基于ASP.NET的lucene.net全文搜索实现步骤
在做项目的时候,需求添加全文搜索,选择了lucene.net方向,调研了一下,基本实现了需求,现在将它分享给大家。理解不深请多多包涵。
在完成需求的时候,查看的大量的资料,本文不介绍详细的lucene.net工程建立,只介绍如何对文档进行全文搜索。对于如何建立lucene.net的工程请大家访问
使用lucene.net搜索分为两个部分,首先是创建索引,创建文本内容的索引,其次是根据创建的索引进行搜索。那么如何对文档进行索引呢,主要是对文档的内容进行索引,关键是提取出文档的内容,按照常规实现,由简到难,提取txt格式的文本相对比较简单,如果实现了提取txt文本,接下来就容易多了,万丈高楼平地起,这就是地基。
1.首先创建ASP.NET页面。

这是一个极其简单的页面,创建页面之后,双击各个按钮生成相应的点击事件,在相应的点击事件中实现程序设计。
2.实现索引部分。
前面已经说到了,索引主要是根据文本内容建立索引,所以要提取文本内容。创建提取txt格式文档文本内容的函数。
代码如下:
//提取txt文件
public static string FileReaderAll(FileInfo fileName)
{
//读取文本内容,并且默认编码格式,防止出现乱码
StreamReader reader = new StreamReader(fileName.FullName, System.Text.Encoding.Default);
string line = "";
string temp = "";
//循环读取文本内容
while ((line = reader.ReadLine()) != null)
{
temp += line;
}
reader.Close();
//返回字符串,用于lucene.net生成索引
return temp;
}
文本内容已经提取出来了,接下来要根据提取的内容建立索引
代码如下:
protected void Button2_Click(object sender, EventArgs e)
{
//判断存放文本的文件夹是否存在
if (!System.IO.Directory.Exists(filesDirectory))
{
Response.Write("<script>alert('指定的目录不存在');</script>");
return;
}
//读取文件夹内容
DirectoryInfo dirInfo = new DirectoryInfo(filesDirectory);
FileInfo[] files = dirInfo.GetFiles("*.*");
//文件夹判空
if (files.Count() == 0)
{
Response.Write("<script>alert('Files目录下没有文件');</script>");
return;
}
//判断存放索引的文件夹是否存在,不存在创建
if (!System.IO.Directory.Exists(indexDirectory))
{
System.IO.Directory.CreateDirectory(indexDirectory);
}
//创建索引
IndexWriter writer = new IndexWriter(FSDirectory.Open(new DirectoryInfo(indexDirectory)),
analyzer, true, IndexWriter.MaxFieldLength.LIMITED);
for (int i = 0; i < files.Count(); i++)
{
string str = "";
FileInfo fileInfo = files[i];
//判断文件格式,为以后其他文件格式做准备
if (fileInfo.FullName.EndsWith(".txt") || fileInfo.FullName.EndsWith(".xml"))
{
//获取文本
str = FileReaderAll(fileInfo);
}
Lucene.Net.Documents.Document doc = new Lucene.Net.Documents.Document();
doc.Add(new Lucene.Net.Documents.Field("FileName", fileInfo.Name, Lucene.Net.Documents.Field.Store.YES, Lucene.Net.Documents.Field.Index.ANALYZED));
//根据文本生成索引
doc.Add(new Lucene.Net.Documents.Field("Content", str, Lucene.Net.Documents.Field.Store.YES, Lucene.Net.Documents.Field.Index.ANALYZED));
