pandas如何删除没有列名的列浅析
实际工作中,偶尔遇到如下情况,例如使用Pandas计算如下相关系数,并把结果写入Excel文件中。
correlations = df.corr(method='pearson',min_periods=1) #计算特征之间的相关系数矩阵
correlations.to_excel('dcorr202002.xlsx')
当再次读取Excel文件时,出现了没有列名的列。
import pandas as pd
correlations= pd.read_excel('dcorr202002.xlsx')
correlations
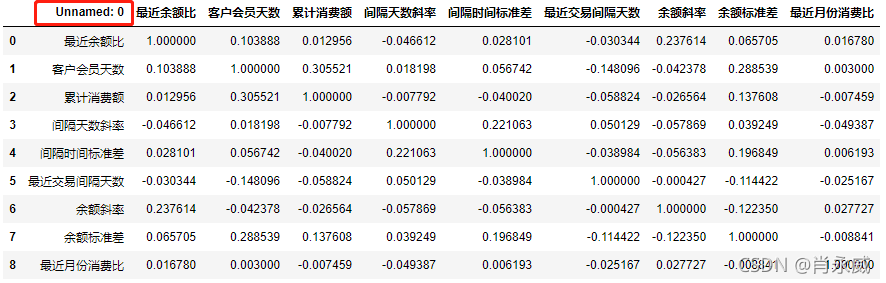
没有列名一般是说原表中没有列名,但在pandas读出来的时候是有列名的,一般的命名规则为:
Unnamed:x
x-表示未命名或重名的第x个列。
如何删除这个没有列名的列呢?
方法一:通过筛选列的方式,留存正常的列。
print(correlations.columns)
col = correlations.columns.tolist()
col.remove('Unnamed: 0')
print(col)
correlations1 = correlations[col]
correlations1
Index(['Unnamed: 0', '最近余额比', '客户会员天数', '累计消费额', '间隔天数斜率', '间隔时间标准差',
'最近交易间隔天数', '余额斜率', '余额标准差', '最近月份消费比'],
dtype='object')
['最近余额比', '客户会员天数', '累计消费额', '间隔天数斜率', '间隔时间标准差', '最近交易间隔天数',
'余额斜率', '余额标准差', '最近月份消费比']
方法二:直接删除列。
correlations2 = correlations.drop(columns='Unnamed: 0')correlations2结果同上,略。
相关推荐
-
pandas删除行删除列增加行增加列的实现
创建df: >>> df = pd.DataFrame(np.arange(16).reshape(4, 4), columns=list('ABCD'), index=list('1234')) >>> df A B C D 1 0 1 2 3 2 4 5 6 7 3 8 9 10 11 4 12 13 14 15 1,删除行 1.1,drop 通过行名称删除: df = df.drop(['1', '2']) # 不指定axis默认为0 df.drop(['1',
-
Python Pandas 对列/行进行选择,增加,删除操作
一.列操作 1.1 选择列 d = {'one' : pd.Series([1, 2, 3], index=['a', 'b', 'c']), 'two' : pd.Series([1, 2, 3, 4], index=['a', 'b', 'c', 'd'])} df = pd.DataFrame(d) print (df ['one']) # 选择其中一列进行显示,列长度为最长列的长度 # 除了 index 和 数据,还会显示 列表头名,和 数据 类型 运行结果: a 1.0 b
-

pandas如何删除没有列名的列浅析
实际工作中,偶尔遇到如下情况,例如使用Pandas计算如下相关系数,并把结果写入Excel文件中. correlations = df.corr(method='pearson',min_periods=1) #计算特征之间的相关系数矩阵 correlations.to_excel('dcorr202002.xlsx') 当再次读取Excel文件时,出现了没有列名的列. import pandas as pd correlations= pd.read_excel('dcorr202002.xl
-
Python中pandas dataframe删除一行或一列:drop函数详解
用法:DataFrame.drop(labels=None,axis=0, index=None, columns=None, inplace=False) 在这里默认:axis=0,指删除index,因此删除columns时要指定axis=1: inplace=False,默认该删除操作不改变原数据,而是返回一个执行删除操作后的新dataframe: inplace=True,则会直接在原数据上进行删除操作,删除后就回不来了. 例子: >>>df = pd.DataFrame(np.a
-
Pandas.DataFrame删除指定行和列(drop)的实现
