python 爬虫请求模块requests详解
requests
相比urllib,第三方库requests更加简单人性化,是爬虫工作中常用的库
requests安装
初级爬虫的开始主要是使用requests模块
安装requests模块:
Windows系统:
cmd中:
pip install requests
mac系统中:
终端中:
pip3 install requests
requests库的基本使用
import requests url = 'https://www.csdn.net/' reponse = requests.get(url) #返回unicode格式的数据(str) print(reponse.text)

响应对象response的⽅法
response.text 返回unicode格式的数据(str)
response.content 返回字节流数据(⼆进制)
response.content.decode(‘utf-8') ⼿动进⾏解码
response.url 返回url
response.encode() = ‘编码'
状态码
response.status_code: 检查响应的状态码

例如:
200 : 请求成功
301 : 永久重定向
302 : 临时重定向
403 : 服务器拒绝请求
404 : 请求失败(服务器⽆法根据客户端的请求找到资源(⽹⻚))
500 : 服务器内部请求
# 导入requests import requests # 调用requests中的get()方法来向服务器发送请求,括号内的url参数就是我们 # 需要访问的网址,然后将获取到的响应通过变量response保存起来 url = 'https://www.csdn.net/' # csdn官网链接链接 response = requests.get(url) print(response.status_code) # response.status_code: 检查响应的状态码
200
请求⽅式
requests的几种请求方式:
p = requests.get(url)
p = requests.post(url)
p = requests.put(url,data={'key':'value'})
p = requests.delete(url)
p = requests.head(url)
p = requests.options(url)
GET请求
HTTP默认的请求方法就是GET
* 没有请求体
* 数据必须在1K之内!
* GET请求数据会暴露在浏览器的地址栏中
GET请求常用的操作:
1. 在浏览器的地址栏中直接给出URL,那么就一定是GET请求
2. 点击页面上的超链接也一定是GET请求
3. 提交表单时,表单默认使用GET请求,但可以设置为POST
POST请求
(1). 数据不会出现在地址栏中
(2). 数据的大小没有上限
(3). 有请求体
(4). 请求体中如果存在中文,会使用URL编码!
requests.post()用法与requests.get()完全一致,特殊的是requests.post()有一个data参数,用来存放请求体数据
请求头
当我们打开一个网页时,浏览器要向网站服务器发送一个HTTP请求头,然后网站服务器根据HTTP请求头的内容生成当此请求的内容发送给服务器。
我们可以手动设定请求头的内容:
import requests
header = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36'}
url = 'https://www.csdn.net/'
reponse = requests.get(url,headers=header)
#打印文本形式
print(reponse.text)
requests设置代理
使⽤requests添加代理只需要在请求⽅法中(get/post)传递proxies参数就可以了
cookie
cookie :通过在客户端记录的信息确定⽤户身份
HTTP是⼀种⽆连接协议,客户端和服务器交互仅仅限于 请求/响应过程,结束后 断开,下⼀次请求时,服务器会认为是⼀个新的客户端,为了维护他们之间的连接, 让服务器知道这是前⼀个⽤户发起的请求,必须在⼀个地⽅保存客户端信息。
requests操作Cookies很简单,只需要指定cookies参数即可
import requests
#这段cookies是从CSDN官网控制台中复制的
header = { 'User-Agent':'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/79.0.3945.88 Safari/537.36',
