Spectral clustering谱聚类算法的实现代码
目录
- 1.作者介绍
- 2.关于谱聚类的介绍
- 2.1 谱聚类概述
- 2.2 无向权重图
- 2.3 邻接矩阵
- 2.4 相似矩阵
- 2.5 度矩阵
- 2.6 拉普拉斯矩阵
- 2.7 K-Means
- 3.Spectral clustering(谱聚类)算法实现
- 3.1 数据集
- 3.2 导入所需要的包
- 3.3 获取特征值和特征向量
- 3.4 利用K-Means聚类
- 3.5 完整代码
- 4.参考
1.作者介绍
刘然,女,西安工程大学电子信息学院,2021级研究生
研究方向:图像处理
电子邮件:1654790996@qq.com
刘帅波,男,西安工程大学电子信息学院,2021级研究生,张宏伟人工智能课题组
研究方向:机器视觉与人工智能
电子邮件:1461004501@qq.com
2.关于谱聚类的介绍
2.1 谱聚类概述
谱聚类是从图论中演化出来的算法,它的主要思想是把所有的数据看做空间中的点,这些点之间可以用边连接起来。距离较远的两个点之间的边权重值较低,而距离较近的两个点之间的边权重值较高,通过对所有数据点组成的图进行切图,让切图后不同的子图间边权重和尽可能的低,而子图内的边权重和尽可能的高,从而达到聚类的目的。
2.2 无向权重图
对于一个图G,我们一般用点的集合V和边的集合E来描述。即为G(V,E)。其中V即为我们数据集里面所有的点(v1,v2,…vn)。对于V中的任意两个点,点vi和点vj,我们定义权重wij为二者之间的权重。由于是无向图,所以wij=wji。
2.3 邻接矩阵
邻接矩阵(Adjacency Matrix):是表示顶点之间相邻关系的矩阵。在如图2-1所示的权重图当中(假设各权重为1),其邻接矩阵可表示为图2-2所示。


2.4 相似矩阵
在谱聚类中,我们只有数据点的定义,并没有直接给出这个邻接矩阵,所以我们可以通过样本点距离度量的相似矩阵S来获得邻接矩阵W。
2.5 度矩阵
度矩阵是对角阵,对角上的元素为各个顶点的度。图2-1的度矩阵为图2-3所示。

2.6 拉普拉斯矩阵
拉普拉斯矩阵L=D-W,其中D为度矩阵,W为邻接矩阵。图2-1的拉普拉斯矩阵为图2-4所示。

用拉普拉斯矩阵求解特征值,通过确定特征值(特征值要遵循从小到大的排列方式)的个数来确定对应特征向量的个数,从而实现降维,然后再用kmeans将特征向量进行聚类。
2.7 K-Means
K-Means是聚类算法中的最常用的一种,算法最大的特点是简单,好理解,运算速度快,但是只能应用于连续型的数据,并且一定要在聚类前需要手工指定要分成几类。
下面,我们描述一下K-means算法的过程,为了尽量不用数学符号,所以描述的不是很严谨,大概就是这个意思,“物以类聚、人以群分”:
1.首先输入k的值,即我们希望将数据集经过聚类得到k个分组。
2.从数据集中随机选择k个数据点作为初始大哥(质心,Centroid)
3.对集合中每一个小弟,计算与每一个大哥的距离(距离的含义后面会讲),离哪个大哥距离近,就跟定哪个大哥。
4.这时每一个大哥手下都聚集了一票小弟,这时候召开人民代表大会,每一群选出新的大哥(其实是通过算法选出新的质心)。
5.如果新大哥和老大哥之间的距离小于某一个设置的阈值(表示重新计算的质心的位置变化不大,趋于稳定,或者说收敛),可以认为我们进行的聚类已经达到期望的结果,算法终止。
6.如果新大哥和老大哥距离变化很大,需要迭代3~5步骤。
3.Spectral clustering(谱聚类)算法实现
3.1 数据集
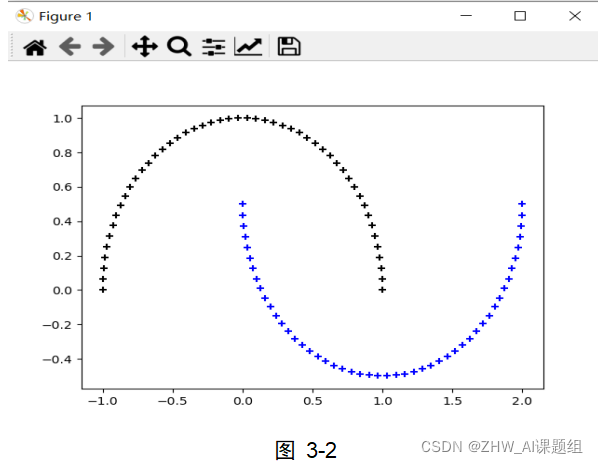
本实验中使用到的数据集均由sklearn.datasets中提供的方法生成,本实验中用到了make_circles,make_moons,make_blobs等函数。make_circles生成数据集,形成一个二维的大圆,包含一个小圆,如图3-1所示;make_moons生成数据集,形成两个弯月,如图3-2所示;make_blobs为聚类生成符合正态分布的数据集,如图3-3所示。


