一文搞懂Python中pandas透视表pivot_table功能详解
目录
- 一、概述
- 1.1 什么是透视表?
- 1.2 为什么要使用pivot_table?
- 二、如何使用pivot_table
- 2.1 读取数据
- 2.2Index
- 2.3Values
- 2.4Aggfunc
- 2.5Columns
一文看懂pandas的透视表pivot_table
一、概述
1.1 什么是透视表?
透视表是一种可以对数据动态排布并且分类汇总的表格格式。或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table。
1.2 为什么要使用pivot_table?
- 灵活性高,可以随意定制你的分析计算要求
- 脉络清晰易于理解数据
- 操作性强,报表神器
二、如何使用pivot_table
首先读取数据,数据集是火箭队当家球星James Harden某一赛季比赛数据作为数据集进行讲解。数据地址。
先看一下官方文档中pivot_table的函数体:pandas.pivot_table - pandas 0.21.0 documentation
pivot_table(data,values=None,index=None,columns=None,aggfunc='mean',fill_value=None,margins=False,dropna=True,margins_name='All')
pivot_table有四个最重要的参数index、values、columns、aggfunc,本文以这四个参数为中心讲解pivot操作是如何进行。
2.1 读取数据
- import pandas as pd
- import numpy as np
- df = pd.read_csv('h:/James_Harden.csv',encoding='utf8')
- df.tail()
数据格式如下:
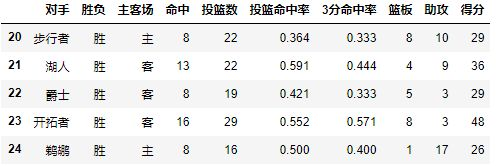
2.2Index
每个pivot_table必须拥有一个index,如果想查看哈登对阵每个队伍的得分,首先我们将对手设置为index:
pd.pivot_table(df,index=[u'对手'])
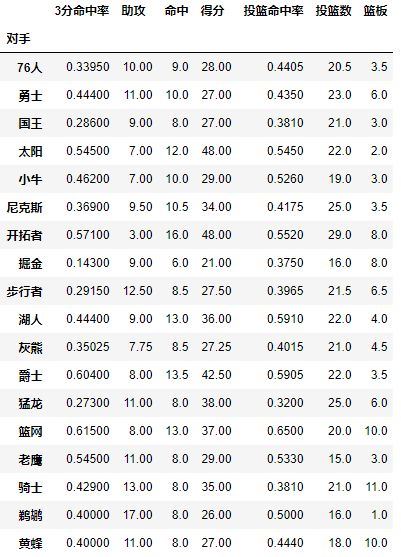
对手成为了第一层索引,还想看看对阵同一对手在不同主客场下的数据,试着将对手与胜负与主客场都设置为index,其实就变成为了两层索引
pd.pivot_table(df,index=[u'对手',u'主客场'])
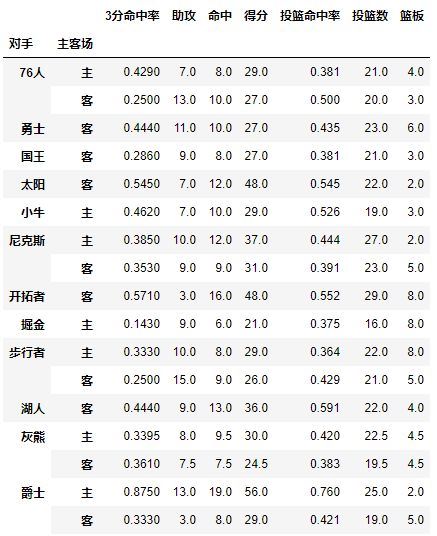
试着交换下它们的顺序,数据结果一样:
pd.pivot_table(df,index=[u'主客场',u'对手'])
看完上面几个操作,Index就是层次字段,要通过透视表获取什么信息就按照相应的顺序设置字段,所以在进行pivot之前你也需要足够了解你的数据。
2.3Values
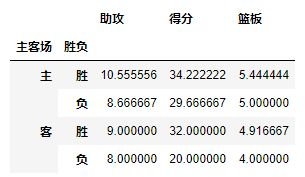
通过上面的操作,我们获取了james harden在对阵对手时的所有数据,而Values可以对需要的计算数据进行筛选,如果我们只需要james harden在主客场和不同胜负情况下的得分、篮板与助攻三项数据:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'])
2.4Aggfunc
aggfunc参数可以设置我们对数据聚合时进行的函数操作。
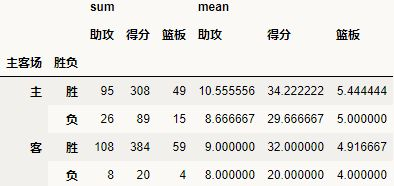
当我们未设置aggfunc时,它默认aggfunc='mean'计算均值。我们还想要获得james harden在主客场和不同胜负情况下的总得分、总篮板、总助攻时:
pd.pivot_table(df,index=[u'主客场',u'胜负'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.sum,np.mean])
2.5Columns
Columns类似Index可以设置列层次字段,它不是一个必要参数,作为一种分割数据的可选方式。
#fill_value填充空值,margins=True进行汇总pd.pivot_table(df,index=[u'主客场'],columns=[u'对手'],values=[u'得分'],aggfunc=[np.sum],fill_value=0,margins=1)

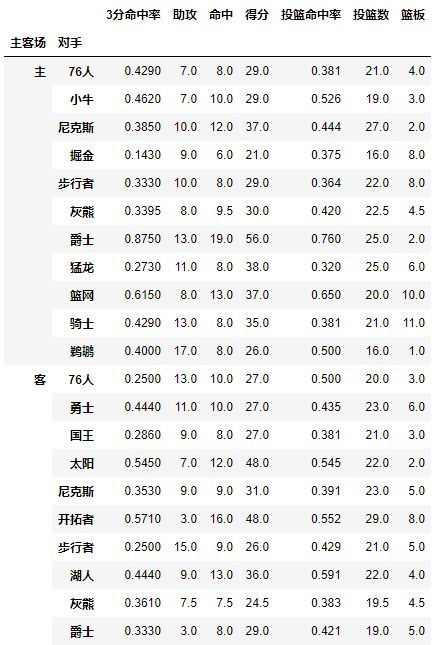
现在我们已经把关键参数都介绍了一遍,下面是一个综合的例子:
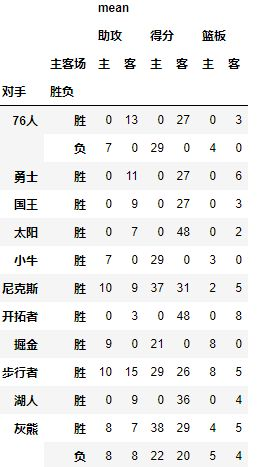
