python pandas库读取excel/csv中指定行或列数据
目录
- 引言
- 1.根据index查询
- 2.已知数据在第几行找到想要的数据
- 3.根据条件查询找到指定行数据
- 4.找出指定列
- 5.找出指定的行和指定的列
- 6.在规定范围内找出符合条件的数据
- 总结
引言
关键!!!!使用loc函数来查找。
话不多说,直接演示:
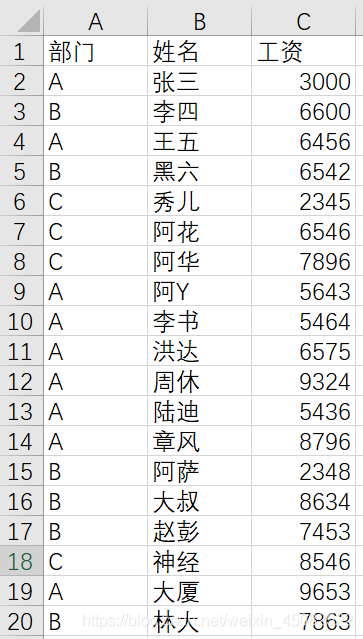
有以下名为try.xlsx表:
1.根据index查询
条件:首先导入的数据必须的有index
或者自己添加吧,方法简单,读取excel文件时直接加index_col
代码示例:
import pandas as pd #导入pandas库 excel_file = './try.xlsx' #导入excel数据 data = pd.read_excel(excel_file, index_col='姓名') #这个的index_col就是index,可以选择任意字段作为索引index,读入数据 print(data.loc['李四'])
打印结果就是
部门 B
工资 6600
Name: 李四, dtype: object
(注意点:索引)
2.已知数据在第几行找到想要的数据
假如我们的表中,有某个员工的工资数据为空了,那我们怎么找到自己想要的数据呢。
代码如下:
for i in data.columns:
for j in range(len(data)):
if (data[i].isnull())[j]:
bumen = data.iloc[j, [0]] #找出缺失值所在的部门
data[i][j] = charuzhi(bumen)
原理很简单,首先检索全部的数据,然后我们可以用pandas中的iloc函数。上面的iloc[j, [2]]中j是具体的位置,【0】是你要得到的数据所在的column
3.根据条件查询找到指定行数据
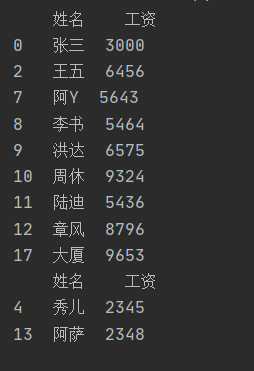
例如查找A部门所有成员的的姓名和工资或者工资低于3000的人:
代码如下:
"""根据条件查询某行数据""" import pandas as pd #导入pandas库 excel_file = './try.xlsx' #导入文件 data = pd.read_excel(excel_file) #读入数据 print(data.loc[data['部门'] == 'A', ['姓名', '工资']]) #部门为A,打印姓名和工资 print(data.loc[data['工资'] < 3000, ['姓名','工资']]) #查找工资小于3000的人
结果如下:
若要把这些数据独立生成excel文件或者csv文件:
添加以下代码
"""导出为excel或csv文件"""
#单条件
dataframe_1 = data.loc[data['部门'] == 'A', ['姓名', '工资']]
#单条件
dataframe_2 = data.loc[data['工资'] < 3000, ['姓名', '工资']]
#多条件
dataframe_3 = data.loc[(data['部门'] == 'A')&(data['工资'] < 3000), ['姓名', '工资']]
#导出为excel
dataframe_1.to_excel('dataframe_1.xlsx')
dataframe_2.to_excel('dataframe_2.xlsx')
4.找出指定列
data['columns'] #columns即你需要的字段名称即可 #注意这列的columns不能是index的名称 #如果要打印index的话就data.index data.columns #与上面的一样
以上全过程用到的库:
pandas,xlrd , openpyxl
5.找出指定的行和指定的列
主要使用的就是函数iloc
data.iloc[:,:2] #即全部行,前两列的数据
逗号前是行,逗号后是列的范围,很容易理解
6.在规定范围内找出符合条件的数据
data.iloc[:10,:][data.工资>6000]
这样即可找出前11行里工资大于6000的所有人的信息了
总结
到此这篇关于python pandas库读取excel/csv中指定行或列数据的文章就介绍到这了,更多相关python pandas库读取行或列内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas 转换成行列表进行读取与Nan处理的方法
pandas中有时需要按行依次对.csv文件读取内容,那么如何进行呢? 我们来完整操作一遍,假设我们已经有了一个.csv文件. # 1.导入包 import pandas as pd # 2读入数据 readFile = pd.read_csv('输出路径',encoding='gb2312') for record in readFile.values: print(record) 至此就完成了整个过程 如果有Nan怎么处理呢? 我们可以在readFile后面加入以下内容: readFile
-
pandas Dataframe行列读取的实例
如下所示: import matplotlib.pyplot as plt import tkinter import numpy as np import pandas as pd from pandas import Series,DataFrame data = {'a':[1,2,3], 'c':[4,5,6], 'b':[7,8,9] } frame = DataFrame(data,index=['one','two','three']) print(frame) print(fra
-
Pandas读取行列数据最全方法
1.读取方法有按行(单行,多行连续,多行不连续),按列(单列,多列连续,多列不连续):部分不连续行不连续列:按位置(坐标),按字符(索引):按块(list):函数有 df.iloc(), df.loc(), df.iat(), df.at(), df.ix(). 2.转换为DF,赋值columns,index,修改添加数据,取行列索引 data = {'省份': ['北京', '上海', '广州', '深圳'], '年份': ['2017', '2018', '2019', '2020'], '
