TensorFlow人工智能学习张量及高阶操作示例详解
目录
- 一、张量裁剪
- 1.tf.maximum/minimum/clip_by_value()
- 2.tf.clip_by_norm()
- 二、张量排序
- 1.tf.sort/argsort()
- 2.tf.math.topk()
- 三、TensorFlow高阶操作
- 1.tf.where()
- 2.tf.scatter_nd()
- 3.tf.meshgrid()
一、张量裁剪
1.tf.maximum/minimum/clip_by_value()
该方法按数值裁剪,传入tensor和阈值,maximum是把数据中小于阈值的变成阈值。minimum是把数据中大于阈值的变成阈值。clip_by_value需要传入两个阈值,会把数据裁剪到阈值中间。

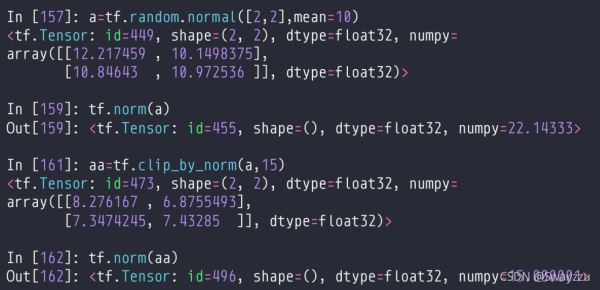
2.tf.clip_by_norm()
按范数裁剪,传入tensor和新的范数。通过裁剪范数,可以进行等比例放缩,使得梯度方向不变,但数值变小。通过这个方法可以对梯度进行裁剪,一次性对所有的参数的范数进行裁剪,并且保留方向。防止梯度爆炸,梯度弥散。
二、张量排序
1.tf.sort/argsort()
这两个方法分别返回排序后的值,排序后的索引。有索引之后,可以通过gather方法对数据排序。
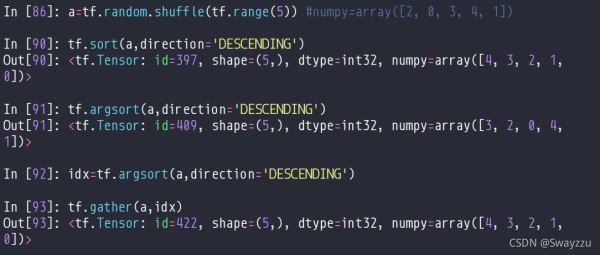
对于多维tensor,不指定轴的时候,默认是对最后一个轴操作。

2.tf.math.topk()
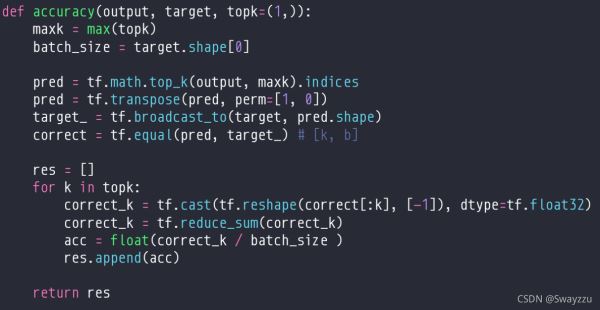
返回前k大的那些数据,以及索引。比如下面的例子,传入a,2的意思是前两个大的值。因此会对每一行,寻找前两大的数,以及对应的索引,存到返回值中。

可以通过这个规则,求解topk的准确率。比如下面的例子,对于两条数据,预测概率是prob,根据预测概率,得到这两条数据最大值索引是2,1,而实际的值target是2,0。
①通过tf.math.top_k方法,对预测的概率进行排序,让它返回前三大的值。并得到索引。
②将索引进行转置之后,可以方便地阅读:第一列就是第一条数据的预测值概率索引排序,第二列就是第二条数据的预测值概率索引排序。
③那么,对于两条数据top1的准确率,就是概率最大的索引,也就是第一行的两个数据,2,1,而实际值是2,0,那么top1准确率就是50%
④top2的准确率,意思就是,只要前两名的概率预测有对的,那就算预测对了。那么第一行,第一条预测对了,第二条预测错了。而第二行,第一条预测错了,第二条预测对了。
⑤那么,根据“只要前两个概率有一个对,那就算对”,top2的准确率就是100%

