堆排序原理及算法代码详解
目录
- 二、二叉树定义
- 三、堆的定义
- 四、堆排序Java代码实现
- 总结
一、堆排序算法原理和动态图解
将待排序的序列构造成一个大顶堆。此时,整个序列的最大值就是堆顶的根节点。将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中的次最大值。如此反复执行,就能得到一个有序序列了。这个过程其实就是先构建一个最大/最小二叉堆,然后不停的取出最大/最小元素(头结点),插入到新的队列中,以此达到排序的目的。如下图所示:
二、二叉树定义
要了解堆首先得了解一下二叉树,在计算机科学中,二叉树是每个节点最多有两个子树的树结构。通常子树被称作“左子树”(left subtree)和“右子树”(right subtree)。二叉树常被用于实现二叉查找树和二叉堆。二叉树的每个结点至多只有二棵子树(不存在度大于 2 的结点),二叉树的子树有左右之分,次序不能颠倒。二叉树的第 i 层至多有 2i - 1 个结点;深度为 k 的二叉树至多有 2k - 1 个结点;对任何一棵二叉树 T,如果其终端结点数为 n0,度为 2 的结点数为 n2,则n0 = n2 + 1。二叉树又分为完全二叉树(complete binary tree)和满二叉树(full binary tree)。树和二叉树的三个主要差别:
- 树的结点个数至少为 1,而二叉树的结点个数可以为 0
- 树中结点的最大度数没有限制,而二叉树结点的最大度数为 2
- 树的结点无左、右之分,而二叉树的结点有左、右之分
1.满二叉树:一棵深度为 k,且有 2k - 1 个节点称之为满二叉树,即每一层上的节点数都是最大节点数。如下图b所示:深度为3的满二叉树。
2.完全二叉树:而在一棵二叉树中,除最后一层外,若其余层都是满的,并且最后一层或者是满的,或者是在右边缺少连续若干节点,则此二叉树为完全二叉树(Complete Binary Tree)。如下图a所示:是一个深度为4的完全二叉树。
三、堆的定义
堆(二叉堆)可以视为一棵完全的二叉树,完全二叉树的一个“优秀”的性质是,除了最底层之外,每一层都是满的,这使得堆可以利用数组来表示(普通的一般的二叉树通常用链表作为基本容器表示),每一个结点对应数组中的一个元素。
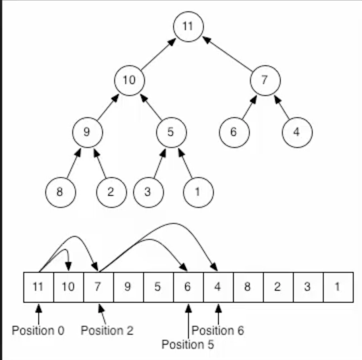
对于7在数组存放的position=2,而它的子元素6的position=5=2*2[也就是父元素存放的位置]+1、子元素4的position=6=2*2[也就是父元素存放的位置]+2;同样对于11在在数组存放的position=0,而它的子元素10的position=1=2*0[也就是父元素存放的位置]+1、子元素7的position=2=2*0[也就是父元素存放的位置]+2;所以对于i个元素,它的左右子节点在下标以0开始的数组中的位置分别为:2*i+1、2*i+2。那脑补一下,对于不完全二叉树,如果用数组来存放会有什么问题呢?当然是中间有很多空的元素啦,所以说对于不完全二叉树最好是用链表来存储~。
堆的构建过程示例:建堆的核心内容是调整堆,使二叉树满足堆的定义(每个节点的值都不大于其父节点的值)。调堆的过程应该从最后一个非叶子节点开始,假设有数组A = {1, 3, 4, 5, 7, 2, 6, 8, 0}。那么调堆的过程如下图,数组下标从0开始,A[3] = 5开始。分别与左孩子和右孩子比较大小,如果A[3]最大,则不用调整,否则和孩子中的值最大的一个交换位置,在图1中是A[7] > A[3] > A[8],所以A[3]与A[7]对换,从图1.1转到图1.2。

