python网络爬虫实现发送短信验证码的方法
前言:今天要总结的是如何用程序来实现短信发送功能。但是呢,可能需要我们调用一些api接口,我会详细介绍。都是自己学到的,害怕忘记,所以要总结一下,让写博客成为一种坚持的信仰。废话不多说,我们开始吧!
网络爬虫实现发送短信验证码
在实现我们目标的功能之前,我们要有自己的思路,否则你没有方向,又如何实现自己的代码功能呢?
我们要发送短信,那么我们其实是需要分析的。我们可以去分析一个可以发送短信的网站页面。
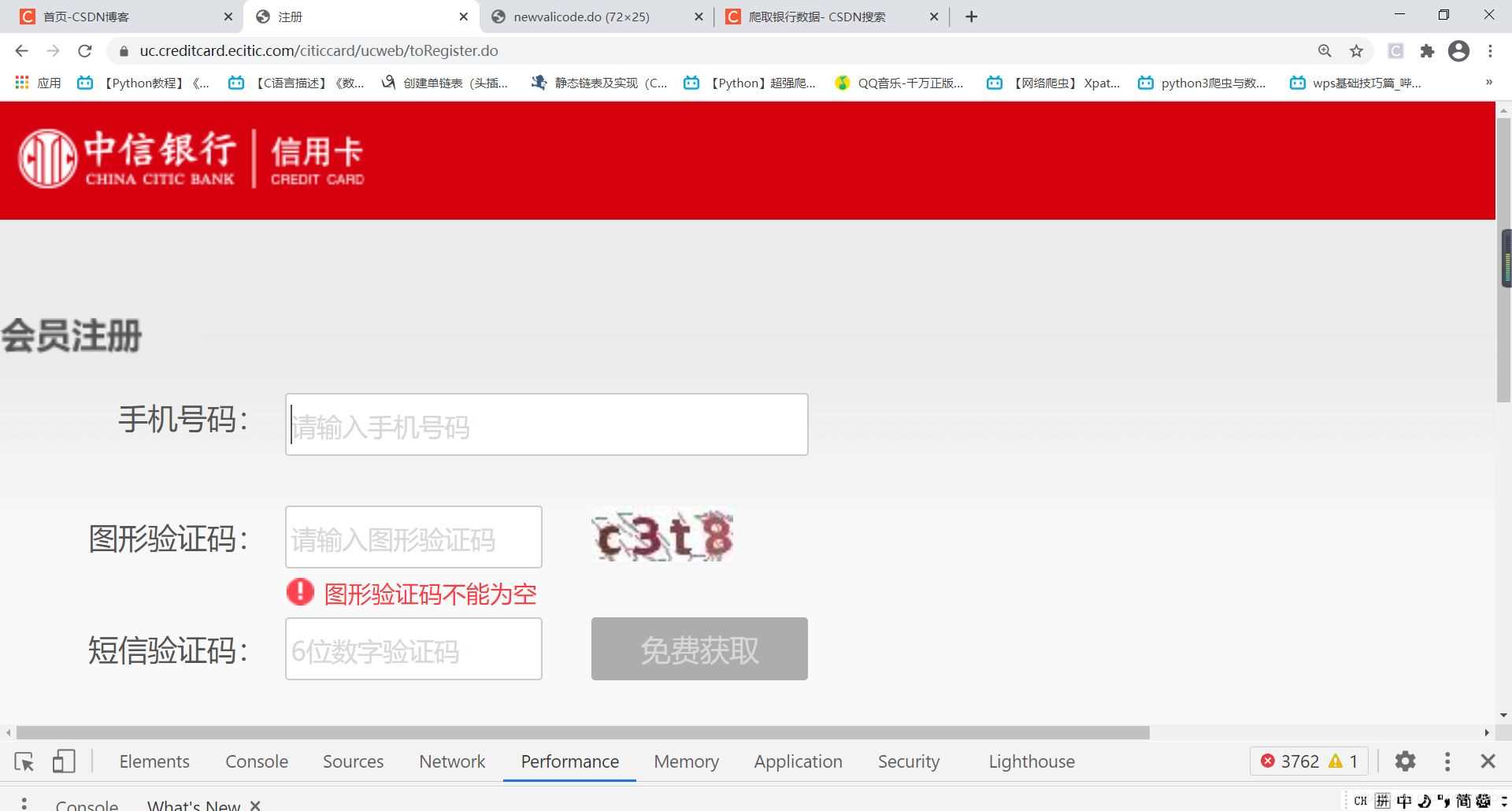
我们来到这里如下:
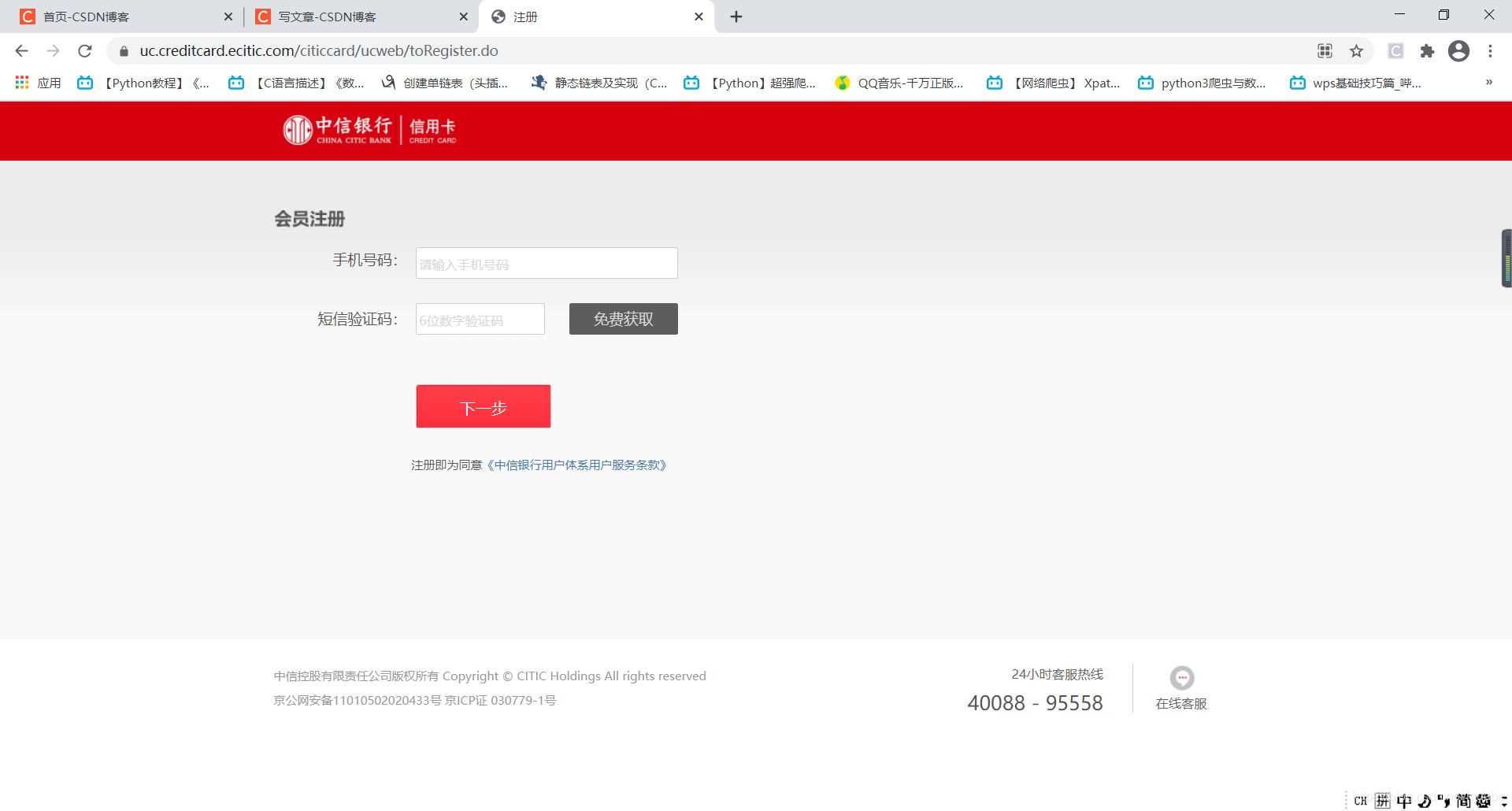
可以看到这是一个注册界面,我们在注册时会被要求需要填写手机号码的·,其实还有一栏验证码识别,像这里打开没有,那你就填写几个号码,发送,多刷新几次,就可以了。
不为别人添麻烦,我填写自己的号码。
多次刷新会出现,不过要填写不同的手机号码。你们懂的,我们要看到这个有验证码的界面。

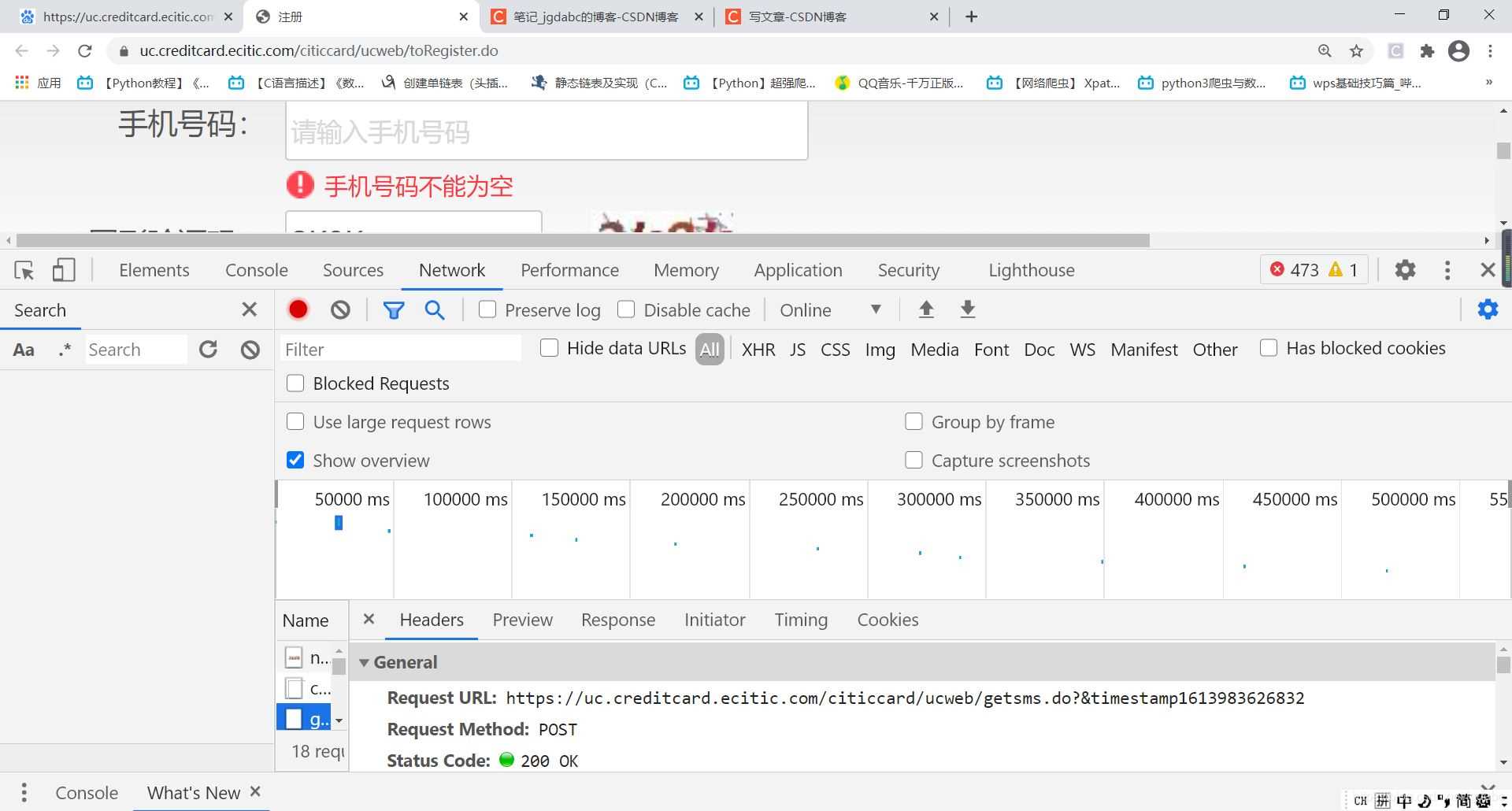
我们打开chrome谷歌抓包工具,也就是邮件检查即可。我们点击network直接进行抓包,记得在抓包前最好清除下面出现的一切包。我们要点击验证码,让网页做出反应,然后同步一下,进行抓包。
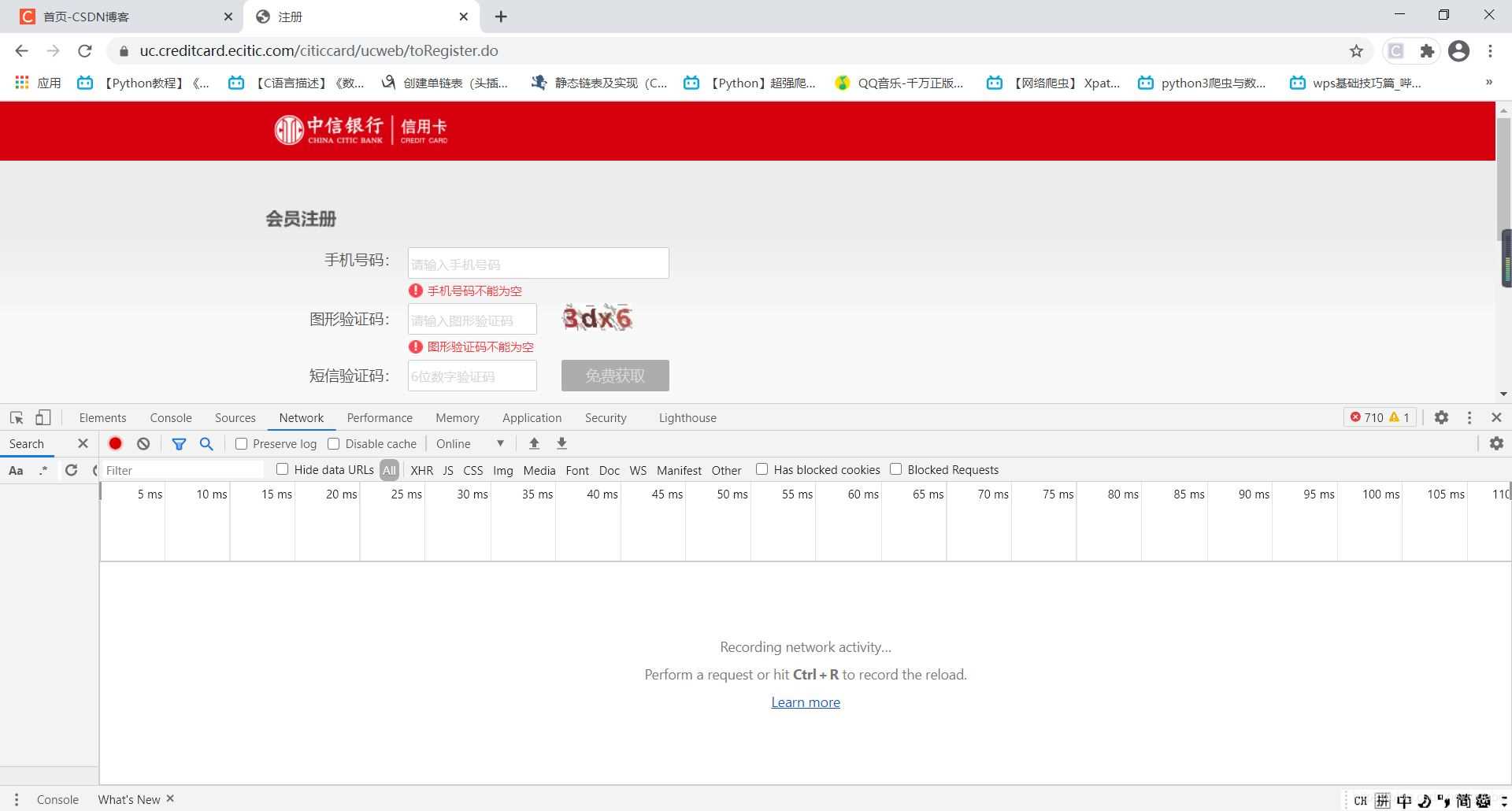
当我们填写手机号以后,我们只要点击那个验证码,然后进行抓包如下

看到没有,其实点击同步瞬间只有一个数据包的,在你做其他的动作时,可能会出现其他的数据包,但是与此无关。
我们直接点进去看

我们看这个url
https://uc.creditcard.ecitic.com/citiccard/ucweb/newvalicode.do?time=1613969346256
我们打开这个url看看庐山真面目
留意观察这个time参数,很明显是一个时间戳参数
时间戳参数又是什么概念呢?这里有必要介绍一下
时间戳 : 格林威治时间1970年1月0点0分0秒到目前为止
秒级时间戳:10数字
毫秒级时间戳 :13位数字
微秒级时间戳:16位数字
可以看到这个time参数属于毫秒级别的时间戳的。
