MySQL分库分表的几种方式
目录
- 一、为什么要分库分表
- 二、什么是分库分表
- 三、分库分表的几种方式
- 1.垂直拆分
- 2. 水平拆分
- 四、分库分表带来的问题
- 五、分库分表技术如何选型

一、为什么要分库分表
如果一个网站业务快速发展,那这个网站流量也会增加,数据的压力也会随之而来,比如电商系统来说双十一大促对订单数据压力很大,Tps十几万并发量,如果传统的架构(一主多从),主库容量肯定无法满足这么高的Tps,业务越来越大,单表数据超出了数据库支持的容量,持久化磁盘IO,传统的数据库性能瓶颈,产品经理业务·必须做,改变程序,数据库刀子切分优化。数据库连接数不够需要分库,表的数据量大,优化后查询性能还是很低,需要分。
二、什么是分库分表
- 分库分表方案是对关系型数据库数据存储和访问机制的一种补充。
- 分库:将一个库的数据拆分到多个相同的库中,访问的时候访问一个库
- 分表:把一个表的数据放到多个表中,操作对应的某个表就行
三、分库分表的几种方式
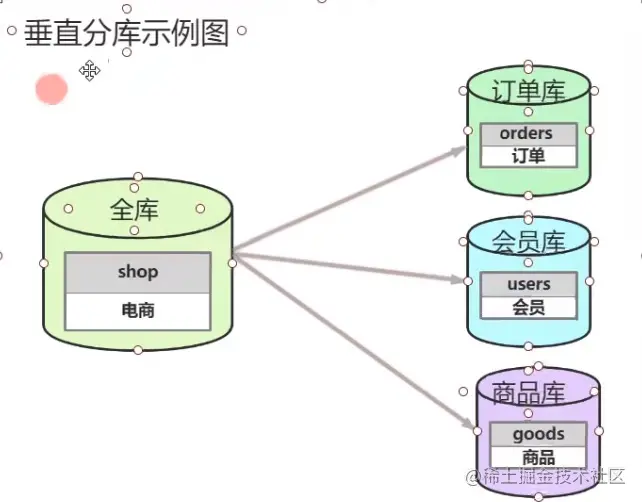
1.垂直拆分
(1) 数据库垂直拆分

根据业务拆分,如图,电商系统,拆分成订单库,会员库,商品库
(2)表垂直拆分

根据业务去拆分表,如图,把user表拆分成user_base表和user_info表,use_base负责存储登录,user_info负责存储基本用户信息
垂直拆分特点:
- 每个库(表)的结构都不一样
- 每个库(表)的数据至少一列一样
- 每个库(表)的并集是全量数据
垂直拆分优缺点
优点:
- 拆分后业务清晰(专库专用按业务拆分)
- 数据维护简单,按业务不同,业务放到不同机器上
缺点:
- 如果单表的数据量,写读压力大
- 受某种业务决定,或者被限制,也就是说一个业务往往会影响到数据库的瓶颈(性能问题,如双十一抢购)
- 部分业务无法关联join,只能通过java程序接口去调用,提高了开发复杂度
2. 水平拆分
(1) 数据库水平拆分

如图,按会员库拆分,拆分成会员1库,会员2库,以userId拆分,userId尾号0-5为1库 6-9为2库,还有其他方式,进行取模,偶数放到1库,奇数放到2库
(2) 表水平拆分

如图把users表拆分成users1表和users2表,以userId拆分,进行取模,偶数放到users1表,奇数放到users2表
水平拆分的其他方式:
- range来分,每个库一段连续的数据,这个一般是按比如时间范围来的,但是这种一般较少用,因为很容易产生热点问题,大量的流量都打在最新的数据上了,优点:扩容的时候,就很容易,因为你只要预备好,给每个月都准备一个库就可以了,到了一个新的月份的时候,自然而然,就会写新的库了 缺点:大部分的 请求,都是访问最新的数据。实际生产用range,要看场景,你的用户不是仅仅访问最新的数据,而是均匀的访问现在的数据以及历史的数据
- hash分发,优点:可以平均分配每个库的数据量和请求压力 缺点:扩容起来比较麻烦,会有一个数据迁移的这么一个过程
(3) 水平拆分特点
- 每个库(表)的结构都一样
- 每个库(表)的数据都不一样
- 每个库(表)的并集是全量数据
(4) 水平拆分优缺点
优点:
- 单库/单表的数据保持在一定量(减少),有助于性能提高
- 提高了系统的稳定性和负载能力
- 拆分表的结构相同,程序改造较少。
缺点:
- 数据的扩容很有难度维护量大
- 拆分规则很难抽象出来
- 分片事务的一致性问题部分业务无法关联join,只能通过java程序接口去调用
四、分库分表带来的问题
- 分布式事务
- 跨库join查询
- 分布式全局唯一id
- 开发成本 对程序员要求高
五、分库分表技术如何选型
(1) 分库分表的开源框架
- jdbc 直连层:shardingsphere、tddl
- proxy 代理层:mycat,mysql-proxy(360)
jdbc直连层
jdbc直连层又叫jdbc应用层,是因为所有分片规则,所有分片逻辑,包括处理分布式事务 所有这些问题它都是在应用层,所有项目都是由war包构成的,所有分片都写成了jar包,放到了war包里面,java需要虚拟机去运行的,虚拟机运行的时候就会把war包里面的字节文件进行classLoder加载到jvm内存中,所有分片逻辑都是基于内存方进行操作的
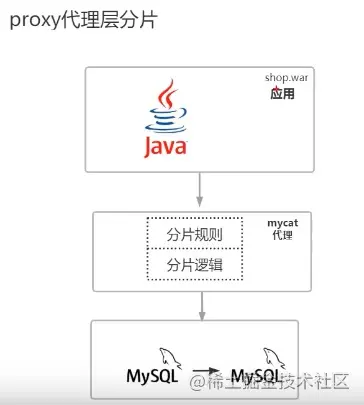
(2) proxy代理层