二叉堆(英语:binary heap)是一种特殊的堆,二叉堆是完全二叉树或者是近似完全二叉树。二叉堆满足堆特性:父节点的键值总是保持固定的序关系于任何一个子节点的键值,且每个节点的左子树和右子树都是一个二叉堆。当父节点的键值总是大于或等于任何一个子节点的键值时为最大堆。 当父节点的键值总是小于或等于任何一个子节点的键值时为最小堆。二叉堆一般用数组来表示。如果根节点在数组中的位置是1,第n个位置的子节点分别在2n和 2n+1。因此,第1个位置的子节点在2和3,第2个位置的子节点在4和5。以此类推。这种基于1的数组存储方式便于寻找父节点和子节点。如果存储数组的下标基于0,那么下标为i的节点的子节点是2i + 1与2i + 2;其父节点的下标是⌊floor((i − 1) ∕ 2)⌋。函数floor(x)的功能是“向下取整”,或者说“向下舍入”,即取不大于x的最大整数(与“四舍五入”不同,向下取整是直接取按照数轴上最接近要求值的左边值,即不大于要求值的最大的那个值)。比如floor(1.1)、floor(1.9)都返回1。对于堆定义中的堆结构插入元素:对于二叉堆来说,要插入一个新元素其整个过程是怎么样的呢?这里还是以我们之前的那个二叉堆进行说明,以插入"9"为例:
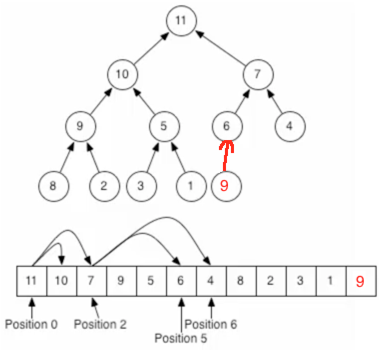
目前肯定不满足二叉堆的要求,父接点6是小于新插入的节点9的,所以两者进行位置交换:

同样的思路,父节点7比子节点9要小,所以需要调换位置:
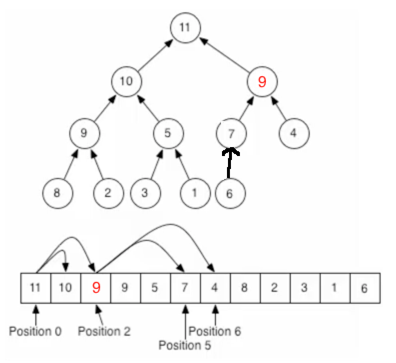
至此元素插入完成,也符合二叉堆父元素大于子元素的规则,从添加过程中可以发现:只需更改待比较的元素,其它的任何元素位置不需要动,所以效率还是很高的。对于堆定义中的堆结构删除元素:这里以删除根结点为例【因为删除根节点是最重要的,所以以它为例】,整个过程如下:
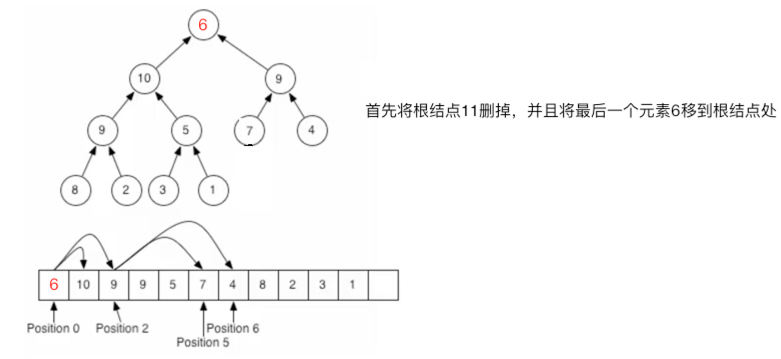
这时当然是不符合二叉堆的规则,接着这样来做:
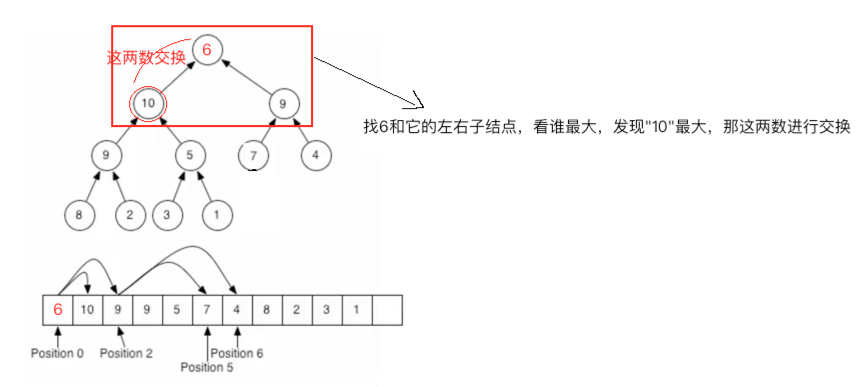
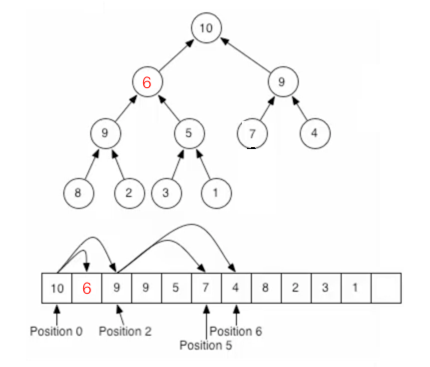
同理继续进行处理:

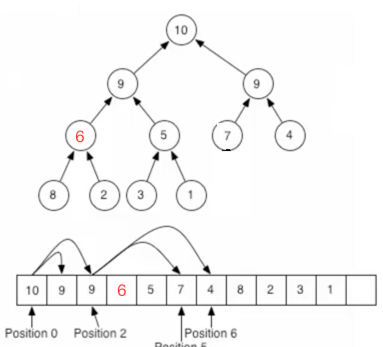
继续:
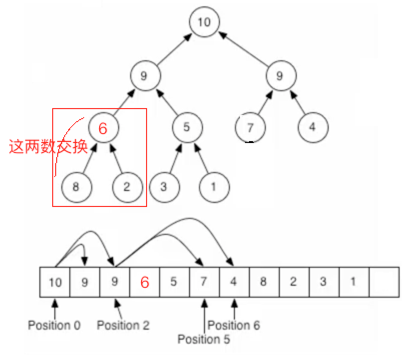
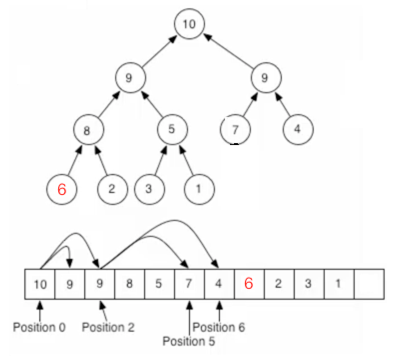
经过这些动作之后就将一个根结点给删除掉了,可以发现其实跟插入一个元素一样,只需更改待比较的元素,其它的任何元素位置不需要动,那像这种每次移除掉最大的值有啥用呢?堆排序就产生了,因为每次从根节点拿肯定是最大的数【以最大堆来说】,这样拿出来的数就成了一个有序的数列了。注意:对于一个很大的堆,这种存储是低效的。因为节点的子节点很可能在另外一个内存页中。B-heap是一种效率更高的存储方式,把每个子树放到同一内存页。如果用指针链表存储堆,那么需要能访问叶节点的方法。可以对二叉树“穿线”(threading)方式,来依序遍历这些节点。
四、堆排序Java代码实现
package com.luna.sort;
public class HeapSortMaxAndMin{
public static void main(String[] args) {
