python 实现rolling和apply函数的向下取值操作
我就废话不多说了,大家还是直接看代码吧!
import pandas as pd
def get_under_rolling(df,window,user,name):
df[name] = df[user].iloc[::-1].rolling(window=window).apply(lambda x:x[0]).iloc[::-1]
return df
if __name__ == '__main__':
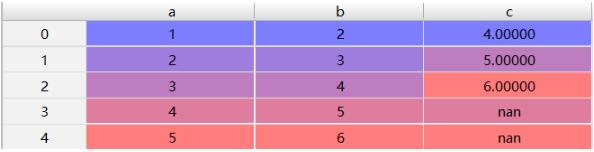
df = pd.DataFrame({'a':[1,2,3,4,5],
'b':[2,3,4,5,6]})
# 把b列向下取值作为新的c列
df = get_under_rolling(df, window=3, user='b',name='c')
原始df

新的df
补充知识:python:利用rolling和apply对DataFrame进行多列滚动,数据框滚动
看代码~
# 设置一个初始数据框
df1 = [1,2,3,4,5]
df2 = [2,3,4,5,6]
df = pd.DataFrame({'a':list(df1),'b':list(df2)})
print(df)
a b 0 1 2 1 2 3 2 3 4 3 4 5 4 5 6
下面是滚动函数
# 多列滚动函数
# handle对滚动的数据框进行处理
def handle(x,df,name,n):
df = df[name].iloc[x:x+n,:]
print(df)
return 1
# group_rolling 进行滚动
# n:滚动的行数
# df:目标数据框
# name:要滚动的列名
def group_rolling(n,df,name):
df_roll = pd.DataFrame({'a':list(range(len(df)-n+1))})
df_roll['a'].rolling(window=1).apply(lambda x:handle(int(x[0]),df,name,n),raw=True)
对初始数据框进行滚动
其中:
n=2,name=[‘a',‘b']
group_rolling(n=2,df=df,name=['a','b'])
每次滚动的结果如下:
a b 0 1 2 1 2 3 a b 1 2 3 2 3 4 a b 2 3 4 3 4 5 a b 3 4 5 4 5 6
以上这篇python 实现rolling和apply函数的向下取值操作就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
Python中apply函数的用法实例教程
一.概述: python apply函数的具体含义如下: apply(func [, args [, kwargs ]]) 函数用于当函数参数已经存在于一个元组或字典中时,间接地调用函数.args是一个包含将要提供给函数的按位置传递的参数的元组.如果省略了args,任何参数都不会被传递,kwargs是一个包含关键字参数的字典. apply()的返回值就是func()的返回值,apply()的元素参数是有序的,元素的顺序必须和func()形式参数的顺序一致 二.使用示例: 下面给几个例子来
-
对pandas中时间窗函数rolling的使用详解
在建模过程中,我们常常需要需要对有时间关系的数据进行整理.比如我们想要得到某一时刻过去30分钟的销量(产量,速度,消耗量等),传统方法复杂消耗资源较多,pandas提供的rolling使用简单,速度较快. 函数原型和参数说明 DataFrame.rolling(window, min_periods=None, freq=None, center=False, win_type=None, on=None, axis=0, closed=None) window:表示时间窗的大小,注意有两种形式
-
python pandas移动窗口函数rolling的用法
超级好用的移动窗口函数 最近经常使用移动窗口函数,觉得很方便,功能强大,代码简单,故将pandas中的移动窗口函数都做介绍.它都是以rolling打头的函数,后接具体的函数,来显示该移动窗口函数的功能. rolling_count 计算各个窗口中非NA观测值的数量 函数 pandas.rolling_count(arg, window, freq=None, center=False, how=None) arg : DataFrame 或 numpy的ndarray 数组格式 window :
-
python numpy实现rolling滚动案例
相比较pandas,numpy并没有很直接的rolling方法,但是numpy 有一个技巧可以让NumPy在C代码内部执行这种循环. 这是通过添加一个与窗口大小相同的额外尺寸和适当的步幅来实现的. import numpy as np data = np.arange(20) def rolling_window(a, window): shape = a.shape[:-1] + (a.shape[-1] - window + 1, window) strides = a.strides +
-
python 实现rolling和apply函数的向下取值操作