我们访问这个见面,每次刷新都会有不同的验证码,返回当前的时间。如果我们要获取当前的验证码,我们需要url,前面的参数都一样,只有time,我们需要获取time时间。如何获取呢。
python中有一个time库,我们导入,来看如何使用。
下面展示一些 内联代码片。
import time
def get_time() :
" 获取当前的时间戳"
now_time =str(int(time.time()*1000))#获取毫秒级的时间戳
print('当前的时间戳',now_time)
return now_time
get_time()
来看运行结果
我们目前可以这样去做
我们把这个获取到的时间戳参数加入到url中,我们可以实现动态的获取,每次要要获取这个二维码时就需要指定当前的时间time参数,那我们完全可以这样来构造这个url。我们用一个变量来接收获取的时间戳,然后以字符串的形式加入到time后面。
下面展示一些 内联代码片。
import time
def get_time() :
" 获取当前的时间戳"
now_time =str(int(time.time()*1000))#获取毫秒级的时间戳
print('当前的时间戳',now_time)
return now_time
time_one = get_time()
img_url = 'https://uc.creditcard.ecitic.com/citiccard/ucweb/newvalicode.do?time='+time_one
print(img_url)
我们来看是否可以获取到相应正确的url
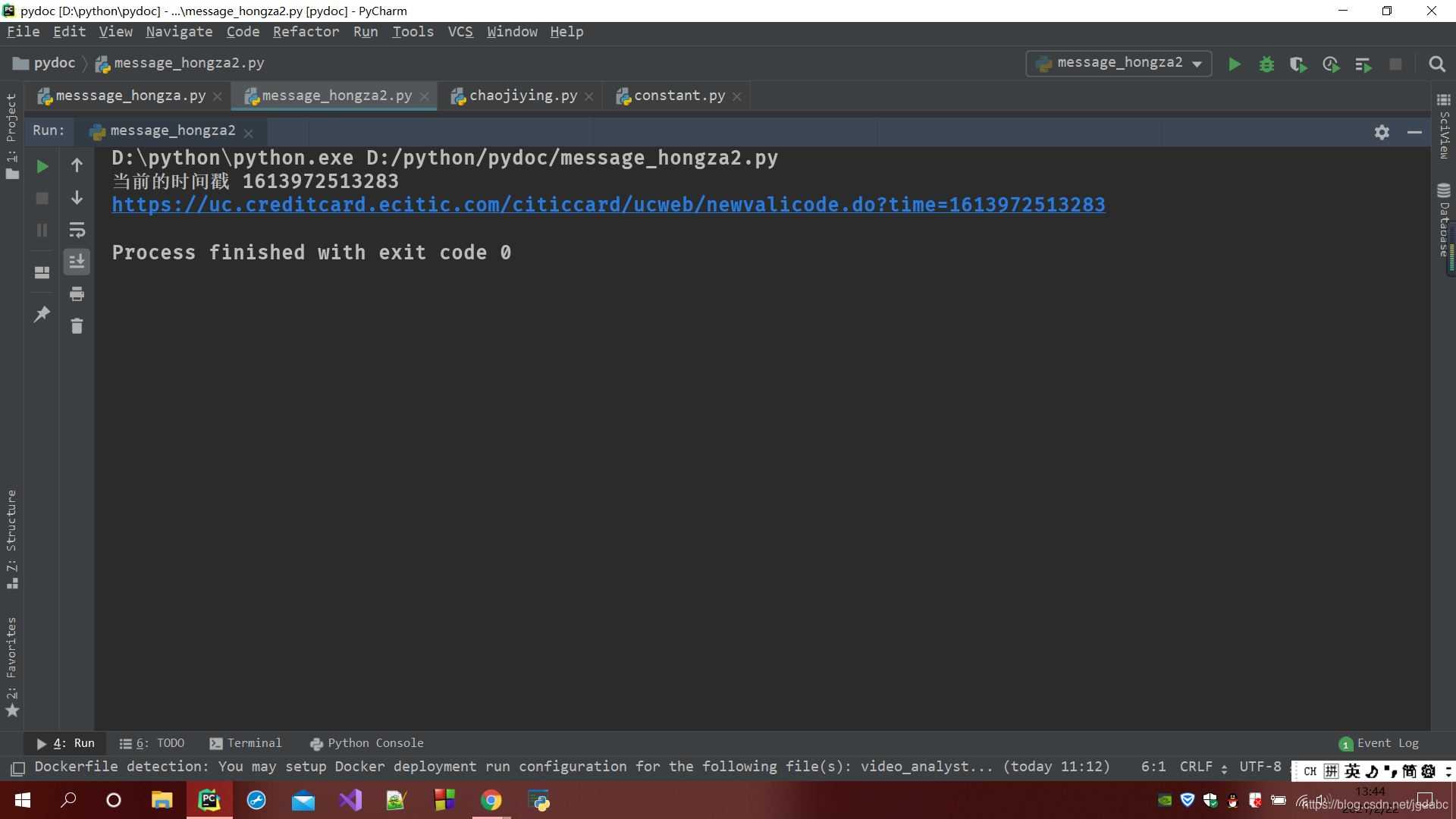
我们点入那个蓝色的链接,来看有没有获取到这个验证码图片。

测试证明我们完全是对的。
下一步我们要做的是实现代码的访问,获取并保存这个验证码。为什么保存,我们应该知道这点知识。
看这三个提交栏,很明显是一个要提交表单的。提交那就需要post,而post请求呢,就是要提交我们的数据,及手机号码和图形验证码。
当我们把数据提交上去以后,我们在手机上就会收到短信验证码。我们以此来实现发送短信验证码的功能。
我们来保存图片验证码
下面展示一些 内联代码片。
import time
import requests