int[] array = { 19, 38, 7, 36, 5, 5, 3, 2, 1, 0, 56 };
System.out.println("排序前:");
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + ",");
}
System.out.println();
System.out.println("分割线---------------");
heapSort(array);
System.out.println("排序后:");
for (int i = 0; i < array.length; i++) {
System.out.print(array[i] + ",");
}
}
public static void heapSort(int[] array) {
if (array == null || array.length == 1)
return;
buildArrayToHeap(array); //将数组元素转化为大顶堆/小顶堆
for (int i = array.length - 1; i >= 1; i--) {
// 经过上面的一些列操作,目前array[0]是当前数组里最大的元素,需要和末尾的元素交换,然后拿出最大的元素
swap(array, 0, i);
/**
* 交换完后,下次遍历的时候,就应该跳过最后一个元素,也就是最大的那个
* 值,然后开始重新构建最大堆堆的大小就减去1,然后从0的位置开始最大堆
*/
// buildMaxHeap(array, i, 0);
buildMinHeap(array, i, 0);
}
}
// 构建堆
public static void buildArrayToHeap(int[] array) {
if (array == null || array.length == 1)
return;
//递推公式就是 int root = 2*i, int left = 2*i+1, int right = 2*i+2;
int cursor = array.length / 2;
for (int i = cursor; i >= 0; i--) { // 这样for循环下,就可以第一次排序完成
// buildMaxHeap(array, array.length, i);
buildMinHeap(array, array.length, i);
}
}
//大顶堆
public static void buildMaxHeap(int[] array, int heapSieze, int index) {
int left = index * 2 + 1; // 左子节点
int right = index * 2 + 2; // 右子节点
int maxValue = index; // 暂时定在Index的位置就是最大值
// 如果左子节点的值,比当前最大的值大,就把最大值的位置换成左子节点的位置
if (left < heapSieze && array[left] > array[maxValue]) {
maxValue = left;
}
// 如果右子节点的值,比当前最大的值大,就把最大值的位置换成右子节点的位置
if (right < heapSieze && array[right] > array[maxValue]) {
maxValue = right;
}
// 如果不相等说明,这个子节点的值有比自己大的,位置发生了交换了位置
if (maxValue != index) {