如图,proxy代理层,所有分片规则,所有分片逻辑,包括处理分布式事务都在mycat写好了,所有分片逻辑都是基于mycat方进行操作
(3) jdbc直连层和proxy代理层优缺点
- jdbc直连层性能高,只支持java语言,支持跨数据库
- proxy代理层开发成本低,支持跨语言,不支持跨数据库
到此这篇关于MySQL分库分表的几种方式的文章就介绍到这了,更多相关MySQL分库分表内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

MySQL分库分表与分区的入门指南
前言 关系型数据库比较容易成为系统瓶颈,单机存储容量.连接数.处理能力都有限,当数据量和并发量起来之后,就必须对数据库进行切分了. 数据切分(sharding)的手段就是分库分表.分库分表有两方面,可能是光分库不分表,也可能是光分表不分库. 数据库分布式的核心内容无非就是数据切分,以及切分后对数据的定位.整合. 为什么要分库分表 分表 单表数据量太大时,会严重影响sql执行的性能.一般单表到达几百万的时候,性能就会相对差一些了,这时就得分表了. 分表就是把一个表的数据放到多个表中,然后查询的时候
-
Mysql分库分表之后主键处理的几种方法
目录 数据库自增 ID 设置数据库 sequence 或者表自增字段步长 UUID 系统当前时间戳+XXX Snowflake 算法 数据库自增 ID 搞一个数据库,什么也不干,就用于生成主键. 你的系统里每次得到一个 id,都需要往那个专门生成主键的数据库中通过插入获取一个自增的ID,拿到这个 id 之后再往对应的分库分表里去写入. 优点:方便简单. 缺点:单库生成自增 id,要是高并发的话,就会有瓶颈的:如果你硬是要改进一下,那么就专门开一个服务出来,这个服务每次就拿到当前 id 最大值,然
-
SpringBoot+MybatisPlus+Mysql+Sharding-JDBC分库分表
目录 一.序言 1.组件及版本选择 2.预期目标 二.代码实现 (一)素材准备 1.实体类 2.Mapper类 3.全局配置文件 (二)增删查改 1.保存数据 2.查询列表数据 3.分页查询数据 4.查询详情 5.删除数据 6.修改数据 三.理论分析 1.选择分片列 2.扩容 一.序言 在实际业务中,单表数据增长较快,很容易达到数据瓶颈,比如单表百万级别数据量.当数据量继续增长时,数据的查询性能即使有索引的帮助下也不尽如意,这时可以引入数据分库分表技术. 本文将基于SpringBoot+Myba
-
Mysql数据库分库分表全面瓦解
目录 1 为什么要分库分表 2 垂直拆分(Scale Up 纵向扩展) 2.1 垂直分库 2.2 垂直分表 3 水平拆分(Scale Out 横向扩展) 3.1 库内分表 3.2 库内分表的实现策略 3.2.1 HASH(哈希) 3.2.2 RANGE(范围) 3.2.3 LIST(预定义列表) 3.2.4 KEY(键值) 3.2.5 Composite(复合模式) 3.3 分库分表 4 分库分表存在的问题 4.1 事务问题 4.2 跨库跨表的join问题 4.3 额外的数据管理负担和数据运算压
-
MySQL分库分表详情
一.业务场景介绍 假设目前有一个电商系统使用的是MySQL,要设计大数据量存储.高并发.高性能可扩展的方案,数据库中有用户表.用户会非常多,并且要实现高扩展性,你会怎么去设计? OK咱们先看传统的分库分表方式 当然还有些小伙伴知道按照省份/地区或一定的业务关系进行数据库拆分 OK,问题来了,如何保证合理的让数据存储在不同的库不同的表里呢?让库减少并发压力?应该怎么去制定分库分表的规则?不用急,这不就来了 二.水平分库分表方法 1.RANGE 第一种方法们可以指定一个数据范围来进行分表,例如从1~
-
MySQL常用分库分表方案汇总