def get_time() :
" 获取当前的时间戳"
now_time =str(int(time.time()*1000))#获取毫秒级的时间戳
print('当前的时间戳',now_time)
return now_time
time_one = get_time()
img_url = 'https://uc.creditcard.ecitic.com/citiccard/ucweb/newvalicode.do?time='+time_one
print(img_url)
headers = {
'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
response = requests.get(url=img_url,headers = headers)
img_data = response.content
with open('yzm.jpg',mode = 'wb') as file :
file.write(img_data)

可以看到在代码编辑器右边已经出现了保存的图片。
下一步我们继续来分析这个手机号码的数据和图片验证码的数据在哪里传入,又是如何实现。
我们输入一个手机号码,然后输入图片验证码,然后点击免费获取。此时再次进行抓包,抓包的方法与上文的第一次抓包方法相同。
我们来看会出现什么样的包。

蓝色部分的就是我们寻找的目标包。然后我们如何去做?点击打开查看相应的代码。
看到没有post请求,是因该提交表单数据的。我们看看下面的表单数据
这里你会发现有一点不同电话号码是直接的数字,图片验证码就需要你来处理了,因为我们上文保存的验证码是图片,你如何识别到这图片验证码里面额数据,来进行传入呢?这里我们还需要一个网站。
超级鹰,是用来识别验证码的,其实我们还是调用这个接口。
我们点击开发文档,我们是用Python写的代码。所以我们点击python的图标,来这里来查看我们需要的。
在下面找到超级鹰图像识别,然后点击下载。把里面的api接口的py文件导入到你的python编辑器。我这里是用Pycharm写的。所以直接将解压出来的Python文件拖入pycharm。

下面是里面的部分代码。
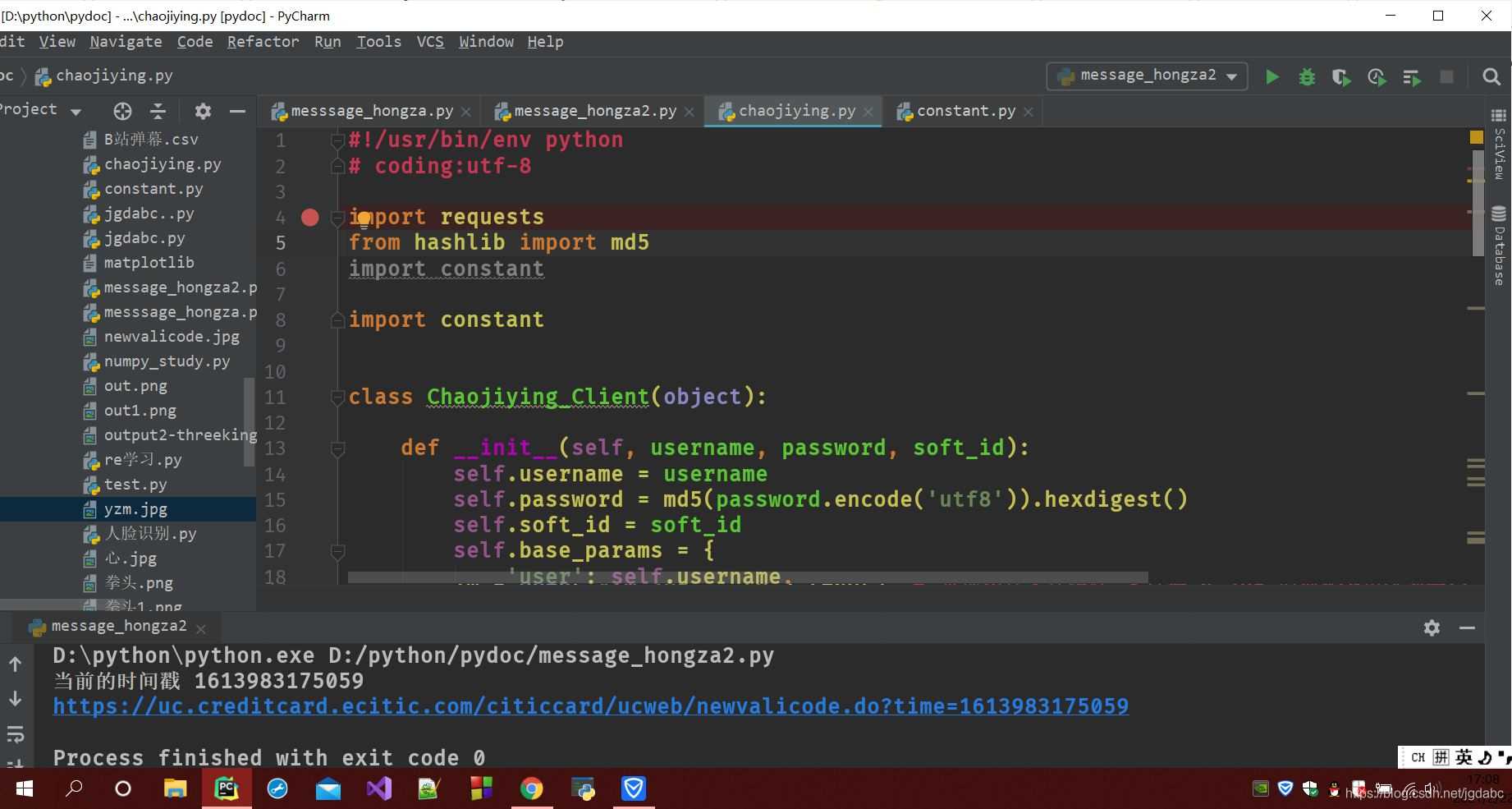