swap(array, index, maxValue); // 就要交换位置元素
// 交换完位置后还需要判断子节点是否打破了最大堆的性质。最大堆性质:两个子节点都比父节点小。
buildMaxHeap(array, heapSieze, maxValue);
}
}
//小顶堆
public static void buildMinHeap(int[] array, int heapSieze, int index) {
int left = index * 2 + 1; // 左子节点
int right = index * 2 + 2; // 右子节点
int maxValue = index; // 暂时定在Index的位置就是最小值
// 如果左子节点的值,比当前最小的值小,就把最小值的位置换成左子节点的位置
if (left < heapSieze && array[left] < array[maxValue]) {
maxValue = left;
}
// 如果右子节点的值,比当前最小的值小,就把最小值的位置换成左子节点的位置
if (right < heapSieze && array[right] < array[maxValue]) {
maxValue = right;
}
// 如果不相等说明这个子节点的值有比自己小的,位置发生了交换了位置
if (maxValue != index) {
swap(array, index, maxValue); // 就要交换位置元素
// 交换完位置后还需要判断子节点是否打破了最小堆的性质。最小性质:两个子节点都比父节点大。
buildMinHeap(array, heapSieze, maxValue);
}
}
// 数组元素交换
public static void swap(int[] a, int i, int j) {
int temp = a[i];
a[i] = a[j];
a[j] = temp;
}
}
大顶堆优化实现算法:
import java.util.Arrays;
public class MaxHeapSort {
private int[] arr;
public MaxHeapSort(int[] arr){
this.arr = arr;
}
/**
* 堆排序的主要入口方法,共两步。
*/
public void sort(){
/*
* 第一步:将数组堆化
* beginIndex = 第一个非叶子节点。
* 从第一个非叶子节点开始即可。无需从最后一个叶子节点开始。
* 叶子节点可以看作已符合堆要求的节点,根节点就是它自己且自己以下值为最大。
*/
int len = arr.length - 1;
int beginIndex = (len - 1) >> 1;
for(int i = beginIndex; i >= 0; i--){
maxHeapify(i, len);
}
/*
* 第二步:对堆化数据排序
* 每次都是移出最顶层的根节点A[0],与最尾部节点位置调换,同时遍历长度 - 1。
* 然后从新整理被换到根节点的末尾元素,使其符合堆的特性。
* 直至未排序的堆长度为 0。
*/
for(int i = len; i > 0; i--){
swap(0, i);
maxHeapify(0, i - 1);
}
}
private void swap(int i,int j){
int temp = arr[i];
arr[i] = arr[j];
arr[j] = temp;
}
/**
