Linux共享内存实现机制的详解
Linux共享内存实现机制的详解
内存共享: 两个不同进程A、B共享内存的意思是,同一块物理内存被映射到进程A、B各自的进程地址空间。进程A可以即时看到进程B对共享内存中数据的更新,反之亦然。由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以。

效率: 采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝。对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据[1]: 一次从输入文件到共享内存区,另一次从共享内存区到输出文件。实际上,进程之间在共享内存时,并不总是读写少量数据后就解除映射,有新的通信时,再重新建 立共享内存区域。而是保持共享区域,直到通信完毕为止,这样,数据内容一直保存在共享内存中,并没有写回文件。共享内存中的内容往往是在解除映射时才写回 文件的。因此,采用共享内存的通信方式效率是非常高的。
共享内存实现机制
共享内存是通过把同一块内存分别映射到不同的进程空间中实现进程间通信。而共享内存本身不带任何互斥与同步机制,但当多个进程同时对同一内存进行读写操作时会破坏该内存的内容,所以,在实际中,同步与互斥机制需要用户来完成。
来看几个系统调用函数:
(1)创建共享内存

参数:key为输出型参数
size:size的大小应为1024整数倍(4k对齐)
shmflg:权限标志
(2)将共享内存映射到自己的内存空间:shmat
shmat是空间映射,通过创建的共享内存,在它能被进程访问之前,需要把该段内存映射到用户进程空间。shmaddr是用来指定共享内存映射到当前进程中的地址位置,要想改设置有用,shmflag必须设置为SHM_RND标志。大多情况下,应设置为空指针(void*)0,让系统自动选择地址,从而减小程序对硬件的依赖性。shmflag除了上面的设置外,还可以设置为SHM_RDONLY,使得映射过来的地址只读。
返回值:调用成功则返回映射地址的第一个字节,失败返回-1。
(3)解除映射:shmdt
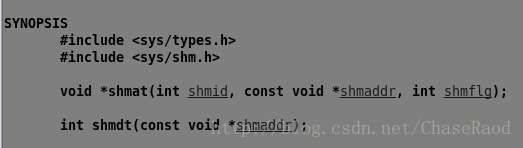
参数为要解除的地址空间。
(4)控制共享内存
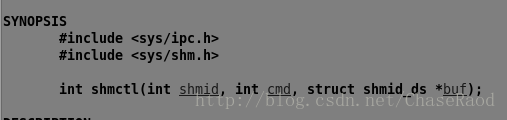
先来看第三个参数的结构体:
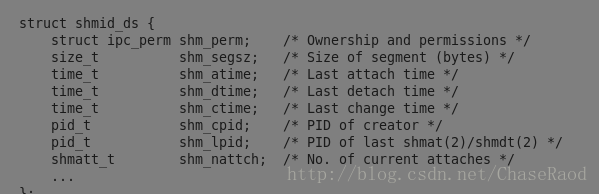

第二个参数cmd的选项:IPC_STAT:得到共享内存的状态,把共享内存的shmid_ds结构体复制到buf里
IPC_SET:改变共享内存的状态,把buf所指的结构体中的uid,gid,mode,复制到共享内存的shmid_ds结构体内
IPC_RMID:删除这块共享内存
BUF:共此内存管理结构体
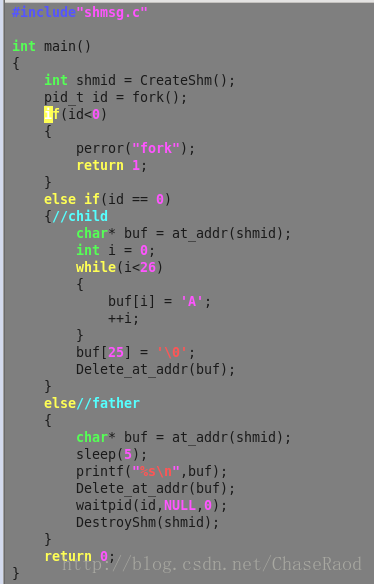
代码实现:


共享内存的特点:
(1)共享内存就是允许两个不想关的进程访问同一个内存
(2)共享内存是两个正在运行的进程之间共享和传递数据的最有效的方式
(3)不同进程之间共享的内存通常安排为同一段物理内存
(4)共享内存不提供任何互斥和同步机制,一般用信号量对临界资源进行保护。
(5)接口简单
所有进程间通信的特点:
(1)管道
管道分为命名管道和匿名管道。匿名管道只能单向通信,且只能在有亲缘关系的进程间使用,常用于父子进程,当一个进程创建了一个管道,并调用fork创建子进程后,父进程关闭读端,子进程关闭写端,实现单向通信。管道是面向字节流,自带互斥与同步机制,生命周期随进程。
命名管道与匿名管道:命名管道允许毫不相干的两个进程之间
(2)信号量
信号量是一个计数器,可以用来控制多个线程对共享资源的访问,它不是用于交换大批数据,而用于多线程之间的同步,常作为一种锁机制,防止某进程在访问资源时其他进程也来访问,因此,主要作为进程间以及同一进程的不同线程间的同步手段。
(3)消息队列
消息队列是消息的链表,存放在内核中并由消息队列标识符标识,消息队列克服了信号传递信息少,管道只能承载无格式字节流以及缓冲区受限等特点。消息队列是UNIX下不同进程之间可以实现资源共享的 一种机制,UNIX允许不同进程将格式化的数据流以消息队列形式发送给任意进程,对消息队列具有操作权限的进程都可以使用msgget完成对消息队列的操作控制,通过使用消息类型,进程可以按顺序读信息,或为消息安排优先级顺序。
(4)共享内存
共享内存就是映射一段能被其他进程所访问的内存,这段共享内存由一个进程创建,但多个进程都可以访问,共享内存是最快的IPC方式,它是针对其他IPC方式运行效率低而专门设计的,它往往与其他机制,如信号量,配合使用,来实现进程间的同步。
以上就是Linux共享内存实现机制的内容详细介绍,大家可以参考下,如果有疑问的可以到本站留言,进行讨论。感谢阅读,希望能帮助到大家,谢谢大家对本站的支持!
相关推荐
-