这里面做了小小的修改。我们直接来看这段代码写了什么。
我来告诉大家原始的代码有问题,很低级的问题。
#!/usr/bin/env python
# coding:utf-8
import requests
from hashlib import md5
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')
self.password = md5(password).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files, headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print chaojiying.PostPic(im, 1902) #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
上面这个是他的原始接口代码。就很离谱。分块来分析。
def __init__(self, username, password, soft_id):
self.username = username
password = password.encode('utf8')#没有缩进
self.password = md5(password).hexdigest()
self.soft_id = soft_id
.......
.......
这块的错误在哪呢?我这里特意表明突出,上面的原始代码直接沾到这里并不突出,但是你用编辑器打开会有问题的。
if __name__ == '__main__':
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print chaojiying.PostPic(im, 1902) #print没有加 () #1902 验证码类型 官方网站>>价格体系 3.#4+版 print 后要加()
还有一处,在这里,代码格式都没有写对,我这里指出,读者应该可以发现。这里介意读者可以去平台下载这个接口,自己去修改。
好,且不在谈这些,我们继续。我们还是修改部分代码。
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
if __name__ == '__main__':
chaojiying = Chaojiying_Client('超级鹰用户名', '超级鹰用户名的密码', '96001') #用户中心>>软件ID 生成一个替换 96001
im = open('a.jpg', 'rb').read() #本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
print chaojiying.PostPic(im, 1902) #这是原始的代码 #1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
我们可以在这内部写一个方法,我们待会要调用这个代码接口时,直接调用这个方法。
注意我们在类里面添加这样一部分代码,就是写一个方法
def run(self):
chaojiying = Chaojiying_Client(constant.USER_NAME, constant.PASSWORD,
913137) # 用户中心>>软件ID 生成一个替换 96001
im = open('yzm.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
result = chaojiying.PostPic(im, 1004) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
return result['pic_str']
注意分析这个接口代码,里面 chaojiying = Chaojiying_Client(constant.USER_NAME, constant.PASSWORD,913137)
在注释里面其实说的已经很清楚了,这里的constant代表我们要导入的py文件,里面包含你的用户名,密码,以及软件id。
im = open(‘yzm.jpg', ‘rb').read() 打开你保存的验证码文件,上面我们已经保存过。
result = chaojiying.PostPic(im, 1004) 1004代表你的验证码类型。
用户名和密码你需要注册一下。那么软件id和验证码类型你该如何确定呢?
