Python 更快进行探索性数据分析的四个方法
大家好,常用探索性数据分析方法很多,比如常用的 Pandas DataFrame 方法有 .head()、.tail()、.info()、.describe()、.plot() 和 .value_counts()。
import pandas as pd
import numpy as np
df = pd.DataFrame( {
"Student" : ["Mike", "Jack", "Diana", "Charles", "Philipp", "Charles", "Kale", "Jack"] ,
"City" : ["London", "London", "Berlin", "London", "London", "Berlin", "London", "Berlin"] ,
"Age" : [20, 40, 18, 24, 37, 40, 44, 20 ],
"Maths_Score" : [84, 80, 50, 36, 44, 24, 41, 35],
"Science_Score" : [66, 83, 51, 35, 43, 58, 71, 65]} )
df
在 Pandas 中创建 groupby() 对象
在许多情况下,我们希望将数据集拆分为多个组并对这些组进行处理。 Pandas 方法 groupby() 用于将 DataFrame 中的数据分组。
与其一起使用 groupby() 和聚合方法,不如创建一个 groupby() 对象。 理想的情况是,我们可以在需要时直接使用此对象。
让我们根据列“City”将给定的 DataFrame 分组
df_city_group = df.groupby("City")
我们创建一个对象 df_city_group,该对象可以与不同的聚合相结合,例如 min()、max()、mean()、describe() 和 count()。 一个例子如下所示。
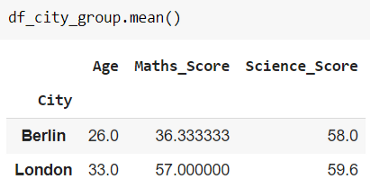
要获取“City”是Berlin的 DataFrame 子集,只需使用方法 .get_group()

这不需要为每个组创建每个子 DataFrame 的副本,比较节省内存。
另外,使用 .groupby() 进行切片比常规方法快 2 倍!!

使用 .nlargest()
通常,我们根据特定列的值了解 DataFrame 的 Top 3 或 Top 5 数据。例如,从考试中获得前 3 名得分者或从数据集中获得前 5 名观看次数最多的电影。使用 Pandas .nlargest() 是最简单的方式。
df.nlargest(N, column_name, keep = ‘first' )
使用 .nlargest() 方法,可以检索包含指定列的 Top ‘N' 值的 DataFrame 行。
在上面的示例中,让我们获取前 3 个“Maths_Score”的 DataFrame 的行。
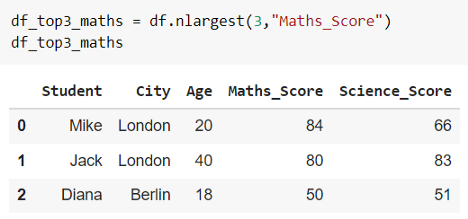
如果两个值之间存在联系,则可以修改附加参数和可选参数。 它需要值“first”、“last”和“all”来检索领带中的第一个、最后一个和所有值。这种方法的优点是,你不需要专门对 DataFrame 进行排序。
使用 .nsmallest()
与Top 3 或5 类似,有时我们也需要DataFrame 中的Last 5 条记录。例如,获得评分最低的 5 部电影或考试中得分最低的 5 名学生。使用 Pandas .nsmallest() 是最简单的方式
df.nsmallestst(N, column_name, keep = ‘first' )
使用 .nsmallest() 方法,可以检索包含指定列的底部“N”个值的 DataFrame 行。
在同一个示例中,让我们获取 DataFrame“df”中“Maths_Score”最低的 3 行。
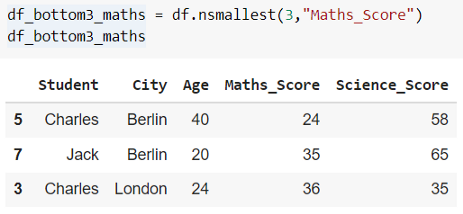
逻辑比较
比较运算符 <、>、<=、>=、==、!= 及其包装器 .lt()、.gt()、.le()、.ge()、.eq() 和 .ne() 分别在以下情况下非常方便将 DataFrame 与基值进行比较,这种比较会产生一系列布尔值,这些值可用作以后的指标。
- 基于比较对 DataFrame 进行切片
- 可以基于与值的比较从 DataFrame 中提取子集。
- 根据两列的比较在现有 DataFrame 中创建一个新列。
所有这些场景都在下面的示例中进行了解释
# 1. Comparing the DataFrame to a base value # Selecting the columns with numerical values only df.iloc[:,2:5].gt(50) df.iloc[:,2:5].lt(50) # 2. Slicing the DataFrame based on comparison # df1 is subset of df when values in "Maths_Score" column are not equal or equal to '35' df1 = df[df["Maths_Score"].ne(35)] df2 = df[df["Maths_Score"].eq(35)] # 3. Creating new column of True-False values by comparing two columns df["Maths_Student"] = df["Maths_Score"].ge(df["Science_Score"]) df["Maths_Student_1"] = df["Science_Score"].le(df["Maths_Score"])
总结
在使用 Python 进行数据分析时,我发现这些方法非常方便,它确实让数据分析变得更快。欢迎大家尝试这些,如果你有那些更棒的方法,欢迎评论区留言!