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc=[np.mean],fill_value=0)
结果如下:
aggfunc也可以使用dict类型,如果dict中的内容与values不匹配时,以dict中为准。
table=pd.pivot_table(df,index=[u'对手',u'胜负'],columns=[u'主客场'],values=[u'得分',u'助攻',u'篮板'],aggfunc={u'得分':np.mean,u'助攻':[min, max, np.mean]},fill_value=0)
结果就是助攻求min,max和mean,得分求mean,而篮板没有显示。
到此这篇关于一文搞懂Python中pandas透视表pivot_table功能详解的文章就介绍到这了,更多相关pandas透视表pivot_table内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas 透视表中文字段排序方法
前几天有一个需求,透视表中的年级这一列要按照一年级,二年级这样的序列进行排序,但是用过透视表的人都知道,透视表对中文的排序不是太理想,放弃pandas自带的排序方法.测试了很久,想到一个办法.先把dataframe中需要特殊排序的列中的汉字转换成数字,然后生成透视表,生成透视表之后,再把透视表的index或者columns中的数字替换成相应的汉字,透视表的结果就会按照你想要的顺序进行排序. def get_special_sort_data(self, groupby, columns): #
-
pandas实现excel中的数据透视表和Vlookup函数功能代码
在孩子王实习中做的一个小工作,方便整理数据. 目前这几行代码是实现了一个数据透视表和匹配的功能,但是将做好的结果写入了不同的excel中, 如何实现将结果连续保存到同一个Excel的同一个工作表中? 还需要探索. import pandas as pd import numpy as np a = [1601,1602,1603,1604,1605,1606,1607,1608,1609,1610,1611,1612,1701,1702,1703,1704] for i in a: b = st
-

python 用pandas实现数据透视表功能
透视表是一种可以对数据动态排布并且分类汇总的表格格式.对于熟练使用 excel 的伙伴来说,一定很是亲切! pd.pivot_table() 语法: pivot_table(data, # DataFrame values=None, # 值 index=None, # 分类汇总依据 columns=None, # 列 aggfunc='mean', # 聚合函数 fill_value=None, # 对缺失值的填充 margins=False, # 是否启用总计行/列 dropna=True,
-
Pandas透视表(pivot_table)详解
介绍 也许大多数人都有在Excel中使用数据透视表的经历,其实Pandas也提供了一个类似的功能,名为pivot_table.虽然pivot_table非常有用,但是我发现为了格式化输出我所需要的内容,经常需要记住它的使用语法.所以,本文将重点解释pandas中的函数pivot_table,并教大家如何使用它来进行数据分析. 如果你对这个概念不熟悉,wikipedia上对它做了详细的解释.顺便说一下,你知道微软为PivotTable(透视表)注册了商标吗?其实以前我也不知道.不用说,下面我将讨论
-
一文搞懂Python中pandas透视表pivot_table功能详解
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
一文搞懂Python中pandas透视表pivot_table功能
目录 一.概述 1.1 什么是透视表? 1.2 为什么要使用pivot_table? 二.如何使用pivot_table 2.1 读取数据 2.2Index 2.3Values 2.4Aggfunc 2.5Columns 一文看懂pandas的透视表pivot_table 一.概述 1.1 什么是透视表? 透视表是一种可以对数据动态排布并且分类汇总的表格格式.或许大多数人都在Excel使用过数据透视表,也体会到它的强大功能,而在pandas中它被称作pivot_table. 1.2 为什么要使用
-
一文搞懂Python中Pandas数据合并