这是主页,请点击价格体系
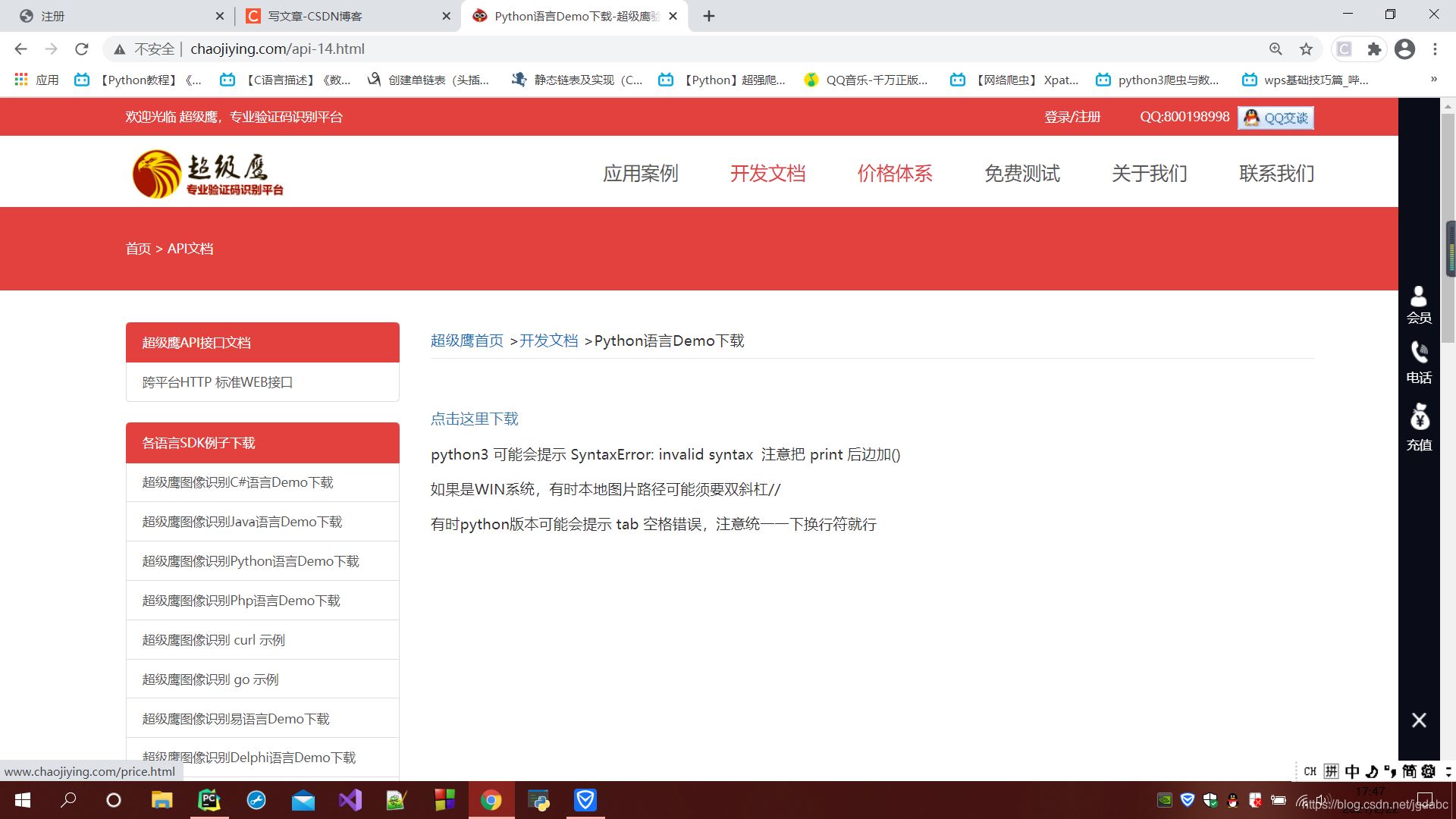
在下面你可以来判断你的验证码类型了
我们这里需要登录进入用户中心

进入如下界面
往下拉进入软件id
进入后点击生成一个软件id,软件名称和软件说明可以随便填写

这样我们就可以获得一个软件id 。
这个constant如何编写,很简单,建立一个py文件,里面写入
USER_NAME=' …' PASSWORD='… '
然后保存即可。导入py文件到当前路劲,然后import即可。
现在我们来看完整的代码
接口完整修改后的代码
import requests
from hashlib import md5
import constant
import constant
class Chaojiying_Client(object):
def __init__(self, username, password, soft_id):
self.username = username
self.password = md5(password.encode('utf8')).hexdigest()
self.soft_id = soft_id
self.base_params = {
'user': self.username,
'pass2': self.password,
'softid': self.soft_id,
}
self.headers = {
'Connection': 'Keep-Alive',
'User-Agent': 'Mozilla/4.0 (compatible; MSIE 8.0; Windows NT 5.1; Trident/4.0)',
}
def PostPic(self, im, codetype):
"""
im: 图片字节
codetype: 题目类型 参考 http://www.chaojiying.com/price.html
"""
params = {
'codetype': codetype,
}
params.update(self.base_params)
files = {'userfile': ('ccc.jpg', im)}
r = requests.post('http://upload.chaojiying.net/Upload/Processing.php', data=params, files=files,
headers=self.headers)
return r.json()
def ReportError(self, im_id):
"""
im_id:报错题目的图片ID
"""
params = {
'id': im_id,
}
params.update(self.base_params)
r = requests.post('http://upload.chaojiying.net/Upload/ReportError.php', data=params, headers=self.headers)
return r.json()
def run(self):
chaojiying = Chaojiying_Client(constant.USER_NAME, constant.PASSWORD,
913137) # 用户中心>>软件ID 生成一个替换 96001
im = open('yzm.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
result = chaojiying.PostPic(im, 1004) # 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
return result['pic_str']
if __name__ == '__main__':
chaojiying = Chaojiying_Client(constant.USER_NAME, constant.PASSWORD, 913137) # 用户中心>>软件ID 生成一个替换 96001
im = open('yzm.jpg', 'rb').read() # 本地图片文件路径 来替换 a.jpg 有时WIN系统须要//
result = chaojiying.PostPic(im, 1004)
print(chaojiying.PostPic(im,1004))# 1902 验证码类型 官方网站>>价格体系 3.4+版 print 后要加()
主文件代码,从这里执行
import time
import requests
from chaojiying import Chaojiying_Client