技术交流
欢迎转载、收藏、有所收获点赞支持一下!

到此这篇关于Python 更快进行探索性数据分析的四个方法的文章就介绍到这了,更多相关Python 数据分析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python 数据分析之Beautiful Soup 提取页面信息
概述 数据分析 (Data Analyze) 可以在工作中的各个方面帮助我们. 本专栏为量化交易专栏下的子专栏, 主要讲解一些数据分析的基础知识. Beautiful Soup Beautiful 是一个可以从 HTML 或 XML 文件中提取数据的 Pyhton 库. 简单来说, 它能将 HTML 的标签文件解析成树形结构, 然后方便的获取到指定标签的对应属性. 安装: pip install beautifulsoup4 例子: from bs4 import BeautifulSoup #
-
Python中的探索性数据分析(功能式)
这里有一些技巧来处理日志文件提取.假设我们正在查看一些Enterprise Splunk提取.我们可以用Splunk来探索数据.或者我们可以得到一个简单的提取并在Python中摆弄这些数据. 在Python中运行不同的实验似乎比试图在Splunk中进行这种探索性的操作更有效.主要是因为我们可以无所限制地对数据做任何事.我们可以在一个地方创建非常复杂的统计模型. 理论上,我们可以在Splunk中做很多的探索.它有各种报告和分析功能. 但是... 使用Splunk需要假设我们知道我们正在寻找什么.在
-
Python Sweetviz轻松实现探索性数据分析
Sweetviz 是一个开源 Python 库,它只需三行代码就可以生成漂亮的高精度可视化效果来启动EDA(探索性数据分析).输出一个HTML.文末提供技术交流群,喜欢点赞支持,收藏. 如上图所示,它不仅能根据性别.年龄等不同栏目纵向分析数据,还能对每个栏目做众数.最大值.最小值等横向对比. 所有输入的数值.文本信息都会被自动检测,并进行数据分析.可视化和对比,最后自动帮你进行总结,是一个探索性数据分析的好帮手. 1.准备 请选择以下任一种方式输入命令安装依赖: 1. Windows 环境 打开
-
Python数据分析之Numpy库的使用详解
目录 前言
-
Python数据分析JupyterNotebook3魔法命令详解及示例
目录 1.魔法命令介绍 %lsmagic:列出所有magics命令 %quickref:输出所有魔法指令的简单版帮助文档 %Magics_Name?:输出某个魔法命令详细帮助文档 2.Line magics:Line魔法指令 3.Cell magics:Cell魔法指令 写bash程序 写perl程序 1.魔法命令介绍 %lsmagic:列出所有magics命令 Available line magics:[对当前行使用共计93个] %alias %alias_magic %autoawait
-
利用python数据分析处理进行炒股实战行情
作为一个新手,你需要以下3个步骤: 1.用户注册 > 2.获取token > 3.调取数据 数据内容: 包含股票.基金.期货.债券.外汇.行业大数据, 同时包括了数字货币行情等区块链数据的全数据品类的金融大数据平台, 为各类金融投资和研究人员提供适用的数据和工具. 1.数据采集 我们进行本地化计算,首先要做的,就是将所需的基础数据采集到本地数据库里 本篇的示例源码采用的数据库是MySQL5.5,数据源是xxx pro接口. 我们现在要取一批特定股票的日线行情 部分代码如下: # 设置xxxxx
-
Python Pandas数据分析之iloc和loc的用法详解
Pandas 是一套用于 Python 的快速.高效的数据分析工具.它可以用于数据挖掘和数据分析,同时也提供数据清洗功能.本篇目录如下: 一.iloc 1.定义 iloc索引器用于按位置进行基于整数位置的索引或者选择. 2.语法 df.iloc [row selection, column selection] 3.代码示例 (1)导入数据 (2)选择单行或单列 (3)选择多行或多列 (4)注意 iloc选择一行时返回Series,选择多行返回DataFrame,通过传递列表可转为DataFra
-
Python 更快进行探索性数据分析的四个方法
大家好,常用探索性数据分析方法很多,比如常用的 Pandas DataFrame 方法有 .head()..tail()..info()..describe()..plot() 和 .value_counts(). import pandas as pd import numpy as np df = pd.DataFrame( { "Student" : ["Mike", "Jack", "Diana", "Cha
