python实现划词翻译
最近因为编程,需要大量地看一些说明文档,无奈说明文档都是英文的,可把我这个半桶水折腾死了,太多词汇不知道,一个个复制翻译太麻烦了。于是我根据自己的需要,用python写了一个划词翻译。
一、使用逻辑
由于我是看PDF文档,用的是一款轻量级的PDF阅读器(SumatraPDF),这款阅读器只有5M,但是阅读很舒服很流畅,渲染也很到位。但是没有其他阅读器有许多强大功能,比如说划词翻译。
我的想法是一旦发现我复制就可以在当前鼠标位置显示一个翻译结果框。基于这个想法,我一开始准备使用MFC编写,因为MFC能够轻易获得系统消息,钩子调用十分简单。可是我把检测复制,显示文本框都做好的时候,发现一个悲伤的事实,c++的http库实在是不怎么样,竟然无法访问http://地址,经过一晚的尝试——失败,这才打算使用python。啰啰嗦嗦一大堆,我现在把我的逻辑说下吧。
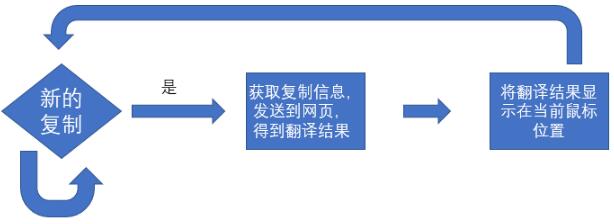
二、需要引用的库
因为要联网所以需要urllib,解析网页需要json,读取剪切板数据需要win32clipboard,获得当前鼠标信息用PyMouse,生成文本框Tkinter,定时器time。python为什么强大,就在于集成库的易用性和多样性,有什么需要就pip install 装就行,这点比c++强太多了。
import urllib #http连接需要用到 import json #解析网页数据用 import win32clipboard as wc #读取剪切板数据 from pymouse import PyMouse #获得当前鼠标信息 import Tkinter #自带的GUI库,生成文本框 import time #定时器,减少占用
三、代码实现
我这里先定义了三个函数,方便后面实现功能,下面有详细解释和代码
#PyMouse得到的是2维字符串,但是tkinter生成窗体时需要的是类似(100*100+x+y)的字符串,100*100是窗口大小,xy是坐标点。 def transMousePosition(): m = PyMouse() return "100x100+"+str(m.position()[0])+"+"+str(m.position()[1]) #获得剪切板数据 def getCopyText(): wc.OpenClipboard() copy_text = wc.GetClipboardData() wc.CloseClipboard() return copy_text #返会是否有新的复制数据,cmp函数用于比较2个对象,如果 x < y 返回 -1, 如果 x == y 返回 0, 如果 x > y 返回 1。 def newCopyData(): return cmp(currentData,str(getCopyText()))
主程序
if __name__ == '__main__':
req_url = 'http://fanyi.youdao.com/translate' # 创建连接接口,这里是有道词典的借口
# 创建要提交的数据
currentData=str(getCopyText())
Form_Date = {}
Form_Date['doctype'] = 'json'
while 1:
if newCopyData():
currentData=str(getCopyText())#取得当前剪切板数据
Form_Date['i'] = currentData # 传递数据
data = urllib.urlencode(Form_Date).encode('utf-8') #数据转换
response = urllib.urlopen(req_url, data) #提交数据并解析
html = response.read().decode('utf-8') #服务器返回结果读取
translate_results = json.loads(html) #以json格式载入
translate_results = translate_results['translateResult'][0][0]['tgt'] # json格式调取
position=transMousePosition()#取得当前鼠标位置
top = Tkinter.Tk()#窗口初始化
top.wm_attributes('-topmost',1)#置顶窗口
top.geometry(position)#指定定位生成指定大小窗口
e=Tkinter.Text()#生成文本框部件
e.insert(1.0,translate_results)#插入数据
e.pack()#将部件打包进窗口
top.mainloop()# 进入消息循环
currentData=str(getCopyText())
time.sleep(1)
到此,我们划词翻译程序就已经完成了,虽然不太美观。而且美中不足的是我没有想到一个好的办法退出程序,相当于一个死循环在里面,只有强行退出,不知道谁有好办法能够解决这个问题
总结
如果要实现什么功能,python该是最好的胶水了,c++的http库实在是太坑了,浪费我好多小时。下面源代码附上,给大家参考
# -*- coding: utf-8 -*-
"""
Created on Sat Aug 11 08:24:48 2018
@author: ltengy
"""
import urllib #http连接需要用到
import json #解析网页数据用
import win32clipboard as wc #读取剪切板数据
from pymouse import PyMouse #获得当前鼠标信息
import Tkinter #自带的GUI库,生成文本框
import time #定时器,减少占用
currentData=''
#PyMouse得到的是2维字符串,但是tkinter生成窗体时需要的是类似(100*100+x+y)的字符串,100*100是窗口大小,xy是坐标点。
def transMousePosition():
m = PyMouse()
return "100x100+"+str(m.position()[0])+"+"+str(m.position()[1])
#获得剪切板数据
def getCopyText():
wc.OpenClipboard()
copy_text = wc.GetClipboardData()
wc.CloseClipboard()
return copy_text
#返会是否有新的复制数据
def newCopyData():
return cmp(currentData,str(getCopyText()))
if __name__ == '__main__':
req_url = 'http://fanyi.youdao.com/translate' # 创建连接接口,这里是有道词典的借口
# 创建要提交的数据
currentData=str(getCopyText())
Form_Date = {}
Form_Date['doctype'] = 'json'
while 1:
if newCopyData():
currentData=str(getCopyText())#取得当前剪切板数据
Form_Date['i'] = currentData # 传递数据
data = urllib.urlencode(Form_Date).encode('utf-8') #数据转换
