python实现蒙特卡罗模拟法的实践
目录
- 1.简介
- 2.实例分析
- 2.1模拟求近似圆周率
- 2.2 估算定积分
- 2.3 求解整数规划
1.简介
蒙特卡洛又称随机抽样或统计试验,就是产生随机变量,带入模型算的结果,寻优方面,只要模拟次数够多,最终是可以找到最优解或接近最优的解。
通常蒙特卡罗方法可以粗略地分成两类:一类是所求解的问题本身具有内在的随机性,借助计算机的运算能力可以直接模拟这种随机的过程。例如在核物理研究中,分析中子在反应堆中的传输过程。中子与原子核作用受到量子力学规律的制约,人们只能知道它们相互作用发生的概率,却无法准确获得中子与原子核作用时的位置以及裂变产生的新中子的行进速率和方向。科学家依据其概率进行随机抽样得到裂变位置、速度和方向,这样模拟大量中子的行为后,经过统计就能获得中子传输的范围,作为反应堆设计的依据。
另一种类型是所求解问题可以转化为某种随机分布的特征数,比如随机事件出现的概率,或者随机变量的期望值。通过随机抽样的方法,以随机事件出现的频率估计其概率,或者以抽样的数字特征估算随机变量的数字
2.实例分析
2.1 模拟求近似圆周率
绘制单位圆和外接正方形,正方形ABCD的面积为:2*2=4,圆的面积为:S=Π*1*1=Π,现在模拟产生在正方形ABCD中均匀分布的点n个,如果这n个点中有m个点在该圆内,则圆的面积与正方形ABCD的面积之比可近似为m/n

程序如下:
#模拟求近似圆周率
import random
import numpy as np
import matplotlib.pyplot as plt
#解决图标题中文乱码问题
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#进入正题
r=random.random()
num=range(0,200000,10)
mypi=np.ones((1,len(num)))
for j in range(len(num)):
# 投点次数
n = 10000
# 圆的半径、圆心
r = 1.0
a,b = (0.,0.)
# 正方形区域
x_min, x_max = a-r, a+r
y_min, y_max = b-r, b+r
# 在正方形区域内随机投点
x = np.random.uniform(x_min, x_max, n) #均匀分布
y = np.random.uniform(y_min, y_max, n)
#计算点到圆心的距离
d = np.sqrt((x-a)**2 + (y-b)**2)
#统计落在圆内点的数目
res = sum(np.where(d < r, 1, 0))
#计算pi的近似值(Monte Carlo:用统计值去近似真实值)
mypi[0,j] = 4 * res / n
plt.plot(range(1,len(mypi[0])+1),mypi[0],'.-')
plt.grid(ls=":",c='b',)#打开坐标网格
plt.axhline(y=np.pi,ls=":",c="yellow")#添加水平直线
# plt.axvline(x=4,ls="-",c="green")#添加垂直直线
plt.legend(['模拟', '实际'], loc='upper right', scatterpoints=1)
plt.title("近似圆周率")
plt.show()
返回:

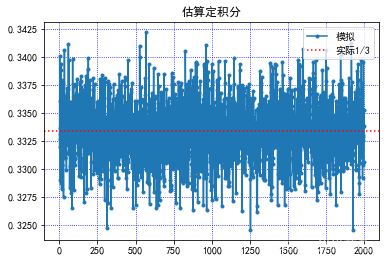
2.2 估算定积分

程序如下:
#估算定积分
import random
import numpy as np
import matplotlib.pyplot as plt
#解决图标题中文乱码问题
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#进入正题
r=random.random()
num=range(1,10**6,500)
s = np.ones((1,len(num)))
for j in range(len(num)):
n = 30000
#矩形边界区域
x_min, x_max = 0.0, 1.0
y_min, y_max = 0.0, 1.0
#在矩形区域内随机投点x
x = np.random.uniform(x_min, x_max, n)#均匀分布
y = np.random.uniform(y_min, y_max, n)
#统计落在函数y=x^2下方的点
res = sum(np.where(y < x**2, 1 ,0))
#计算定积分的近似值
s[0,j] = res / n
plt.plot(range(1,len(s[0])+1),s[0],'.-')
plt.grid(ls=":",c='b',)#打开坐标网格
plt.axhline(y=1/3,ls=":",c="red")#添加水平直线
# plt.axvline(x=4,ls="-",c="green")#添加垂直直线
plt.legend(['模拟', '实际1/3'], loc='upper right', scatterpoints=1)
plt.title("估算定积分")
plt.show()
返回:
2.3 求解整数规划
要解的方程为:

条件如下:
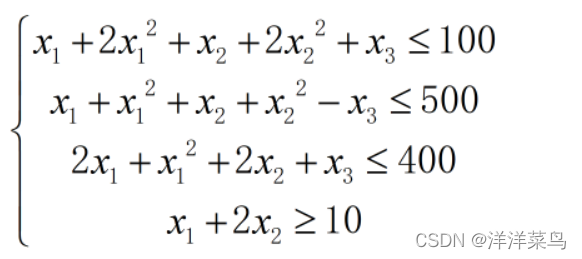
程序如下:
# 求解整数规划
import random
import numpy as np
import time
import matplotlib.pyplot as plt
#解决图标题中文乱码问题
import matplotlib as mpl
mpl.rcParams['font.sans-serif'] = ['SimHei'] # 指定默认字体
mpl.rcParams['axes.unicode_minus'] = False # 解决保存图像是负号'-'显示为方块的问题
#进入正题
time_start=time.time() #计时开始
p0=0
for i in range(10**7):
x=np.random.randint(0,99,(1,3))
f=2*x[0,0]+3*x[0,0]**2+3*x[0,1]+x[0,1]**2+x[0,2]
g=[
x[0,0]+2*x[0,0]**2+x[0,1]+2*x[0,1]**2+x[0,2],
x[0,0]+x[0,0]**2+x[0,1]+x[0,1]**2-x[0,2],
2*x[0,0]+x[0,0]**2+2*x[0,1]+x[0,2],
x[0,0]+2*x[0,1]**2
]
if g[0]<=100 and g[1]<=500 and g[2]<=400 and g[3]>=10:
if p0<f:
x0=x
p0=f
print('最优解:',x0)
print('最优值:',p0)
time_end=time.time() #计时结束
print('用时:',time_end-time_start)
返回:

到此这篇关于python实现蒙特卡罗模拟法的实践的文章就介绍到这了,更多相关python 蒙特卡罗模拟法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python实现连续变量最优分箱详解--CART算法
关于变量分箱主要分为两大类:有监督型和无监督型 对应的分箱方法: A. 无监督:(1) 等宽 (2) 等频 (3) 聚类 B. 有监督:(1) 卡方分箱法(ChiMerge) (2) ID3.C4.5.CART等单变量决策树算法 (3) 信用评分建模的IV最大化分箱 等 本篇使用python,基于CART算法对连续变量进行最优分箱 由于CART是决策树分类算法,所以相当于是单变量决策树分类. 简单介绍下理论: CART是二叉树,每次仅进行二元分类,对于连续性变量,方法是依次计算相邻两元素值的中位
-
Python实现遗传算法(二进制编码)求函数最优值方式
目标函数 编码方式 本程序采用的是二进制编码精确到小数点后五位,经过计算可知对于 其编码长度为18,对于 其编码长度为15,因此每个基于的长度为33. 参数设置 算法步骤 设计的程序主要分为以下步骤:1.参数设置:2.种群初始化:3.用轮盘赌方法选择其中一半较好的个体作为父代:4.交叉和变异:5.更新最优解:6.对最有个体进行自学习操作:7结果输出.其算法流程图为: 算法结果 由程序输出可知其最终优化结果为38.85029, 输出基因编码为[1 1 0 0 1 0 1 1 1 1 1 1 1 0
-