我就废话不多说了,大家还是直接看代码吧! import pandas as pd def get_under_rolling(df,window,user,name): df[name] = df[user].iloc[::-1].rolling(window=window).apply(lambda x:x[0]).iloc[::-1] return df if __name__ == '__main__': df = pd.DataFrame({'a':[1,2,3,4,5], 'b':[2
-
python shell命令行中import多层目录下的模块操作
首先在文件夹中添加_init_.py文件,即使是空文件也可以,多层文件夹,每层文件夹中都要添加. 比如我要import,a文件夹中,b文件夹下的 c.py 我就需要在a,b文件夹中都添加_init_.py文件. 然后引入方式:import a.b.c 然后在调用c.py的函数时,直接c.f()是不行的,需要a.b.c.f(). 当然也可以先写 c = a.b.c,然后再c.f(). 补充知识:Python IDLE shell中引入模块 安装了Python之后,会自带一个Python IDLE,
-

python 中dict的元素取值操作
如下所示: dict.get(key, default=None) key – 字典中要查找的键. default – 如果指定键的值不存在时,返回该默认值值. {'1*': 9, '2*': 6, '**': 15}.values() Out[377]: dict_values([9, 6, 15]) {'1*': 9, '2*': 6, '**': 15}.keys() Out[378]: dict_keys(['1*', '2*', '**']) {'1*': 9, '2*': 6, '*
-
python列表切片和嵌套列表取值操作详解
给出列表切片的格式: [开头元素::步长] # 输出直到最后一个元素,(最后一个冒号和步长可以省略,下同) [开头元素:结尾元素(不含):步长] # 其中,-1表示list最后一个元素 首先来看最简单的单一列表: a = [1,2,3,4] a[:] a[::] a[:3] a[1:3:2] a[3] 输出依次为: [1,2,3,4] [1,2,3,4] [1,2,3] [2] 4 注意,这里只有最后一个输出是不带[]的,表明只有最后一个输出是元素,其他在切片中只用了:符号的输出均为list,不
-
Python自动打印被调用函数变量名及对应值
目录 1.软件环境 2.问题描述 3.解决方法 4.结果预览 1.软件环境 Windows10 教育版64位Python 3.6.3 2.问题描述 我们在定义一个函数或者是调用一个函数的时候,总是希望能够知道传入该被调用函数的具体值是多少?是否符合我们的预期?因此我们往往会将我们关心的值给打印出来(当然debug也可以,但不能每次都debug吧?),如下,我们创建了一个initial_printer示例函数: def initial_printer(variable_a, variable_b,
-
对pandas中apply函数的用法详解
最近在使用apply函数,总结一下用法. apply函数可以对DataFrame对象进行操作,既可以作用于一行或者一列的元素,也可以作用于单个元素. 例:列元素 行元素 列 行 以上这篇对pandas中apply函数的用法详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们. 您可能感兴趣的文章: 浅谈Pandas中map, applymap and apply的区别
-
JavaScript学习笔记之取值函数getter与取值函数setter详解
目录 取值函数getter和存值函数setter 使用get与set函数有两个好处 取值函数getter和存值函数setter get和set是两个关键字,用于对某个属性设置存值函数和取值函数,拦截该属性的存取行为. 那么,这两个东西要怎么用呢?而且他们和我们的平日里写的业务又是怎么练习起来的呢? 首先,我们先看一段恩简单的代码: var person={ myname:'' } person.myname='lsh' console.log(person.myname); 相信大家一眼就看出来
-
python中apply函数详情
函数原型: DataFrame.apply(func, axis=0, broadcast=False, raw=False, reduce=None, args=(), **kwds) 1.该函数最有用的是第一个参数,这个参数是函数,相当于C/C++的函数指针. 2.这个函数需要自己实现,函数的传入参数根据axis来定,比如axis = 1,就会把一行数据作为Series的数据 结构传入给自己实现的函数中,我们在函数中实现对Series不同属性之间的计算,返回一个结果,则apply函数 会自动
-
python中multiprosessing模块的Pool类中的apply函数和apply_async函数的区别
目录 1.二者的区别 2.apply() 3.apply_async() 1.二者的区别 apply(): 非异步(子进程不是同时执行的),堵塞主进程. 它的非异步体现在:一个一个按顺序执行子进程, 子进程不是同时执行的. 它的堵塞体现在:等到全部子进程都执行完毕后,继续执行apply()后面主进程的代码. apply_async(): 异步的,不堵塞主进程. 它的异步体现在:子进程之间是同时执行的.子进程被分配到不同的cpu上被执行. 它的非堵塞体现在:他不会等待子进程完全执行完毕, 主进程