* 调整索引为 index 处的数据,使其符合堆的特性。
* @param index 需要堆化处理的数据的索引
* @param len 未排序的堆(数组)的长度
*/
private void maxHeapify(int index,int len){
int li = (index << 1) + 1; // 左子节点索引
int ri = li + 1; // 右子节点索引
int cMax = li; // 子节点值最大索引,默认左子节点。
if(li > len) return; // 左子节点索引超出计算范围,直接返回。
if(ri <= len && arr[ri] > arr[li]) // 先判断左右子节点,哪个较大。
cMax = ri;
if(arr[cMax] > arr[index]){
swap(cMax, index); // 如果父节点被子节点调换,
maxHeapify(cMax, len); // 则需要继续判断换下后的父节点是否符合堆的特性。
}
}
/**
* 测试用例
* 输出:
* [0, 0, 0, 1, 1, 1, 2, 2, 2, 3, 3, 3, 4, 4, 4, 5, 5, 5, 6, 6, 6, 7, 7, 7, 8, 8, 8, 9, 9, 9]
*/
public static void main(String[] args) {
int[] arr = new int[]{3,5,3,0,8,6,1,5,8,6,2,4,9,4,7,0,1,8,9,7,3,1,2,5,9,7,4,0,2,6};
new MaxHeapSort(arr).sort();
System.out.println(Arrays.toString(arr));
}
}
总结
本篇文章就到这里了,希望能给你带来帮助,也希望您能够多多关注我们的更多内容!
相关推荐
-
Java堆排序算法详解
堆是数据结构中的一种重要结构,了解"堆"的概念和操作,可以帮助我们快速地掌握堆排序. 堆的概念 堆是一种特殊的完全二叉树(complete binary tree).如果一棵完全二叉树的所有节点的值都不小于其子节点,称之为大根堆(或大顶堆):所有节点的值都不大于其子节点,称之为小根堆(或小顶堆). 在数组(在0号下标存储根节点)中,容易得到下面的式子(这两个式子很重要): 1.下标为i的节点,父节点坐标为(i-1)/2: 2.下标为i的节点,左子节点坐标为2*i+1,右子节点为2*i+
-

Python排序搜索基本算法之堆排序实例详解
本文实例讲述了Python排序搜索基本算法之堆排序.分享给大家供大家参考,具体如下: 堆是一种完全二叉树,堆排序是一种树形选择排序,利用了大顶堆堆顶元素最大的特点,不断取出最大元素,并调整使剩下的元素还是大顶堆,依次取出最大元素就是排好序的列表.举例如下,把序列[26,5,77,1,61,11,59,15,48,19]排序,如下: 基于堆的优先队列算法代码如下: def fixUp(a): #在堆尾加入新元素,fixUp恢复堆的条件 k=len(a)-1 while k>1 and a[k//2
-
PHP排序算法之堆排序(Heap Sort)实例详解
本文实例讲述了PHP排序算法之堆排序(Heap Sort).分享给大家供大家参考,具体如下: 算法引进: 在这里我直接引用<大话数据结构>里面的开头: 在前面讲到 简单选择排序 ,它在待排序的 n 个记录中选择一个最小的记录需要比较 n - 1 次,本来这也可以理解,查找第一个数据需要比较这么多次是正常的,否则如何知道他是最小的记录. 可惜的是,这样的操作并没有把每一趟的比较结果保存下来,在后一趟的比较重,有许多比较在前一趟已经做过了,但由于前一趟排序时未保存这些比较结果,所以后一趟排序时又重