doc.Add(new Lucene.Net.Documents.Field("Path", fileInfo.FullName, Lucene.Net.Documents.Field.Store.YES, Lucene.Net.Documents.Field.Index.NO));
//添加生成的索引
writer.AddDocument(doc);
writer.Optimize();
}
writer.Dispose();
Response.Write("<script>alert('索引创建成功');</script>");
}
3.索引创建完了,接下来就是搜索,搜索只要按照固定的格式书写不会出现错误。
代码如下:
protected void Button1_Click(object sender, EventArgs e)
{
//获取关键字
string keyword = TextBox1.Text.Trim();
int num = 10;
//关键字判空
if (string.IsNullOrEmpty(keyword))
{
Response.Write("<script>alert('请输入要查找的关键字');</script>");
return;
}
IndexReader reader = null;
IndexSearcher searcher = null;
try
{
reader = IndexReader.Open(FSDirectory.Open(new DirectoryInfo(indexDirectory)), true);
searcher = new IndexSearcher(reader);
//创建查询
PerFieldAnalyzerWrapper wrapper = new PerFieldAnalyzerWrapper(analyzer);
wrapper.AddAnalyzer("FileName", analyzer);
wrapper.AddAnalyzer("Path", analyzer);
wrapper.AddAnalyzer("Content", analyzer);
string[] fields = { "FileName", "Path", "Content" };
QueryParser parser = new MultiFieldQueryParser(Lucene.Net.Util.Version.LUCENE_30, fields, wrapper);
//根据关键字查询
Query query = parser.Parse(keyword);
TopScoreDocCollector collector = TopScoreDocCollector.Create(num, true);
searcher.Search(query, collector);
//这里会根据权重排名查询顺序
var hits = collector.TopDocs().ScoreDocs;
int numTotalHits = collector.TotalHits;
//以后就可以对获取到的collector数据进行操作
for (int i = 0; i < hits.Count(); i++)
{
var hit = hits[i];
Lucene.Net.Documents.Document doc = searcher.Doc(hit.Doc);
Lucene.Net.Documents.Field fileNameField = doc.GetField("FileName");
Lucene.Net.Documents.Field pathField = doc.GetField("Path");
Lucene.Net.Documents.Field contentField = doc.GetField("Content");
//在页面循环输出表格
strTable.Append("<tr>");
strTable.Append("<td>" + fileNameField.StringValue + "</td>");
strTable.Append("</tr>");
strTable.Append("<tr>");
strTable.Append("<td>" + pathField.StringValue + "</td>");
strTable.Append("</tr>");
strTable.Append("<tr>");
strTable.Append("<td>" + contentField.StringValue.Substring(0, 300) + "</td>");
strTable.Append("</tr>");
}
}
finally
{
if (searcher != null)
searcher.Dispose();
if (reader != null)