目录 一.数据库瓶颈 二.分库分表 2.水平分表 3.垂直分库 4.垂直分表 三.分库分表工具 四.分库分表步骤 五.分库分表问题 1.非partition key的查询问题 2.非partition key跨库跨表分页查询问题 3.扩容问题 六.分库分表总结 一.数据库瓶颈 不管是IO瓶颈,还是CPU瓶颈,最终都会导致数据库的活跃连接数增加,进而逼近甚至达到数据库可承载活跃连接数的阈值.在业务Service来看就是,可用数据库连接少甚至无连接可用.接下来就可以想象了吧(并发量.吞吐量.崩溃).
-
浅谈订单重构之 MySQL 分库分表实战篇
目录 一.目标 二.环境准备 1.基本信息 2.数据库环境准备 3.建库 & 导入分表 三.配置&实践 1.pom文件 2.常量配置 3.yml 配置 4.分库分表策略 5.dao层编写 6.单元测试 四.总结 一.目标 本文将完成如下目标: 分表数量: 256 分库数量: 4 以用户ID(user_id) 为数据库分片Key 最后测试订单创建,更新,删除, 单订单号查询,根据user_id查询列表操作. 架构图: 表结构如下: CREATE TABLE `order_XXX` (
-
MySQL分库分表的几种方式
目录 一.为什么要分库分表 二.什么是分库分表 三.分库分表的几种方式 1.垂直拆分 2. 水平拆分 四.分库分表带来的问题 五.分库分表技术如何选型 一.为什么要分库分表 如果一个网站业务快速发展,那这个网站流量也会增加,数据的压力也会随之而来,比如电商系统来说双十一大促对订单数据压力很大,Tps十几万并发量,如果传统的架构(一主多从),主库容量肯定无法满足这么高的Tps,业务越来越大,单表数据超出了数据库支持的容量,持久化磁盘IO,传统的数据库性能瓶颈,产品经理业务·必须做,改变程序,数据库
-
MySQL 分库分表的项目实践
目录 一.为什么要分库分表 二.库表太大产生的问题 三.垂直拆分 1. 垂直分库 2. 垂直分表 四.水平分库分表 一.为什么要分库分表 数据库架构演变 刚开始多数项目用单机数据库就够了,随着服务器流量越来越大,面对的请求也越来越多,我们做了数据库读写分离, 使用多个从库副本(Slave)负责读,使用主库(Master)负责写,master和slave通过主从复制实现数据同步更新,保持数据一致.slave 从库可以水平扩展,所以更多的读请求不成问题 但是当用户量级上升,写请求越来越多,怎么保证数
-
MySQL分库分表后路由策略设计详情
目录 概述 支持场景 路由策略 用户端路由key 商家路由key 概述 分库分表后设计到的第一个问题就是,如何选择路由key,应该如何对key进行路由.路由key应该在每个表中都存在而且唯一.路由策略应尽量保证数据能均匀进行分布. 如果是对大数据量进行归档类的业务可以选择时间作为路由key.比如按数据的创建时间作为路由key,每个月或者每个季度创建一个表.按时间作为分库分表后的路由策略可以做到数据归档,历史数据访问流量较小,流量都会打到最新的数据库表中. 也可以设计其与业务相关的路由key.这样
-
MySQL分库分表总结讲解
项目开发中,我们的数据库数据越来越大,随之而来的是单个表中数据太多.以至于查询变慢,而且由于表的锁机制导致应用操作也受到严重影响,出现了数据库性能瓶颈. 当出现这种情况时,我们可以考虑分库分表,即将单个数据库或表进行拆分,拆分成多个库和多个数据表,然后用户访问的时候,根据一定的算法与逻辑,让用户访问不同的库.不同的表,这样数据分散到多个数据表中,减少了单个数据表的访问压力.提升了数据库访问性能. 下面是对项目中分库分表的一些总结: 单库单表 单库单表是最常见的数据库设计,例如,有一张用户(use
-
mysql数据库分表分库的策略
一.先说一下为什么要分表: 当一张的数据达到几百万时,你查询一次所花的时间会变多,如果有联合查询的话,有可能会死在那儿了.分表的目的就在于此,减小数据库的负担,缩短查询时间.日常开发中我们经常会遇到大表的情况,所谓的大表是指存储了百万级乃至千万级条记录的表.这样的表过于庞大,导致数据库在查询和插入的时候耗时太长,性能低下,如果涉及联合查询的情况,性能会更加糟糕.分表和表分区的目的就是减少数据库的负担,提高数据库的效率,通常点来讲就是提高表的增删改查效率.数据库中的数据量不一定是可控的,在未进行分