-
基于PHP实现堆排序原理及实例详解
堆 堆(heap)是计算机科学中一类特殊的数据结构的统称,通常是一个可以被看做一棵树的数组对象. 堆{k1,k2,ki,-,kn} (ki <= k2i,ki <= k2i+1)|(ki >= k2i,ki >= k2i+1), (i = 1,2,3,4...n/2) 关于堆: 堆中某个节点的值总是不大于或不小于其父节点的值: 堆总是一棵完全二叉树(下面). 将根节点最大的堆叫做最大堆或大根堆,根节点最小的堆叫做最小堆或小根堆. 完全二叉树 说到堆排序,就不能不提完全二叉树,这些基
-
Python堆排序原理与实现方法详解
本文实例讲述了Python堆排序原理与实现方法.分享给大家供大家参考,具体如下: 在这里要事先说明一下我也是新手,很多东西我了解不是很深入,写算法完全是锻炼自己逻辑能力同时顺带帮助读研的朋友么解决一些实际问题.所以很多时候考虑的东西不是很全面能请各位看到博文的大牛们指正.对于排序算法说实在的我觉得已经写烂了,但是为什么还是要过一遍呢?还是为了能够打牢基础.说一下自己的看法,对于已经的玩烂的算法因该怎么学.首先最重要的还是了解算法的基本模型和算法思想,我觉得这是非常重要的.其次的话首先先尝试自己实
-
堆排序原理及算法代码详解
目录 二.二叉树定义 三.堆的定义 四.堆排序Java代码实现 总结 一.堆排序算法原理和动态图解 将待排序的序列构造成一个大顶堆.此时,整个序列的最大值就是堆顶的根节点.将它移走(其实就是将其与堆数组的末尾元素交换,此时末尾元素就是最大值),然后将剩余的n-1个序列重新构造成一个堆,这样就会得到n个元素中的次最大值.如此反复执行,就能得到一个有序序列了.这个过程其实就是先构建一个最大/最小二叉堆,然后不停的取出最大/最小元素(头结点),插入到新的队列中,以此达到排序的目的.如下图所示: 二.二
-
C语言冒泡排序算法代码详解
今天我们来用C语言实现一下冒泡排序 首先我们来了解一下什么叫做冒泡排序,冒泡顾名思义把质量轻的气体(如二氧化碳一样)浮到水面上(如可乐中的二氧化碳),因此冒泡排序的原理就是N个元素在一个周期中,微观上依次进行两两元素的比较,小的元素就被放在前面,大的元素放在后面,以此来进行N-1个周期,来完成冒泡排序. 上文中的一个周期,即外循环,依次进行比较,即内循环. 文字看着很迷糊?没事儿,上图 如图所示,两两元素依次进行比较,小的元素往前移动,大的元素往后移动,直至元素顺序是升序的形式,即移动了 元素-
-
Java版超大整数阶乘算法代码详解-10,0000级
当计算超过20以上的阶乘时,阶乘的结果值往往会很大.一个很小的数字的阶乘结果就可能超过目前个人计算机的整数范围.如果需求很大的阶乘,比如1000以上完全无法用简单的递归方式去解决.在网上我看到很多用C.C++和C#写的一些关于大整数阶乘的算法,其中不乏经典但也有很多粗糙的文章.数组越界,一眼就可以看出程序本身无法运行.转载他人文章的时候,代码倒是仔细看看啊.唉,粗糙.过年了,在家闲来蛋疼,仔细分析分析,用Java实现了一个程序计算超大整数阶乘.思想取自网上,由我个人优化和改进. 这个方法采用"数
-
Python 分形算法代码详解