reader.Dispose();
}
}
现在整个lucene.net搜索全文的过程就建立完了,现在可以搜索txt格式的文件,搜索其他格式的文件在以后添加,主要核心思想就是提取各个不同格式文件的文本内容。
显示效果如下:
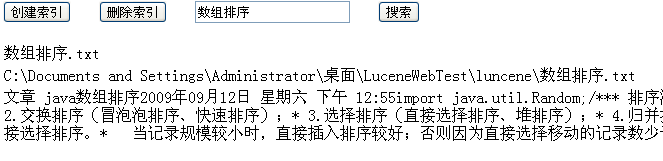
在以后的博文里继续接受搜索其他格式的文档。
相关推荐
-

使用Lucene实现一个简单的布尔搜索功能
什么是lucene Lucene是apache软件基金会jakarta项目组的一个子项目,是一个开放源代码的全文检索引擎工具包,但它不是一个完整的全文检索引擎,而是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎(英文与德文两种西方语言). Lucene是一个全文搜索框架,而不是应用产品.因此它并不像www.baidu.com 或者google Desktop那么拿来就能用,它只是提供了一种工具让你能实现这些产品. 在布尔查询的对象中,包含一个子句的集合,各个子句间都是如
-
使用Lucene.NET实现站内搜索
导入Lucene.NET 开发包 Lucene 是apache软件基金会一个开放源代码的全文检索引擎工具包,是一个全文检索引擎的架构,提供了完整的查询引擎和索引引擎,部分文本分析引擎.Lucene的目的是为软件开发人员提供一个简单易用的工具包,以方便的在目标系统中实现全文检索的功能,或者是以此为基础建立起完整的全文检索引擎.Lucene.Net 是 .NET 版的Lucene. 你可以在这里下载到最新的Lucene.NET 创建索引.更新索引.删除索引 搜索,根据索引查找 IndexHelper
-
Lucene.Net实现搜索结果分类统计功能(中小型网站)
最近我们搜易站内搜索系统的一个客户需要一个无限级分类和分类统计功能,要实现的效果如下: 但由于搜易站内搜索系统是基于Lucene.net 2.0开发的,并没有内置的分类统计搜索功能,于是乎只能自己实现了,考虑到客户的总数据量和搜索量不是特别大,于是用了简单有效的方式来实现: 因为涉及到分类的操作,但是每个站点的分类体系还是有些不一样的,本文主要提供思路和部分演示代码,给有需要的童鞋参考: 思路: 首先想到Lucene搜索出来的结果是一个Hits对象,Hits其实就是一个搜索结果文档的集合对象,那
-
使用Java的Lucene搜索工具对检索结果进行分组和分页
使用GroupingSearch对搜索结果进行分组 Package org.apache.lucene.search.grouping Description 这个模块可以对Lucene的搜索结果进行分组,指定的单值域被聚集到一起.比如,根据"author"域进行分组,"author"域值相同的的文档分成一个组. 进行分组的时候需要输入一些必要的信息: 1.groupField:根据这个域进行分组.比如,如果你使用"author"域进行分组,那么
-
Java实现lucene搜索功能的方法(推荐)
直接上代码: package com.sand.mpa.sousuo; import java.io.BufferedReader; import java.io.File; import java.io.FileReader; import java.io.FileWriter; import java.io.IOException; import java.io.PrintWriter; import java.sql.Connection; import java.sql.DriverMa
-
基于Lucene的Java搜索服务器Elasticsearch安装使用教程
一.安装Elasticsearch Elasticsearch下载地址:http://www.elasticsearch.org/download/ ·下载后直接解压,进入目录下的bin,在cmd下运行elasticsearch.bat 即可启动Elasticsearch ·用浏览器访问: http://localhost:9200/ ,如果出现类似如下结果则说明安装成功: { "name" : "Benedict Kine", "cluster_na
-
基于ASP.NET的lucene.net全文搜索实现步骤
在做项目的时候,需求添加全文搜索,选择了lucene.net方向,调研了一下,基本实现了需求,现在将它分享给大家.理解不深请多多包涵. 在完成需求的时候,查看的大量的资料,本文不介绍详细的lucene.net工程建立,只介绍如何对文档进行全文搜索.对于如何建立lucene.net的工程请大家访问 使用lucene.net搜索分为两个部分,首先是创建索引,创建文本内容的索引,其次是根据创建的索引进行搜索.那么如何对文档进行索引呢,主要是对文档的内容进行索引,关键是提取出文档的内容,按照常规实现,由
-
详细讲解PostgreSQL中的全文搜索的用法