import constant
def get_time() :
" 获取当前的时间戳"
now_time =str(int(time.time()*1000))#获取毫秒级的时间戳
print('当前的时间戳',now_time)
return now_time
time_one = get_time()
img_url = 'https://uc.creditcard.ecitic.com/citiccard/ucweb/newvalicode.do?time='+time_one
print(img_url)
headers = {
'User-Agent' :'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.150 Safari/537.36'
}
response = requests.get(url=img_url,headers = headers)
img_data = response.content
with open('yzm.jpg',mode = 'wb') as file :
file.write(img_data)
print(response)
#验证码识别
code = Chaojiying_Client(constant.USER_NAME,constant.PASSWORD,913137).run()
print('识别出来的验证码为',code)
#请求保证同一个用户
cookiejar = response.cookies
cookies = cookiejar.get_dict()
print(cookies)
data = {
'phone' :19745678397,
'imgValidCode' : code,
}
time_two = get_time()
code_url = 'https://uc.creditcard.ecitic.com/citiccard/ucweb/getsms.do?×tamp'+time_two
requests_two = requests.post(url=code_url,data= data,headers=headers,cookies=cookies)
print(requests_two.json())
我们来看运行结果
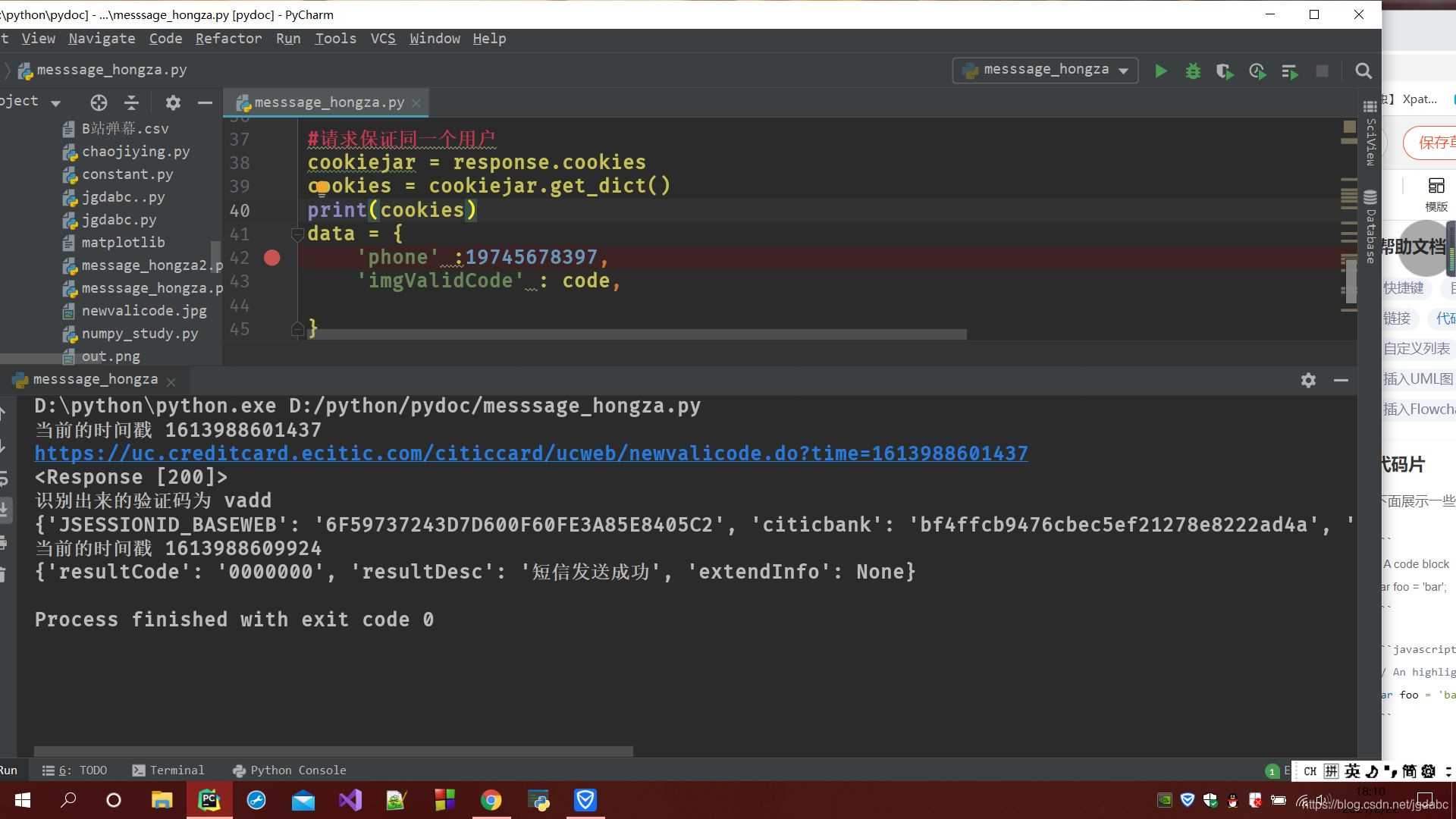
ok,短信发送成功
需要注意的是,如果你发送多次的话,那么会出现提醒你短信发送频率过高的提示。这是服务器的响应。
我们总结一下该程序实现了发送验证码的功能,如果你需要实现发送你想要的文本,那么你需要调用其它的接口。别的就不多说了,毕竟爬虫也需要讲武德。
到此这篇关于python网络爬虫实现发送短信验证码的方法的文章就介绍到这了,更多相关python爬虫发送短信验证码内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python3网络爬虫开发实战之极验滑动验证码的识别
上节我们了解了图形验证码的识别,简单的图形验证码我们可以直接利用 Tesserocr 来识别,但是近几年又出现了一些新型验证码,如滑动验证码,比较有代表性的就是极验验证码,它需要拖动拼合滑块才可以完成验证,相对图形验证码来说识别难度上升了几个等级,本节来讲解下极验验证码的识别过程. 1. 本节目标 本节我们的目标是用程序来识别并通过极验验证码的验证,其步骤有分析识别思路.识别缺口位置.生成滑块拖动路径,最后模拟实现滑块拼合通过验证. 2. 准备工作 本次我们使用的 Python 库是 Selen
-
Python3爬虫关于识别检验滑动验证码的实例
上节我们了解了图形验证码的识别,简单的图形验证码我们可以直接利用 Tesserocr 来识别,但是近几年又出现了一些新型验证码,如滑动验证码,比较有代表性的就是极验验证码,它需要拖动拼合滑块才可以完成验证,相对图形验证码来说识别难度上升了几个等级,本节来讲解下极验验证码的识别过程. 1. 本节目标 本节我们的目标是用程序来识别并通过极验验证码的验证,其步骤有分析识别思路.识别缺口位置.生成滑块拖动路径,最后模拟实现滑块拼合通过验证. 2. 准备工作 本次我们使用的 Python 库是 Selen
-
python爬虫如何解决图片验证码
之前刚开始做爬虫的时候遇到过登录验证码问题,看过很多帖子都没有解决我的问题,发现大多数帖子都是治标不治本,于是想分享一下自己的解决方案.本次采用的网站是古诗文网,使用百度API,因为百度API免费!免费!免费!适合自己学习的时候使用.如果还没有使用过百度API识别验证码的朋友可以看一下我的这个帖子. 以下案例采用的时古诗文网:登录古诗文网, 1.selenium处理图片验证码 先定位到验证码图片,在获取验证码图片在页面中的位置,使用save_screenshot截取页面,再根据图片的位置去截取验
