 插入列的索引.第一列是 0. column: 赋予新列的名称. value:
-
pandas.DataFrame中提取特定类型dtype的列
目录 select_dtypes()的基本用法 指定要提取的类型:参数include 指定要排除的类型:参数exclude pandas.DataFrame为每一列保存一个数据类型dtype. 要仅提取(选择)特定数据类型为dtype的列,请使用pandas.DataFrame的select_dtypes()方法. 以带有各种数据类型的列的pandas.DataFrame为例. import pandas as pd df = pd.DataFrame({'a': [1, 2, 1, 3],
-
pandas DataFrame 根据多列的值做判断,生成新的列值实例
环境:Python3.6.4 + pandas 0.22 主要是DataFrame.apply函数的应用,如果设置axis参数为1则每次函数每次会取出DataFrame的一行来做处理,如果axis为1则每次取一列. 如代码所示,判断如果城市名中含有ing字段且年份为2016,则新列test值赋为1,否则为0. import numpy as np import pandas as pd data = {'city': ['Beijing', 'Shanghai', 'Guangzhou', 'S
-
Pandas DataFrame中的tuple元素遍历的实现
pandas中遍历dataframe的每一个元素 假如有一个需求场景需要遍历一个csv或excel中的每一个元素,判断这个元素是否含有某个关键字 那么可以用python的pandas库来实现. 方法一: pandas的dataframe有一个很好用的函数applymap,它可以把某个函数应用到dataframe的每一个元素上,而且比常规的for循环去遍历每个元素要快很多.如下是相关代码: import pandas as pd data = [["str","ewt"
-
详解pandas.DataFrame中删除包涵特定字符串所在的行
你在使用pandas处理DataFrame中是否遇到过如下这类问题?我们需要删除某一列所有元素中含有固定字符元素所在的行,比如下面的例子: 以上所述是小编给大家介绍的pandas.DataFrame中删除包涵特定字符串所在的行详解整合,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的.在此也非常感谢大家对我们网站的支持!
-
pandas dataframe 中的explode函数用法详解
在使用 pandas 进行数据分析的过程中,我们常常会遇到将一行数据展开成多行的需求,多么希望能有一个类似于 hive sql 中的 explode 函数. 这个函数如下: Code # !/usr/bin/env python # -*- coding:utf-8 -*- # create on 18/4/13 import pandas as pd def dataframe_explode(dataframe, fieldname): temp_fieldname = fieldname