python实现蒙特卡罗模拟法的实践
目录 1.简介 2.实例分析 2.1模拟求近似圆周率 2.2 估算定积分 2.3 求解整数规划 1.简介 蒙特卡洛又称随机抽样或统计试验,就是产生随机变量,带入模型算的结果,寻优方面,只要模拟次数够多,最终是可以找到最优解或接近最优的解. 通常蒙特卡罗方法可以粗略地分成两类:一类是所求解的问题本身具有内在的随机性,借助计算机的运算能力可以直接模拟这种随机的过程.例如在核物理研究中,分析中子在反应堆中的传输过程.中子与原子核作用受到量子力学规律的制约,人们只能知道它们相互作用发生的概率,却无法准确
-
基于python进行抽样分布描述及实践详解
本次选取泰坦尼克号的数据,利用python进行抽样分布描述及实践. 备注:数据集的原始数据是泰坦尼克号的数据,本次截取了其中的一部分数据进行学习.Age:年龄,指登船者的年龄.Fare:价格,指船票价格.Embark:登船的港口. 1.按照港口分类,使用python求出各类港口数据 年龄.车票价格的统计量(均值.方差.标准差.变异系数等). import pandas as pd df = pd.read_excel('/Users/Downloads/data.xlsx',usecols =
-
python实现蒙特卡罗方法教程
蒙特卡罗方法是一种统计模拟方法,由冯·诺依曼和乌拉姆提出,在大量的随机数下,根据概率估计结果,随机数据越多,获得的结果越精确.下面我们将用python实现蒙特卡罗方法. 1.首先我们做一个简单的圆周率的近似计算,在这个过程中我们要用到随机数,因此需要先使用import numpy as np导入numpy库. 2.代码实现: import numpy as np total = 8000000 count = 0 for i in range(total): x = np.random.rand
-
Python timeit模块的使用实践
Python 中的 timeit 模块可以用来测试一段代码的执行耗时,如一个变量赋值语句的执行时间,一个函数的运行时间等. timeit 模块是 Python 标准库中的模块,无需安装,直接导入就可以使用.导入时直接 import timeit ,可以使用 timeit() 函数和 repeat() 函数,还有 Timer 类.使用 from timeit import ... 时,只能导入 Timer 类(有全局变量 __all__ 限制). timeit 模块的源码总共只有 300 多行,主
-
Python Pytorch学习之图像检索实践
目录 背景 图像表现 搜索 随着电子商务和在线网站的出现,图像检索在我们的日常生活中的应用一直在增加. 亚马逊.阿里巴巴.Myntra等公司一直在大量利用图像检索技术.当然,只有当通常的信息检索技术失败时,图像检索才会开始工作. 背景 图像检索的基本本质是根据查询图像的特征从集合或数据库中查找图像. 大多数情况下,这种特征是图像之间简单的视觉相似性.在一个复杂的问题中,这种特征可能是两幅图像在风格上的相似性,甚至是互补性. 由于原始形式的图像不会在基于像素的数据中反映这些特征,因此我们需要将这些
-
Python利用蒙特卡罗模拟期权定价
目录 期权,及其价值 风险中性估值 模拟资产价格 期权定价 为真实期权定价 完整的模拟 期权是一种合约,它赋予买方在未来某个时间点以特定价格买卖资产的权利. 这些被称为衍生品的合约的交易有多种原因,但一种常见的用法是来对冲当资产价格以不利方式变动,所产生的风险敞口. 期权,即买入或卖出的权利,也是有价格的. Black Scholes 模型描述了一种确定期权公平价格的方法,但还有许多其他方法可以确定价格. 期权,及其价值 欧式期权只有在未来达到预定日期(称为到期日)后才能使用(或行使),可以用字
-
python调用新浪微博API项目实践
因为最近接触到调用新浪微博开放接口的项目,所以就想试试用python调用微博API. SDK下载地址:http://open.weibo.com/wiki/SDK 代码不多十几K,完全可以看懂. 有微博账号可以新建一个APP,然后就可以得到app key和app secret,这个是APP获得OAuth2.0授权所必须的. 了解OAuth2可以查看链接新浪微博的说明. OAuth2授权参数除了需要app key和app secret还需要网站回调地址redirect_uri,并且这个回调地址不允
-
Python中使用支持向量机SVM实践
在机器学习领域,支持向量机SVM(Support Vector Machine)是一个有监督的学习模型,通常用来进行模式识别.分类(异常值检测)以及回归分析. 其具有以下特征: (1)SVM可以表示为凸优化问题,因此可以利用已知的有效算法发现目标函数的全局最小值.而其他分类方法都采用一种基于贪心学习的策略来搜索假设空间,这种方法一般只能获得局部最优解. (2) SVM通过最大化决策边界的边缘来实现控制模型的能力.尽管如此,用户必须提供其他参数,如使用核函数类型和引入松弛变量等. (3)SVM一般
-
Python使用ClickHouse的实践与踩坑记录
目录 1. 关于ClickHouse使用实践 1.1. ClickHouse 应用于数据仓库场景 1.2. 客户端工具DBeaver 1.3. 大数据应用实践 2. Python使用ClickHouse实践 2.1. ClickHouse第三方Python驱动clickhouse_driver 2.2. 实践程序代码 3. 小结一下 操作ClickHouse删除指定数据 ClickHouse是近年来备受关注的开源列式数据库(DBMS),主要用于数据联机分析(OLAP)领域,于2016年开源.目前
-
你眼中的Python大牛 应该都有这份书单
在最新一期的话题中,80%读者认为Python是最好的编程语言,知乎上类似的问题也很多,例如如何入门Python?如何3个月内入门Python?虽然现在可以学习的Python途径很多,但是想要打好牢固的基础知识,系统的学习Python的知识体系,还需要靠阅读专业的书籍来不断积累. 谁会成为AI 和大数据时代的第一开发语言? 这本已是一个不需要争论的问题.如果说三年前,Matlab.Scala.R.Java 和 Python还各有机会,局面尚且不清楚,那么三年之后,趋势已经非常明确了,特别是前两天