三、TensorFlow高阶操作
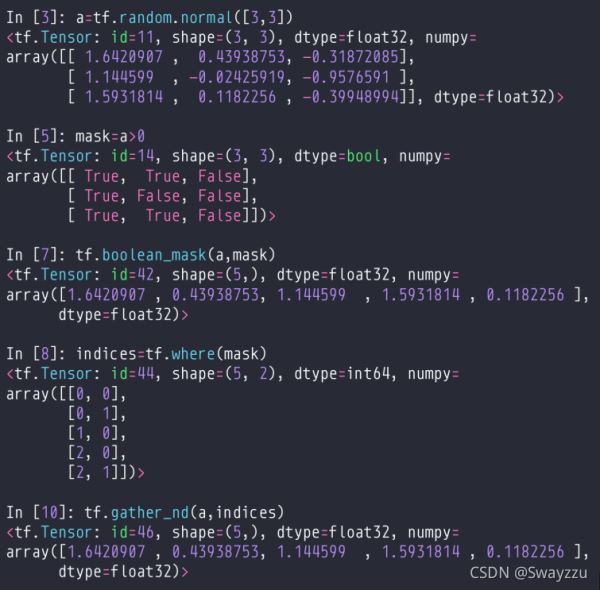
1.tf.where()
如果传入布尔型数据,会根据数据返回值为True的数值的索引。
如果传入条件数据,比如where(condition, A, B),condition是一个布尔tensor,会从A里面选择condition为true的位置所对应的数据,从B里面选择conditon为false的位置所对应的数据。

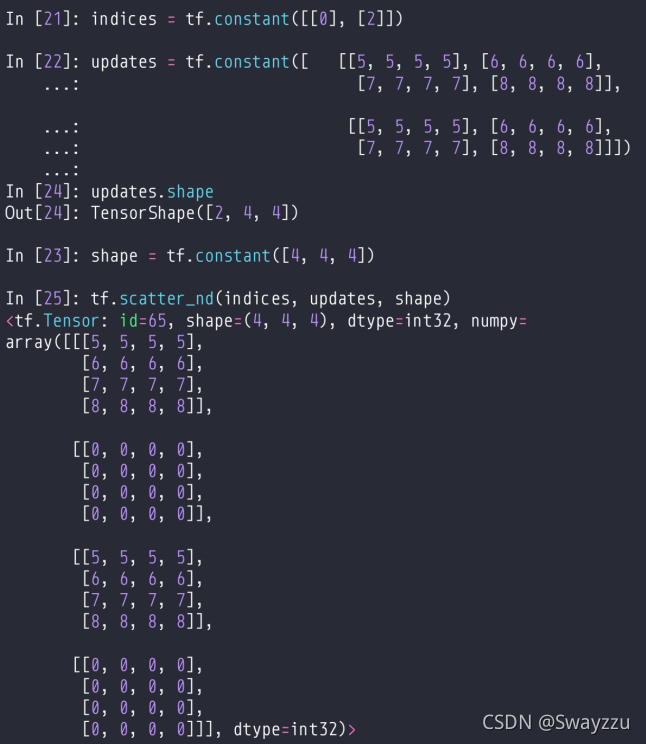
2.tf.scatter_nd()
该方法中,传入索引,数据,底板。
底板通常是全0的tensor,索引是和数据一一对应的,并且索引的长度不超过底板。
传入的每一个数据都对应一个索引,然后把数据更新到底板上面索引对应的位置。

如果底板已经有数据了,就需要全部清零,再更新。
在二维上面举例如下:
3.tf.meshgrid()
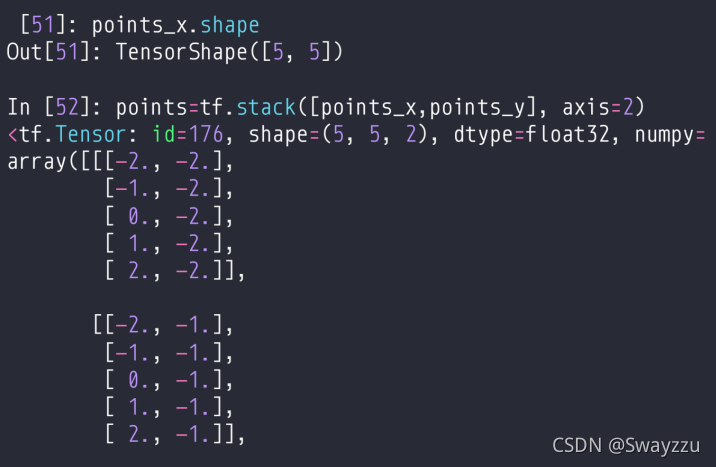
和numpy里面的meshgrid用法一样,分别生成的是网格中x和y的数据。例子如下:

然后使用stack进行一个堆叠,就可以得到所有25个点的坐标。
以上就是TensorFlow人工智能学习张量及高阶操作示例详解的详细内容,更多关于TensorFlow张量高阶操作的资料请关注我们其它相关文章!
相关推荐
-
tensorflow实现对张量数据的切片操作方式
如下所示: import tensorflow as tf a=tf.constant([[[1,2,3,4],[4,5,6,7],[7,8,9,10]], [[11,12,13,14],[20,21,22,23],[15,16,17,18]]]) print(a.shape) b,c=tf.split(a,2,0) #参数1.张量 2.获得的切片数 3.切片的维度 将两个切片分别赋值给b,c print(b.shape) print(c.shape with tf.Session() as s
-
tensorflow 中对数组元素的操作方法
tensorflow中对tensor对象进行像numpy数组一样便捷的操作是不可能的, 至少对1.2以及之前的版本而言. 从issue上看到,有不少人希望tensorflow能及早实现这些操作,但近期来看是不太可能了. 但是,这样的操作的确可以实现. 下面我来向大家介绍几种常用的操作,以及其在tensorflow中的实现方式. 我的代码仅仅是抛砖引玉吧. 谁有更好的方法就放在评论中分享给大家吧. 预先给那个人点个赞. 1.在tensor对象中提取某一行. 2.将tensor中的某一行进行赋值.
-