'cookie': 'uuid_tt_dd=10_30835064740-1583844255125-466273; dc_session_id=10_1583844255125.696601; __gads=ID=23811027bd34da29:T=1583844256:S=ALNI_MY6f7VlmNJKxrkHd2WKUIBQ34Bbnw; UserName=xdc1812547560; UserInfo=708aa833b2064ba9bb8ab0be63866b58; UserToken=708aa833b2064ba9bb8ab0be63866b58; UserNick=xdc1812547560; AU=F85; UN=xdc1812547560; BT=1590317415705; p_uid=U000000; Hm_ct_6bcd52f51e9b3dce32bec4a3997715ac=6525*1*10_30835064740-1583844255125-466273!5744*1*xdc1812547560; Hm_up_6bcd52f51e9b3dce32bec4a3997715ac=%7B%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22uid_%22%3A%7B%22value%22%3A%22xdc1812547560%22%2C%22scope%22%3A1%7D%7D; log_Id_click=1; Hm_lvt_feacd7cde2017fd3b499802fc6a6dbb4=1595575203; Hm_up_feacd7cde2017fd3b499802fc6a6dbb4=%7B%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22uid_%22%3A%7B%22value%22%3A%22xdc1812547560%22%2C%22scope%22%3A1%7D%7D; Hm_ct_feacd7cde2017fd3b499802fc6a6dbb4=5744*1*xdc1812547560!6525*1*10_30835064740-1583844255125-466273; Hm_up_facf15707d34a73694bf5c0d571a4a72=%7B%22islogin%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isonline%22%3A%7B%22value%22%3A%221%22%2C%22scope%22%3A1%7D%2C%22isvip%22%3A%7B%22value%22%3A%220%22%2C%22scope%22%3A1%7D%2C%22uid_%22%3A%7B%22value%22%3A%22xdc1812547560%22%2C%22scope%22%3A1%7D%7D; Hm_ct_facf15707d34a73694bf5c0d571a4a72=5744*1*xdc1812547560!6525*1*10_30835064740-1583844255125-466273; announcement=%257B%2522isLogin%2522%253Atrue%252C%2522announcementUrl%2522%253A%2522https%253A%252F%252Flive.csdn.net%252Froom%252Fyzkskaka%252Fats4dBdZ%253Futm_source%253D908346557%2522%252C%2522announcementCount%2522%253A0%257D; Hm_lvt_facf15707d34a73694bf5c0d571a4a72=1596946584,1597134917,1597155835,1597206739; searchHistoryArray=%255B%2522%25E8%258F%259C%25E9%25B8%259FIT%25E5%25A5%25B3%2522%252C%2522%25E5%25AE%25A2%25E6%259C%258D%2522%255D; log_Id_pv=7; log_Id_view=8; dc_sid=c0efd34d6da090a1fccd033091e0dc53; TY_SESSION_ID=7d77f76f-a4b1-43ef-9bb5-0aebee8ee475; c_ref=https%3A//www.baidu.com/link; c_first_ref=www.baidu.com; c_first_page=https%3A//www.csdn.net/; Hm_lvt_6bcd52f51e9b3dce32bec4a3997715ac=1597245305,1597254589,1597290418,1597378513; c_segment=1; dc_tos=qf1jz2; Hm_lpvt_6bcd52f51e9b3dce32bec4a3997715ac=1597387359'}
url = 'https://www.csdn.net/'
reponse = requests.get(url,headers=header)
#打印文本形式
print(reponse.text)
session
session :通过在服务端记录的信息确定⽤户身份
这⾥这个session就是⼀个指 的是会话
会话对象是一种高级的用法,可以跨请求保持某些参数,比如在同一个Session实例之间保存Cookie,像浏览器一样,我们并不需要每次请求Cookie,Session会自动在后续的请求中添加获取的Cookie,这种处理方式在同一站点连续请求中特别方便
处理不信任的SSL证书
什么是SSL证书?