response = urllib.urlopen(req_url, data) #提交数据并解析
html = response.read().decode('utf-8') #服务器返回结果读取
translate_results = json.loads(html) #以json格式载入
translate_results = translate_results['translateResult'][0][0]['tgt'] # json格式调取
position=transMousePosition()#取得当前鼠标位置
top = Tkinter.Tk()#窗口初始化
top.wm_attributes('-topmost',1)#置顶窗口
top.geometry(position)#指定定位生成指定大小窗口
e=Tkinter.Text()#生成文本框部件
e.insert(1.0,translate_results)#插入数据
e.pack()#将部件打包进窗口
top.mainloop()# 进入消息循环
currentData=str(getCopyText())
time.sleep(1)
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python使用百度翻译进行中翻英示例
利用百度词典进行中翻英 复制代码 代码如下: import urllib2import reimport sys reload(sys)sys.setdefaultencoding('utf-8')def tran(word): url='http://dict.baidu.com/s?wd={0}&tn=dict'.format(word) print url req=urllib2.Request(url) resp=urllib2.urlopen(req) r
-
python自动翻译实现方法
本文实例讲述了python自动翻译实现方法.分享给大家供大家参考,具体如下: 以前学过python的基础,一般也没用过.后来有一个参数表需要中英文.想了一下,还是用python做吧.调用的百度翻译接口,经历了乱码.模块不全等问题.一般google,一边做的.分享一下. #encoding=utf-8 ## eagle_91@sina.com ## created 2014-07-22 import urllib import urllib2 import MySQLdb import json
-

基于python实现百度翻译功能
运行环境: python 3.6.0 今天处于练习的目的,就用 python 写了一个百度翻译,是如何做到的呢,其实呢就是拿到接口,通过这个接口去访问,不过中间确实是出现了点问题,不过都解决掉了 先晾图后晾代码 运行结果: 代码: # -*- coding: utf-8 -*- """ 功能:百度翻译 注意事项:中英文自动切换 """ import requests import re class Baidu_Translate(object):
-
python实现在线翻译功能
对于需要大量翻译的数据,人工翻译太慢,此时需要使用软件进行批量翻译. 1.使用360的翻译 def fanyi_word_cn(string): url="https://fanyi.so.com/index/search" #db_path = './db/tasks.db' Form_Data= {} #这里输入要翻译的英文 Form_Data['query']= string Form_Data['eng']= '1' #用urlencode把字典变成字符串,#服务器不接受字典,
-
Python使用tkinter制作在线翻译软件
tkinter的功能是如此强大,竟然还能做翻译软件.当然是在线的,我发现有一个quicktranslate模块,可以提供在线翻译功能,相当于提供了一个翻译的接口,利用它就可以制作在线翻译软件了.下面是代码,分享给大家. 注意要首先 pip install quicktranslate #-*- coding:utf-8 -*- import tkinter as tk #使用Tkinter前需要先导入 from tkinter import messagebox,ttk import datet
-
python利用有道翻译实现"语言翻译器"的功能实例
实例如下: import urllib.request import urllib.parse import json while True: content = input('请输入需要翻译的内容(退出输入Q):') if content == 'Q': break else: url = 'http://fanyi.youdao.com/translate?smartresult=dict&smartresult=rule&smartresult=ugc&sessionFrom
-
Python 实现的 Google 批量翻译功能
首先声明,没有什么不良动机,因为经常会用 translate.google.cn,就想着用 Python 模拟网页提交实现文档的批量翻译.据说有 API,可是要收费. 生成 Token Google 为防爬虫而生成 token 的代码是 Javascript 的,且是根据网站的 TKK 值和提交的文本动态生成.更新规律未知,只好定时去取一下了. 网上能找到的 Python 代码大部分是去调用 PyExecJS 库,先不说执行效率的高低(大概是差一个数量级),首先是舍近求远,不纯粹,本人不喜欢.
-
python翻译软件实现代码(使用google api完成)
复制代码 代码如下: # -*- coding: utf-8 -*- import httplibfrom urllib import urlencodeimport re def out(text): p = re.compile(r'","') m = p.split(text) print m[0][4:].decode('UTF-8').encode('GBK') if __name__=='__main__': while True: w
-
使用Python从有道词典网页获取单词翻译
从有道词典网页获取某单词的中文解释. import re import urllib word=raw_input('input a word\n') url='http://dict.youdao.com/search?q=%s'%word content=urllib.urlopen(url) pattern=re.compile("</h2.*?</ul>",re.DOTALL) result=pattern.search(content.read()).gro
-
用python实现百度翻译的示例代码
用python实现百度翻译,分享给大家,具体如下: 首先,需要简单的了解一下爬虫,尽可能简单快速的上手,其次,需要了解的是百度的API的接口,搞定这个之后,最后,按照官方给出的demo,然后写自己的一个小程序 打开浏览器 F12 打开百度翻译网页源代码: 我们可以轻松的找到百度翻译的请求接口为:http://fanyi.baidu.com/sug 然后我们可以从方法为POST的请求中找到参数为:kw:job(job是输入翻译的内容) 下面是代码部分: from urllib import req