-

Python爬虫爬验证码实现功能详解
主要实现功能: - 登陆网页 - 动态等待网页加载 - 验证码下载 很早就有一个想法,就是自动按照脚本执行一个功能,节省大量的人力--个人比较懒.花了几天写了写,本着想完成验证码的识别,从根本上解决问题,只是难度太高,识别的准确率又太低,计划再次告一段落. 希望这次经历可以与大家进行分享和交流. Python打开浏览器 相比与自带的urllib2模块,操作比较麻烦,针对于一部分网页还需要对cookie进行保存,很不方便.于是,我这里使用的是Python2.7下的selenium模块进行网页上的操
-
Python3爬虫中识别图形验证码的实例讲解
本节我们首先来尝试识别最简单的一种验证码,图形验证码,这种验证码出现的最早,现在也很常见,一般是四位字母或者数字组成的,例如中国知网的注册页面就有类似的验证码,链接为:http://my.cnki.net/elibregister/commonRegister.aspx,页面: 表单的最后一项就是图形验证码,我们必须完全输入正确图中的字符才可以完成注册. 1.本节目标 本节我们就以知网的验证码为例,讲解一下利用 OCR 技术识别此种图形验证码的方法. 2. 准备工作 识别图形验证码需要的库有 T
-
Python3爬虫关于识别点触点选验证码的实例讲解
上一节我们实现了极验验证码的识别,但是除了极验其实还有另一种常见的且应用广泛的验证码,比较有代表性的就是点触验证码. 可能你对这个名字比较陌生,但是肯定见过类似的验证码,比如 12306,这就是一种典型的点触验证码,如图所示: 我们需要直接点击图中符合要求的图,如果所有答案均正确才会验证成功,如果有一个答案错误,验证就会失败,这种验证码就可以称之为点触验证码. 另外还有一个专门提供点触验证码服务的站点,叫做 TouClick,其官方网站为:https://www.touclick.com/,本节
-
Python爬虫模拟登录带验证码网站
爬取网站时经常会遇到需要登录的问题,这是就需要用到模拟登录的相关方法.python提供了强大的url库,想做到这个并不难.这里以登录学校教务系统为例,做一个简单的例子. 首先得明白cookie的作用,cookie是某些网站为了辨别用户身份.进行session跟踪而储存在用户本地终端上的数据.因此我们需要用Cookielib模块来保持网站的cookie. 这个是要登陆的地址 http://202.115.80.153/ 和验证码地址 http://202.115.80.153/CheckCode.
-
python爬虫解决验证码的思路及示例
如果直接从生成验证码的页面把验证码下载到本地后识别,再构造表单数据发送的话,会有一个验证码同步的问题,即请求了两次验证码,而识别出来的验证码并不是实际需要发送的验证码.有如下几种方法解决. 法1: 用session: mysession = requests.Session() login_url = 'http://xxx.com' checkcode_url='http://yyy.com' html = mysession.get(login_url,timeout=60*4) #....
-
Python爬虫实现验证码登录代码实例
很多网站为了避免被恶意访问,需要设置验证码登录,避免非人类的访问,Python爬虫实现验证码登录的原理则是先到登录页面将生成的验证码保存下来,然后人为输入后,包装后再POST给服务器,实现验证,这里还涉及到了Cookie,其实Cookie保存在本地主机上,避免用户重复输入用户名和密码,在连接服务器的时候将访问连接和Cookie组装起来POST给服务器. 这里涉及到了两次向服务器POST,一次是Cookie,这里还自行设计想要Cookie的内容,由于是要登录,Cookie中存放的则是用户名和密码.
-
python爬虫之自动登录与验证码识别
在用爬虫爬取网站数据时,有些站点的一些关键数据的获取需要使用账号登录,这里可以使用requests发送登录请求,并用Session对象来自动处理相关Cookie. 另外在登录时,有些网站有时会要求输入验证码,比较简单的验证码可以直接用pytesser来识别,复杂的验证码可以依据相应的特征自己采集数据训练分类器. 以CSDN网站的登录为例,这里用Python的requests库与pytesser库写了一个登录函数.如果需要输入验证码,函数会首先下载验证码到本地,然后用pytesser识别验证码后登