SSL证书是数字证书的⼀种,类似于驾驶证、护照和营业执照的电⼦副本。
因为配置在服务器上,也称为SSL服务器证书。SSL 证书就是遵守 SSL协 议,由受信任的数字证书颁发机构CA,在验证服务器身份后颁发,具有服务 器身份验证和数据传输加密功能
我们来爬一个证书不太合格的网站
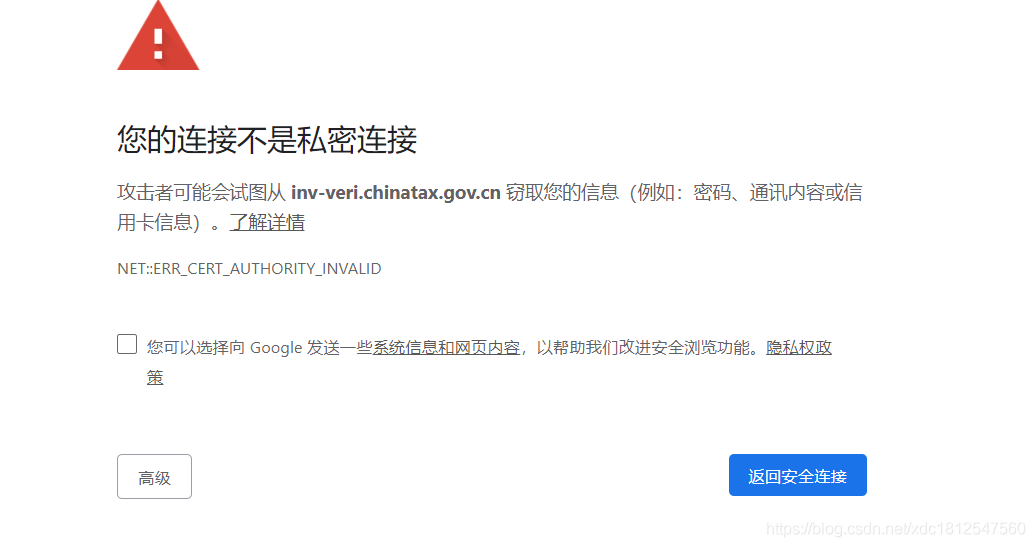
import requests url = 'https://inv-veri.chinatax.gov.cn/' resp = requests.get(url) print(resp.text)
它报了一个错

我们来修改一下代码
import requests url = 'https://inv-veri.chinatax.gov.cn/' resp = requests.get(url,verify = False) print(resp.text)
我们的代码又能成功爬取了

到此这篇关于python 爬虫请求模块requests的文章就介绍到这了,更多相关python 爬虫requests模块内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python+unittest+requests 接口自动化测试框架搭建教程
一.Python+unittest+requests+HTMLTestRunner 完整的接口自动化测试框架搭建_00--框架结构简解 首先配置好开发环境,下载安装Python并下载安装pycharm,在pycharm中创建项目功能目录.如果不会的可以百度Google一下,该内容网上的讲解还是比较多比较全的! 大家可以先简单了解下该项目的目录结构介绍,后面会针对每个文件有详细注解和代码. common: --configDb.py:这个文件主要编写数据库连接池的相关内容,本项目暂未考虑使用数据库
-

python 实现Requests发送带cookies的请求
一.缘 起 最近学习[悠悠课堂]的接口自动化教程,文中提到Requests发送带cookies请求的方法,笔者随之也将其用于手头实际项目中,大致如下 二.背 景 实际需求是监控平台侧下发消息有无异常,如有异常便触发报警推送邮件,项目中下发消息接口需要带cookies 三.说 明 脚本的工程名为ynJxhdSendMsg,大致结构如下图 sendMsg.py为主程序,函数checkMsg为在已发消息列表中查找已下发消息,函数sendMsg为发消息并根据结果返回对应的标识 sendAlertEmai
-
Python+unittest+requests+excel实现接口自动化测试框架
环境:python3 + unittest + requests Excel管理测试用例, HTMLTestRunner生成测试报告 测试完成后邮件发送测试报告 jsonpath方式做预期结果数据处理,后期多样化处理 后期扩展,CI持续集成 发送邮件效果: 项目整体结构: common模块代码 class IsInstance: def get_instance(self, value, check): flag = None if isinstance(value, str): if chec
-
python+requests实现接口测试的完整步骤
本文包括requests库的安装过程.requests库的基本语法以及一个实例(携带token登录对人员进行注册) 一.requests安装 可以通过控制台输入命令pip install requests安装requests,但是我这里主要介绍pycharm工具中安装requests 一张图解释安装步骤,简单快捷 二.requests常用语法 1.基本请求方法,包含参数传递 (1)get参数传递,示例: url="xxxxx" xx={ "xxx":"xx
-
python爬虫利器之requests库的用法(超全面的爬取网页案例)
requests库 利用pip安装: pip install requests 基本请求 req = requests.get("https://www.baidu.com/") req = requests.post("https://www.baidu.com/") req = requests.put("https://www.baidu.com/") req = requests.delete("https://www.baid
-
Python requests HTTP验证登录实现流程