目录 1. 前言 什么是分形算法? 2. 分形算法 2.1 科赫雪花 2.2 康托三分集 2.3 谢尔宾斯基三角形 2.4 分形树 3. 总结 1. 前言 分形几何是几何数学中的一个分支,也称大自然几何学,由著名数学家本华曼德勃罗( 法语:BenoitB.Mandelbrot)在 1975 年构思和发展出来的一种新的几何学. 分形几何是对大自然中微观与宏观和谐统一之美的发现,分形几何最大的特点: 整体与局部的相似性: 一个完整的图形是由诸多相似的微图形组成,而整体图形又是微图形的放大. 局部是整
-
Java收集的雪花算法代码详解
package com.java265.other; public class Test { // 因为二进制里第一个 bit 为如果是 1,那么都是负数,但是我们生成的 id 都是正数,所以第一个 bit 统一都是 0. // 机器ID 2进制5位 32位减掉1位 31个 private long workerId; // 机房ID 2进制5位 32位减掉1位 31个 private long datacenterId; // 代表一毫秒内生成的多个id的最新序号 12位 4096 -1 =
-
Javascript表单序列化原理及实现代码详解
随着 Ajax 的出现,表单序列化已经成为一种常见需求.在 JavaScript 中,可 以利用表单字段的 type 属性,连同 name 和 value 属性一起实现对表单的序列化.在编写代码之前, 有必须先搞清楚在表单提交期间,浏览器是怎样将数据发送给服务器的. 1. 对表单字段的名称和值进行 URL 编码,使用和号(&)分隔. 2. 不发送禁用的表单字段. 3. 只发送勾选的复选框和单选按钮. 4. 不发送 type 为"reset"和"button"
-
Python自然语言处理之词干,词形与最大匹配算法代码详解
本文主要对词干提取及词形还原以及最大匹配算法进行了介绍和代码示例,Python实现,下面我们一起看看具体内容. 自然语言处理中一个很重要的操作就是所谓的stemming和lemmatization,二者非常类似.它们是词形规范化的两类重要方式,都能够达到有效归并词形的目的,二者既有联系也有区别. 1.词干提取(stemming) 定义:Stemmingistheprocessforreducinginflected(orsometimesderived)wordstotheirstem,base
-
Java 归并排序算法、堆排序算法实例详解
基本思想: 归并(Merge)排序法是将两个(或两个以上)有序表合并成一个新的有序表,即把待排序序列分为若干个子序列,每个子序列是有序的.然后再把有序子序列合并为整体有序序列. 归并排序示例: 合并方法: 设r[i-n]由两个有序子表r[i-m]和r[m+1-n]组成,两个子表长度分别为n-i +1.n-m. j=m+1:k=i:i=i; //置两个子表的起始下标及辅助数组的起始下标 若i>m 或j>n,转⑷ //其中一个子表已合并完,比较选取结束 //选取r[i]和r[j]较小的存入辅助数组
-
机器学习经典算法-logistic回归代码详解
一.算法简要 我们希望有这么一种函数:接受输入然后预测出类别,这样用于分类.这里,用到了数学中的sigmoid函数,sigmoid函数的具体表达式和函数图象如下: 可以较为清楚的看到,当输入的x小于0时,函数值<0.5,将分类预测为0:当输入的x大于0时,函数值>0.5,将分类预测为1. 1.1 预测函数的表示 1.2参数的求解 二.代码实现 函数sigmoid计算相应的函数值:gradAscent实现的batch-梯度上升,意思就是在每次迭代中所有数据集都考虑到了:而stoGradAscen