TensorFlow2基本操作之 张量排序 填充与复制 查找与替换
目录 张量排序 tf.sort tf.argsort tf.math.top_k 填充与复制 tf.pad tf.tile 查找与替换 tf.where (第一种) tf.where (第二种) tf.scatter_nd 张量排序 tf.sort tf.sort函数可以帮我们对张量进行排序. 格式: tf.sort( values, axis=-1, direction='ASCENDING', name=None ) 参数: values: 要进行排序的张量 axis: 操作维度 direc
-
Tensorflow--取tensorf指定列的操作方式
我就废话不多说了,大家还是直接看代码吧~ In [1]: import os In [2]: os.environ["CUDA_VISIBLE_DEVICES"] = "0" In [3]: import tensorflow as tf In [4]:sess =tf.Session() In [5]: input = tf.constant([[[1,2,3],[4,5,6],[7,8,9]],[[10,11,12],[13,14,15],[1 ...: 6,1
-
tensorflow多维张量计算实例
两个三维矩阵的乘法怎样计算呢?我通过实验发现,tensorflow把前面的维度当成是batch,对最后两维进行普通的矩阵乘法.也就是说,最后两维之前的维度,都需要相同. 首先计算shape为(2, 2, 3)乘以shape为(2, 3, 2)的张量. import tensorflow as tf import numpy as np a = tf.constant(np.arange(1, 13, dtype=np.float32), shape=[2, 2, 3]) b = tf.const
-
TensorFlow人工智能学习张量及高阶操作示例详解
目录 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 2.tf.clip_by_norm() 二.张量排序 1.tf.sort/argsort() 2.tf.math.topk() 三.TensorFlow高阶操作 1.tf.where() 2.tf.scatter_nd() 3.tf.meshgrid() 一.张量裁剪 1.tf.maximum/minimum/clip_by_value() 该方法按数值裁剪,传入tensor和阈值,maximum是把数
-
人工智能学习Pytorch数据集分割及动量示例详解
目录 1.数据集分割 2.正则化 3.动量和学习率衰减 1.数据集分割 通过datasets可以直接分别获取训练集和测试集. 通常我们会将训练集进行分割,通过torch.utils.data.random_split方法. 所有的数据都需要通过torch.util.data.DataLoader进行加载,才可以得到可以使用的数据集. 具体代码如下: 2. 2.正则化 PyTorch中的正则化和机器学习中的一样,不过设置方式不一样. 直接在优化器中,设置weight_decay即可.优化器中,默认
-
人工智能学习pyTorch的ResNet残差模块示例详解
目录 1.定义ResNet残差模块 ①各层的定义 ②前向传播 2.ResNet18的实现 ①各层的定义 ②前向传播 3.测试ResNet18 1.定义ResNet残差模块 一个block中,有两个卷积层,之后的输出还要和输入进行相加.因此一个block的前向流程如下: 输入x→卷积层→数据标准化→ReLU→卷积层→数据标准化→数据和x相加→ReLU→输出out 中间加上了数据的标准化(通过nn.BatchNorm2d实现),可以使得效果更好一些. ①各层的定义 ②前向传播 在前向传播中输入x,过
-
Python测试框架pytest高阶用法全面详解
目录 前言 1.pytest安装 1.1安装 1.2验证安装 1.3pytest文档 1.4 Pytest运行方式 1.5 Pytest Exit Code 含义清单 1.6 如何获取帮助信息 1.7 控制测试用例执行 1.8 多进程运行cases 1.9 重试运行cases 1.10 显示print内容 2.Pytest的setup和teardown函数 函数级别setup()/teardown() 类级别 3.Pytest配置文件 4 Pytest常用插件 4.1 前置条件: 4.2 Pyt
-
Python中常用的高阶函数实例详解
前言 高阶函数指的是能接收函数作为参数的函数或类:python中有一些内置的高阶函数,在某些场合使用可以提高代码的效率. lambda 当在使用一些函数的时候,我们不需要显式定义函数名称,直接传入lambda匿名函数即可.lambda匿名函数通常和其他函数搭配使用. 比如可以直接使用如下的lambda表达式计算当x=3时,y = x * 3 + 5的函数值. In [1]: (lambda x: x * 3 + 5)(3) Out[1]: 14 map map函数将一个函数和序列/迭代器(可以传
-
Pandas读存JSON数据操作示例详解
目录 引言 读取json数据 模拟数据 参数orident orident="split" orient="records" orient="index" orient="columns" orient="values" to_json 引言 本文介绍的如何使用Pandas来读取各种json格式的数据,以及对json数据的保存 读取json数据 使用的是pd.read_json函数,见官网:pandas.p
-
go语言结构体指针操作示例详解
目录 指针 go指针操作 不能操作不合法指向 new函数 指针做函数的参数 数组指针 结构体指针变量 结构体成员普通变量 结构体成员指针变量 结构体比较和赋值 结构体作为函数参数 指针 指针是代表某个内存地址的值.内存地址储存另一个变量的值. 指针(地址),一旦定义了不可改变,指针指向的值可以改变 go指针操作 1.默认值nil,没有NULL常量 2.操作符“&”取变量地址,“*“通过指针(地址)访问目标对象(指向值) 3.不支持指针运算,不支持“->”(箭头)运算符,直接用“.”访问目标成
-
GO文件创建及读写操作示例详解
目录 三种文件操作比较 ioutil ioutil.ReadFile读 ioutil.WriteFile 写 ioutil.ReadAll 读 ioutil.ReadDir 查看路径下目录信息 ioutil.TempDir 创建临时目录 ioutil.TempFile 创建临时文件 os.file 方法 os.OpenFile() 创建文件 写入数据三种方式 第一种-WriteString( )函数 第二种-Write( )函数 第三种-WriteAt( )函数 读取文件 Read 读取文件 按
-
Python获取时间的操作示例详解
目录 获得当前时间时间戳 获取当前时间 获取昨天日期 生成日历 计算每个月天数 计算3天前并转换为指定格式 获取时间戳的旧时间 获取时间并指定格式 pandas 每日一练 21读取本地EXCEL数据 22查看df数据前5行 23将popularity列数据转换为最大值与最小值的平均值 24将数据根据project进行分组并计算平均分 25将test_time列具体时间拆分为两部分(一半日期,一半时间) 获得当前时间时间戳 # 注意时区的设置 import time # 获得当前时间时间戳 now
-
Go语言学习教程之结构体的示例详解
目录 前言 可导出的标识符 嵌入字段 提升 标签 结构体与JSON相互转换 结构体转JSON JSON转结构体 练习代码步骤 前言 结构体是一个序列,包含一些被命名的元素,这些被命名的元素称为字段(field),每个字段有一个名字和一个类型. 结构体用得比较多的地方是声明与数据库交互时需要用到的Model类型,以及与JSON数据进行相互转换.(当然,项目中任何需要多种数据结构组合在一起使用的地方,都可以选择用结构体) 代码段1:声明一个待办事项的Model类型: type Todo struct