目录 DataFrame指定的行删除 按行名指定(行标签) 按行号指定 未设置行名的注意事项 DataFrame指定的列删除 按列名指定(列标签) 按列号指定 多行多列的删除 使用drop()方法删除pandas.DataFrame的行和列. 在0.21.0版之前,请使用参数labels和axis指定行和列.从0.21.0开始,可以使用index或columns. 在此,将对以下内容进行说明. DataFrame指定的行删除 按行名指定(行标签) 按行号指定 未设置行名的注意事项 DataFra
-
pandas.DataFrame删除/选取含有特定数值的行或列实例
1.删除/选取某列含有特殊数值的行 import pandas as pd import numpy as np a=np.array([[1,2,3],[4,5,6],[7,8,9]]) df1=pd.DataFrame(a,index=['row0','row1','row2'],columns=list('ABC')) print(df1) df2=df1.copy() #删除/选取某列含有特定数值的行 #df1=df1[df1['A'].isin([1])] #df1[df1['A'].
-
python pandas数据处理之删除特定行与列
目录 dropna() 方法过滤任何含有缺失值的行 方法一:dropna() 其他参数解析 方法二:替换并删除,Python pandas 如果某列值为空,过滤删除所在行数据 总结 dropna() 方法过滤任何含有缺失值的行 pandas.DataFrame里,如果一行数据有任意值为空,则过滤掉整行,这时候使用dropna()方法是合适的.下面的案例,任意列只要有一个为空数据,则整行都干掉.但是我们常常遇到的情况,是根据一个指标(一列)数据的情况,去过滤行数据,类似Excel里面的过滤漏斗,怎
-
Pandas标记删除重复记录的方法
Pandas提供了duplicated.Index.duplicated.drop_duplicates函数来标记及删除重复记录 duplicated函数用于标记Series中的值.DataFrame中的记录行是否是重复,重复为True,不重复为False pandas.DataFrame.duplicated(self, subset=None, keep='first') pandas.Series.duplicated(self, keep='first') 其中参数解释如下: subse
-
python pandas库中DataFrame对行和列的操作实例讲解
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是S
-
python中pandas库中DataFrame对行和列的操作使用方法示例
用pandas中的DataFrame时选取行或列: import numpy as np import pandas as pd from pandas import Sereis, DataFrame ser = Series(np.arange(3.)) data = DataFrame(np.arange(16).reshape(4,4),index=list('abcd'),columns=list('wxyz')) data['w'] #选择表格中的'w'列,使用类字典属性,返回的是S
-
pandas通过loc生成新的列方法
pandas中一个很便捷的使用方法通过loc.iloc.ix等索引方式,这里记录一下: df.loc[条件,新增列] = 赋初始值 如果新增列名为已有列名,则在原来的数据列上改变 import pandas as pd import numpy as np data = pd.DataFrame(np.random.randint(0,100,40).reshape(10,4),columns=list('abcd')) print(data) data.loc[data.d >= 50,'大于
-
Pandas缺失值删除df.dropna()的使用
函数参数 函数形式:dropna(axis=0, how=‘any’, thresh=None, subset=None, inplace=False) 参数: axis:0或’index’,表示按行删除:1或’columns’,表示按列删除. how:‘any’,表示该行/列只要有一个以上的空值,就删除该行/列:‘all’,表示该行/列全部都为空值,就删除该行/列. thresh:int型,默认为None.如果该行/列中,非空元素数量小于这个值,就删除该行/列. subset:子集.列表,按c