目录 1.concat() 主要参数 示例 2.merge() 参数 示例 3.append() 参数 示例 4.join() 示例 数据合并是数据处理过程中的必经环节,pandas作为数据分析的利器,提供了四种常用的数据合并方式,让我们看看如何使用这些方法吧! 1.concat() concat() 可用于两个及多个 DataFrame 间行/列方向进行内联或外联拼接操作,默认对行(沿 y 轴)取并集. 使用方式 pd.concat( objs: Union[Iterable[~FrameOr
-
一文搞懂Python中列表List和元组Tuple的使用
目录 列表 List 列表是有序的 列表可以包含任意对象 通过索引访问列表元素 列表嵌套 列表可变 元组 Tuple 定义和使用元组 元素对比列表的优点 元组分配.打包和解包 List 与 Tuple 的区别 列表 List 列表是任意对象的集合,在 Python 中通过逗号分隔的对象序列括在方括号 ( [] ) 中 people_list = ['曹操', '曹丕', '甄姫', '蔡文姫'] print(people_list) ['曹操', '曹丕', '甄姫', '蔡文姫'] peopl
-
一文搞懂Python中的进程,线程和协程
目录 1.什么是并发编程 2.进程与多进程 3.线程与多线程 4.协程与多协程 5.总结 1.什么是并发编程 并发编程是实现多任务协同处理,改善系统性能的方式.Python中实现并发编程主要依靠 进程(Process):进程是计算机中的程序关于某数据集合的一次运行实例,是操作系统进行资源分配的最小单位 线程(Thread):线程被包含在进程之中,是操作系统进行程序调度执行的最小单位 协程(Coroutine):协程是用户态执行的轻量级编程模型,由单一线程内部发出控制信号进行调度 直接上一张图看看
-
一文搞懂Python中subprocess模块的使用
目录 简介 常用方法和接口 subprocess.run()解析 subprocess.Popen()解析 Popen 对象方法 subprocess.run()案例 subprocess.call()案例 subprocess.check_call()案例 subprocess.getstatusoutput()案例 subprocess.getoutput()案例 subprocess.check_output()案例 subprocess.Popen()综合案例 简介 subprocess
-
一文搞懂Python中is和==的区别
目录 ==比较操作符和is同一性运算符区别 哪些情况下is和==结果是完全相同的? 为什么256时相同, 而1000时不同? 结论 ==比较操作符和is同一性运算符区别 哪些情况下is和==结果是完全相同的? 结论 在Python中一切都是对象. Python中对象包含的三个基本要素,分别是:id(身份标识).type(数据类型)和value(值).对象之间比较是否相等可以用==,也可以用is. is和==都是对对象进行比较判断作用的,但对对象比较判断的内容并不相同.下面来看看具体区别在哪? i
-
Python制作数据分析透视表的方法详解
目录 1.pivot_table函数index属性 2.pivot_table函数values属性 3.pivot_table函数aggfunc属性 4.pivot_table函数columns属性 透视表是一种可以对数据动态排布并且分类汇总的表格格式,在常用的python的数据分析非标准库pandas中体现为pivot_table模块. pivot_table数据透视表可以灵活的定制数据分析需求进行汇总,当然在Excel办公操作中早就存在了数据透视表的工具.如今,数据透视表被应用在python
-
一文搞懂python 中的迭代器和生成器
可迭代对象和迭代器 迭代(iterate)意味着重复,就像 for 循环迭代序列和字典那样,但实际上也可使用 for 循环迭代其他对象:实现了方法 __iter__ 的对象(迭代器协议的基础).__iter__方法返回一个迭代器,它是包含方法 __next__ 的对象,调用时可不提供任何参数:当你调用 __next__ 时,迭代器应返回其下一个值:如果没有可供返回的值,应引发 StopIteration 异常:也可使用内置函数 next(),此种情况下,next(it) 与 it.__next(
-
一文带你搞懂Python中的文件操作
目录 一.文件的编码 二.文件的读取 2.1 open()打开函数 2.2 mode常用的三种基础访问模式 2.3 读操作相关方法 三.文件的写入 写操作快速入门 四.文件的追加 追加写入操作快速入门 五.文件操作综合案例 一.文件的编码 计算机中有许多可用编码: UTF-8 GBK Big5 等 UTF-8是目前全球通用的编码格式 除非有特殊需求,否则,一律以UTF-8格式进行文件编码即可. 二.文件的读取 2.1 open()打开函数 注意:此时的f是open函数的文件对象,对象是Pytho