1.场景 1)用户输入完网址后,浏览器直接弹出需要输入用户名/密码 PS:此时输入用户名密码即可登录,或者直接带着用户名密码访问网站. 假设url为http://xxx.yyy.zzz 用户名为admin 密码为123456 则访问的网址应该为http://admin:123456@xxx.yyy.zzz[http://username:password@url] 直接访问改网址即可 2)利用requests.get(url)返回状态码为401 # -*- encoding=utf-8 -*-
-
python中requests模拟登录的三种方式(携带cookie/session进行请求网站)
一,cookie和session的区别 cookie在客户的浏览器上,session存在服务器上 cookie是不安全的,且有失效时间 session是在cookie的基础上,服务端设置session时会向浏览器发送设置一个设置cookie的请求,这个cookie包括session的id当访问服务端时带上这个session_id就可以获取到用户保存在服务端对应的session 二,爬虫处理cookie和session 带上cookie和session的好处: 能够请求到登录后的界面 带上cook
-
Python模拟登录requests.Session应用详解
最近由于某些原因,需要用到Python模拟登录网站,但是以前对这块并不了解,而且目标网站的登录方法较为复杂, 所以一下卡在这里了,于是我决定从简单的模拟开始,逐渐深入地研究下这块. 注:本文仅为交流学习所用. 登录特点:明文传输,有特殊标志数据 会话对象requests.Session能够跨请求地保持某些参数,比如cookies,即在同一个Session实例发出的所有请求都保持同一个cookies,而requests模块每次会自动处理cookies,这样就很方便地处理登录时的cookies问题.
-
python爬虫 requests-html的使用
一 介绍 Python上有一个非常著名的HTTP库--requests,相信大家都听说过,用过的人都说非常爽!现在requests库的作者又发布了一个新库,叫做requests-html,看名字也能猜出来,这是一个解析HTML的库,具备requests的功能以外,还新增了一些更加强大的功能,用起来比requests更爽!接下来我们来介绍一下它吧. # 官网解释 ''' This library intends to make parsing HTML (e.g. scraping the web
-
python编程之requests在网络请求中添加cookies参数方法详解
哎,好久没有学习爬虫了,现在想要重新拾起来.发现之前学习爬虫有些粗糙,竟然连requests中添加cookies都没有掌握,惭愧.废话不宜多,直接上内容. 我们平时使用requests获取网络内容很简单,几行代码搞定了,例如: import requests res=requests.get("https://cloud.flyme.cn/browser/index.jsp") print res.content 你没有看错,真的只有三行代码.但是简单归简单,问题还是不少的. 首先,这
-
Python requests上传文件实现步骤
官方文档:https://2.python-requests.org//en/master/ 工作中涉及到一个功能,需要上传附件到一个接口,接口参数如下: 使用http post提交附件 multipart/form-data 格式,url : http://test.com/flow/upload, 字段列表: md5: //md5加密(随机值_当时时间戳) filesize: //文件大小 file: //文件内容(须含文件名) 返回值: {"success":true,"
-
python使用requests库爬取拉勾网招聘信息的实现
按F12打开开发者工具抓包,可以定位到招聘信息的接口 在请求中可以获取到接口的url和formdata,表单中pn为请求的页数,kd为关请求职位的关键字 使用python构建post请求 data = { 'first': 'true', 'pn': '1', 'kd': 'python' } headers = { 'referer': 'https://www.lagou.com/jobs/list_python/p-city_0?&cl=false&fromSearch=true&a