详解Linux进程间通信——使用共享内存
一.什么是共享内存 顾名思义,共享内存就是允许两个不相关的进程访问同一个逻辑内存.共享内存是在两个正在运行的进程之间共享和传递数据的一种非常有效的方式.不同进程之间共享的内存通常安排为同一段物理内存.进程可以将同一段共享内存连接到它们自己的地址空间中,所有进程都可以访问共享内存中的地址,就好像它们是由用C语言函数malloc分配的内存一样.而如果某个进程向共享内存写入数据,所做的改动将立即影响到可以访问同一段共享内存的任何其他进程. 特别提醒:共享内存并未提供同步机制,也就是说,在第一个进程结束
-
linux 共享内存
概述 如果想在Apache/EAPI中具有共享内存的支持,那么就要建立MM共享内存库.在这种情况下,它将允许mod_ssl使用一种高效的基于RAM的会话(session)缓存代替基于磁盘的会话缓存. 注意事项 下面所有的命令都是Unix兼容的命令. 源路径都为"/var/tmp"(当然在实际情况中也可以用其它路径). 安装在RedHat Linux 6.1下测试通过. 要用"root"用户进行安装. Mm 的版本号是1.0.12. 软件包的来源 MM的主页: 必须确
-
Linux共享内存实现机制的详解
Linux共享内存实现机制的详解 内存共享: 两个不同进程A.B共享内存的意思是,同一块物理内存被映射到进程A.B各自的进程地址空间.进程A可以即时看到进程B对共享内存中数据的更新,反之亦然.由于多个进程共享同一块内存区域,必然需要某种同步机制,互斥锁和信号量都可以. 效率: 采用共享内存通信的一个显而易见的好处是效率高,因为进程可以直接读写内存,而不需要任何数据的拷贝.对于像管道和消息队列等通信方式,则需要在内核和用户空间进行四次的数据拷贝,而共享内存则只拷贝两次数据[1]: 一次从输入文件到
-
python内存管理机制原理详解
python内存管理机制: 引用计数 垃圾回收 内存池 1. 引用计数 当一个python对象被引用时 其引用计数增加 1 ; 当其不再被变量引用时 引用计数减 1 ; 当对象引用计数等于 0 时, 对象被删除(引用计数是一种非常高效的内存管理机制) 2. 垃圾回收 垃圾回收机制: ① 引用计数 , ②标记清除 , ③分带回收 引用计数 : 引用计数也是一种垃圾收集机制, 而且也是一种最直观, 最简单的垃圾收集技术.当python某个对象的引用计数降为 0 时, 说明没有任何引用指向该对象, 该
-
nginx共享内存的机制详解
目录 1 共享内存申请 2 共享内存实现原理 2.1 共享内存组织 2.2 slab共享内存管理机制 2.3 slab与ngx_shm_zone_t 关系 3 共享内存应用 1 共享内存申请 共享内存申请比较简单,这里采用的是Linux系统共享内存分配的函数实现的. #include <sys/ipc.h> #include <sys/shm.h> ngx_int_t ngx_shm_alloc(ngx_shm_t *shm) { int id; id = shmget(IPC_P
-
linux下用户程序同内核通信详解(netlink机制)
简介 linux下用户程序同内核通信的方式一般有ioctl, proc文件系统,剩下一个就是Netlink套接字了. 这里先介绍下netlink. Netlink 是一种在内核与用户应用间进行双向数据传输的非常好的方式,用户态应用使用标准的 socket API 就可以使用 netlink 提供的强大功能,内核态需要使用专门的内核 API 来使用 netlink. Netlink 相对于系统调用,ioctl 以及 /proc 文件系统而言具有以下优点: 1,为了使用 netlink,用户仅需要在
-
Linux消息队列实现进程间通信实例详解
Linux消息队列实现进程间通信实例详解 一.什么是消息队列 消息队列提供了一种从一个进程向另一个进程发送一个数据块的方法. 每个数据块都被认为含有一个类型,接收进程可以独立地接收含有不同类型的数据结构.我们可以通过发送消息来避免命名管道的同步和阻塞问题.但是消息队列与命名管道一样,每个数据块都有一个最大长度的限制. Linux用宏MSGMAX和MSGMNB来限制一条消息的最大长度和一个队列的最大长度. 二.在Linux中使用消息队列 Linux提供了一系列消息队列的函数接口来让我们方便地使用
-
GoLang内存泄漏原因排查详解
目录 背景 临时性内存泄漏 通道理解 背景 Go 语言中有对应的Go 内存回收机制,在Go采用 并发三色标记清除 算法, 但是由于实际的过程中 发现会有一些内存泄漏的常见,内存泄漏 分为: 临时性 和 永久性内存泄漏. 初步排查过程中: 发现Linux使用top 发现内存随着时间会持续的增加没有稳定在一个合理值中. 在使用 pprof ,BBC 等 Go的内存泄漏工具进行排查 临时性内存泄漏 指的释放内存 不及时,对应的内存在更晚时候释放,这类问题主要是 string,slice 和底层的Bu
-
Java page cache回写机制案例详解
JAVA写文件的基本流程 在不使用堆外内存的情况下,java在写文件时,先将字节写入JVM的堆内内存中:然后调用jvm的写文件函数,将字节写入jvm的堆外内存中,jvm再调用系统内核的写文件函数,将字节写入内核的heap中:然后内核将字节写入page cache中,将page cache状态改为dirty,根据page cache的回写机制在合适的时机将字节写入磁盘. page cache 自动回写机制 page cache的回写时机由系统配置/etc/sysctl.conf 中的几个参数决定,
-
Rust Atomics and Locks内存序Memory Ordering详解
目录 Rust内存序 重排序和优化 happens-before Relexed Ordering Release 和 Acquire Ordering SeqCst Ordering Rust内存序 Memory Ordering规定了多线程环境下对共享内存进行操作时的可见性和顺序性,防止了不正确的重排序(Reordering). 重排序和优化 重排序是指编译器或CPU在不改变程序语义的前提下,改变指令的执行顺序.在单线程环境下,重排序可能会带来性能提升,但在多线程环境下,重排序可能会破坏程序
-
Java多线程之线程通信生产者消费者模式及等待唤醒机制代码详解
前言 前面的例子都是多个线程在做相同的操作,比如4个线程都对共享数据做tickets–操作.大多情况下,程序中需要不同的线程做不同的事,比如一个线程对共享变量做tickets++操作,另一个线程对共享变量做tickets–操作,这就是大名鼎鼎的生产者和消费者模式. 正文 一,生产者-消费者模式也是多线程 生产者和消费者模式也是多线程的范例.所以其编程需要遵循多线程的规矩. 首先,既然是多线程,就必然要使用同步.上回说到,synchronized关键字在修饰函数的时候,使用的是"this"
-
MyBatis 动态SQL和缓存机制实例详解
有的时候需要根据要查询的参数动态的拼接SQL语句 常用标签: - if:字符判断 - choose[when...otherwise]:分支选择 - trim[where,set]:字符串截取,其中where标签封装查询条件,set标签封装修改条件 - foreach: if案例 1)在EmployeeMapper接口文件添加一个方法 public Student getStudent(Student student); 2)如果要写下列的SQL语句,只要是不为空,就作为查询条件,如下所示,这样