-

python pandas库读取excel/csv中指定行或列数据
目录 引言 1.根据index查询 2.已知数据在第几行找到想要的数据 3.根据条件查询找到指定行数据 4.找出指定列 5.找出指定的行和指定的列 6.在规定范围内找出符合条件的数据 总结 引言 关键!!!!使用loc函数来查找. 话不多说,直接演示: 有以下名为try.xlsx表: 1.根据index查询 条件:首先导入的数据必须的有index 或者自己添加吧,方法简单,读取excel文件时直接加index_col 代码示例: import pandas as pd #导入pandas库 ex
-
python 利用openpyxl读取Excel表格中指定的行或列教程
Worksheet 对象的 rows 属性和 columns 属性得到的是一 Generator 对象,不能用中括号取索引. 可先用列表推导式生成包含每一列中所有单元格的元组的列表,在对列表取索引. Worksheet 的 rows 属性亦可用相同的方法处理. 补充:python之表格数据读取 python 操作excel主要用到xlrd,xlwt这两个库,xlrd,是读取excel表,xlwt是写入表格 1.打开表格 table = xlrd.open("path_to_your_excel&
-
使用python的pandas库读取csv文件保存至mysql数据库
第一:pandas.read_csv读取本地csv文件为数据框形式 data=pd.read_csv('G:\data_operation\python_book\chapter5\\sales.csv') 第二:如果存在日期格式数据,利用pandas.to_datatime()改变类型 data.iloc[:,1]=pd.to_datetime(data.iloc[:,1]) 注意:=号,这样在原始的数据框中,改变了列的类型 第三:查看列类型 print(data.dtypes) 第四:方法一
-
Python Pandas批量读取csv文件到dataframe的方法
PYTHON Pandas批量读取csv文件到DATAFRAME 首先使用glob.glob获得文件路径.然后定义一个列表,读取文件后再使用concat合并读取到的数据. #读取数据 import pandas as pd import numpy as np import glob,os path=r'e:\tj\month\fx1806' file=glob.glob(os.path.join(path, "zq*.xls")) print(file) dl= [] for f i
-
Python读取excel文件中的数据,绘制折线图及散点图
目录 一.导包 二.绘制简单折线 三.pandas操作Excel的行列 四.pandas处理Excel数据成为字典 五.绘制简单折线图 六.绘制简单散点图 一.导包 import pandas as pd import matplotlib.pyplot as plt 二.绘制简单折线 数据:有一个Excel文件lemon.xlsx,有两个表单,表单名分别为:Python 以及student. Python的表单数据如下所示: student的表单数据如下所示: 1.在利用pandas模块进行
-
python pandas库中DataFrame对行和列的操作实例讲解
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是S
-
如何使用pandas读取txt文件中指定的列(有无标题)
最近在倒腾一个txt文件,因为文件太大,所以给切割成了好几个小的文件,只有第一个文件有标题,从第二个开始就没有标题了. 我的需求是取出指定的列的数据,踩了些坑给研究出来了. import pandas as pd # 我们的需求是 取出所有的姓名 # test1的内容 ''' id name score 1 张三 100 2 李四 99 3 王五 98 ''' test1 = pd.read_table("test1.txt") # 这个是带有标题的文件 names = test1[&
-
python实现读取excel文件中所有sheet操作示例
本文实例讲述了python实现读取excel文件中所有sheet操作.分享给大家供大家参考,具体如下: 表格是这样的 实现把此文件所有sheet中 标识为1 的行,取出来,存入一个字典.所有行组成一个列表. # -*- coding: utf-8 -*- from openpyxl import load_workbook def get_data_from_excel(excel_dir):#读取excel,取出所有sheet要执行的接口信息,返回列表 work_book = load_wor
-
Python pandas库中的isnull()详解
问题描述 python的pandas库中有一个十分便利的isnull()函数,它可以用来判断缺失值,我们通过几个例子学习它的使用方法. 首先我们创建一个dataframe,其中有一些数据为缺失值. import pandas as pd import numpy as np df = pd.DataFrame(np.random.randint(10,99,size=(10,5))) df.iloc[4:6,0] = np.nan df.iloc[5:7,2] = np.nan df.iloc[
-
Python读取excel文件中带公式的值的实现
在进行excel文件读取的时候,我自己设置了部分直接从公式获取单元格的值 但是用之前的读取方法进行读取的时候,返回值为空 import os import xlrd from xlutils.copy import copy file_path = os.path.abspath(os.path.dirname(__file__)) # 获取当前文件目录 print(file_path) root_path = os.path.dirname(file_path) # 获取文件上级目录 data