开发Web应用时,你经常要加上搜索功能.甚至还不知能要搜什么,就在草图上画了一个放大镜. 搜索是项非常重要的功能,所以像elasticsearch和SOLR这样的基于lucene的工具变得很流行.它们都很棒.但使用这些大规模"杀伤性"的搜索武器前,你可能需要来点轻量级的,但又足够好的搜索工具. 所谓"足够好",我是指一个搜索引擎拥有下列的功能: 词根(Stemming) 排名/提升(Ranking / Boost) 支持多种语言 对拼写错误模糊搜索 方言的支持 幸运
-
PHP在innodb引擎下快速代建全文搜索功能简明教程【基于xunsearch】
本文实例讲述了PHP在innodb引擎下快速代建全文搜索功能的方法.分享给大家供大家参考,具体如下: 需要准备的设备:Liunx(Centos)操作系统(只支持Linux),PHP环境. 这里介绍一个国人开发的搜索引擎开源项目-讯搜(xunsearch),它分为:索引服务器和搜索服务器. 在CentOS下面愉快的代建服务器 wget http://www.xunsearch.com/download/xunsearch-full-latest.tar.bz2 tar -xjf xunsearch
-
对JavaScript的全文搜索实现相关度评分的功能的方法
全文搜索,与机器学习领域其他大多数问题不同,是一个 Web 程序员在日常工作中经常遇到的问题.客户可能要求你在某个地方提供一个搜索框,然后你会写一个类似 WHERE title LIKE %:query% 的 SQL 语句实现搜索功能.一开始,这是没问题,直到有一天,客户找到你跟你说,"搜索出错啦!" 当然,实际上搜索并没有"出错",只是搜索的结果并不是客户想要的.一般的用户并不清楚如何做精确匹配,所以得到的搜索结果质量很差.为了解决问题,你决定使用全文搜索.经过一
-
mysql 全文搜索 技巧
<< Back to man.ChinaUnix.net MySQL Reference Manual for version 4.1.0-alpha. -------------------------------------------------------------------------------- 6.8 MySQL 全文搜索 到 3.23.23 时,MySQL 开始支持全文索引和搜索.全文索引在 MySQL 中是一个 FULLTEXT 类型索引.FULLTEXT 索引用于 M
-
基于jQueryUI和Corethink实现百度的搜索提示功能
先给大家展示下效果图: 目录: 这里是以corethink模块的形式,只需要安装上访问 index.php?s=/test/index 1.建好模块目录,写好模块的总体文件 opencmf.PHP <?php return array( // 模块信息 'info' => array( 'name' => 'Test', 'title' => 'Test', 'icon' => 'fa fa-newspaper-o', 'icon_color' => '#9933FF'
-
SQL Server 全文搜索功能介绍
SQL Server 的全文搜索(Full-Text Search)是基于分词的文本检索功能,依赖于全文索引.全文索引不同于传统的平衡树(B-Tree)索引和列存储索引,它是由数据表构成的,称作倒转索引(Invert Index),存储分词和行的唯一键的映射关系.倒转索引是在创建全文索引或更新全文索引时,由SQL Server自动创建和维护的.全文索引主要包含三种分析器:分词器(Word Breaker).词干分析器(stemmer)和同义词分析器.全文索引中存储的数据是分词及其位置等信息,分词
-
Python实现中英文全文搜索的示例
文章版权所有:州的先生博客 原文地址:https://zmister.com/archives/1596.html 在互联网上的各类网站中,无论大小,基本上都会有一个搜索框,用来给用户对内容进行搜索,小到站点搜索,大到搜索引擎搜索. 从简单的来说,搜索功能确实很简单,一个简单的 select 语句就可以实现数据的搜索. 而从复杂的来看,无论是搜索的精度还是搜索的效率,都是有很深的研究范围的. 对于简单的搜索功能来说,一个 select 查询语句也足够使用,但在稍微复杂一点的搜索环境下,比如网页.
-
基于ASP.NET实现验证码生成详解
作业:验证码 要求: (1)验证码应该是图片格式,不能是文字格式,即无法用鼠标选中. (2)验证码上应该有噪点和干扰线条. (3)验证码应该回避相似字符,如“0”和“o”“I”和“1”等. (4)验证码至少是数字和字母(含大小写)的组合,不应该是单纯的数字或字母,可以出现汉字.应该实现输入验证码字母字母“不区分大小写”.验证码中的内容,应该是随机生成. (5)验证码,可以通过点击图片或旁边文字实现“看不清,换一张”的功能. (6)应当有个用于核对验证码输入是否正确的tbx和btn,当点击btn时