-
python中list列表删除元素的四种方法实例
目录 在python列表中删除元素主要分为以下3种场景: del:根据索引值删除元素 pop():根据索引值删除元素 remove():根据元素值进行删除 clear():删除所有元素 补充: 删除元素的变相方法 总结 在python列表中删除元素主要分为以下3种场景: 根据目标元素所在的索引位置进行删除,可以使用del关键字或pop()方法: 根据元素本身的值进行删除,可使用列表(list类型)提供的remove()方法: 将列表中所有元素全部删除,可使用列表(list类型)提供的clear(
-
Python交换字典键值对的四种方法实例
目录 前言 一.当值唯一时 1. 使用zip进行交换 2. 使用for循环遍历交换 3. 使用dict.items()交换 二.当值不唯一时 总结 前言 在学习过程中发现有时候交换字典的键和值,会使得我们最后的输出结果更加直观明了,整理出以下四种交换方式(data是原字典,new_data 是交换后的字典) 一.当值唯一时 1. 使用zip进行交换 data= {'A':1, 'B':2, 'C':3} new_data = dict(zip(data.values(), data.keys()
-
python多进程和多线程究竟谁更快(详解)
python3.6 threading和multiprocessing 四核+三星250G-850-SSD 自从用多进程和多线程进行编程,一致没搞懂到底谁更快.网上很多都说python多进程更快,因为GIL(全局解释器锁).但是我在写代码的时候,测试时间却是多线程更快,所以这到底是怎么回事?最近再做分词工作,原来的代码速度太慢,想提速,所以来探求一下有效方法(文末有代码和效果图) 这里先来一张程序的结果图,说明线程和进程谁更快 一些定义 并行是指两个或者多个事件在同一时刻发生.并发是指两个或多个
-
利用Python自制网页并实现一键自动生成探索性数据分析报告
目录 前言 上传文件以及变量的筛选 前言 今天小编带领大家用Python自制一个自动生成探索性数据分析报告这样的一个工具,大家只需要在浏览器中输入url便可以轻松的访问,如下所示: 第一步 首先我们导入所要用到的模块,设置网页的标题.工具栏以及logo的导入,代码如下: from st_aggrid import AgGrid import streamlit as st import pandas as pd import pandas_profiling from streamlit_pan
-
Python 数据分析教程探索性数据分析
目录 什么是探索性数据分析(EDA)? 描述性统计 分组数据 方差分析 相关性和相关性计算 什么是探索性数据分析(EDA)? EDA 是数据分析下的一种现象,用于更好地理解数据方面,例如: – 数据的主要特征 – 变量和它们之间的关系 – 确定哪些变量对我们的问题很重要 我们将研究各种探索性数据分析方法, 例如: 描述性统计,这是一种简要概述我们正在处理的数据集的方法,包括样本的一些度量和特征 分组数据 [使用group by 进行基本分组] ANOVA,方差分析,这是一种计算方法,可将观察集
-
让Python代码更快运行的5种方法
不论什么语言,我们都需要注意性能优化问题,提高执行效率.选择了脚本语言就要忍受其速度,这句话在某种程度上说明了Python作为脚本语言的不足之处,那就是执行效率和性能不够亮.尽管Python从未如C和Java一般快速,但是不少Python项目都处于开发语言领先位置. Python很简单易用,但大多数人使用Python都知道在处理密集型cpu工作时,它的数量级依然低于C.Java和JavaScript.但不少第三方不愿赘述Python的优点,而是决定自内而外提高其性能.如果你想让Python在同一
-
如何用PyPy让你的Python代码运行得更快
Python是开发人员中最常用的编程语言之一,但它有一定的局限性.例如,对于某些应用程序而言,它的运行速度可能比其它语言低100倍.这就是为什么当Python的运行速度成为用户瓶颈后,许多公司会用另一种语言重写他们的应用程序.但是有没有一种方法既可以保持Python的特性又能提高速度呢?它就是PyPy. PyPy是一种非常兼容的Python解释器,它是CPython2.7.3.6和即将推出的3.7的一种值得替代的方法.在安装和运行应用程序时使用它,可以显著提高速度.速度提高多少取决于你运行的应用