3.2 导入所需要的包
#导入需要的包 import numpy as np from sklearn.cluster import KMeans from sklearn.datasets import make_moons#生成数据集,形成两个弯月。 from sklearn.datasets import make_circles#生成数据集,形成一个二维的大圆,包含一个小圆 from sklearn.datasets import make_blobs#为聚类生成符合正态分布的数据集,产生一个数据集和相应的标签 import matplotlib.pyplot as plt
3.3 获取特征值和特征向量
def get_eigen(L, num_clusters):#获取特征
eigenvalues, eigenvectors = np.linalg.eigh(L)#获取特征值 特征向量
best_eigenvalues = np.argsort(eigenvalues)[0:num_clusters]#argsort函数返回的是数组值从小到大的索引值
U = np.zeros((L.shape[0], num_clusters))
U = eigenvectors[:, best_eigenvalues]#将这些特征取出 构成新矩阵
return U
3.4 利用K-Means聚类
#K-Means聚类
def cluster(data, num_clusters):
data = np.array(data)
W = affinity_matrix(data)
D = getD(W)
L = getL(D, W)
eigenvectors = get_eigen(L, num_clusters)
clf = KMeans(n_clusters=num_clusters)
s = clf.fit(eigenvectors) # 聚类
label = s.labels_
return label
3.5 完整代码
#导入需要的包
import numpy as np
from sklearn.cluster import KMeans
from sklearn.datasets import make_moons#生成数据集,形成两个弯月。
from sklearn.datasets import make_circles#生成数据集,形成一个二维的大圆,包含一个小圆
from sklearn.datasets import make_blobs#为聚类生成符合正态分布的数据集,产生一个数据集和相应的标签
import matplotlib.pyplot as plt
#定义高斯核函数
def kernel(x1, x2, sigma_sq=0.05):
return np.exp(-(np.linalg.norm(x1 - x2) ** 2) / (2 * sigma_sq ** 2))
#定义相似度矩阵
def affinity_matrix(X):
A = np.zeros((len(X), len(X)))#零矩阵
for i in range(len(X) - 1):#长度为len(x) 但是从0开始
for j in range(i + 1, len(X)):#从1开始,到len(x) 是方阵 为啥下角标取值的初始值不同???
A[i, j] = A[j, i] = kernel(X[i], X[j])
return A#通过高斯核的计算 给矩阵赋予新值 10*10
# 计算度矩阵
def getD(A):
D = np.zeros(A.shape)
for i in range(A.shape[0]):
D[i, i] = np.sum(A[i, :])
return D
#计算拉普拉斯矩阵
def getL(D, A):
L = D - A
return L
def get_eigen(L, num_clusters):#获取特征
eigenvalues, eigenvectors = np.linalg.eigh(L)#获取特征值 特征向量
best_eigenvalues = np.argsort(eigenvalues)[0:num_clusters]#argsort函数返回的是数组值从小到大的索引值
U = np.zeros((L.shape[0], num_clusters))
U = eigenvectors[:, best_eigenvalues]#将这些特征取出 构成新矩阵
return U
#K-Means聚类
def cluster(data, num_clusters):
data = np.array(data)
W = affinity_matrix(data)
D = getD(W)
L = getL(D, W)
eigenvectors = get_eigen(L, num_clusters)
clf = KMeans(n_clusters=num_clusters)
s = clf.fit(eigenvectors) # 聚类
label = s.labels_
return label
def plotRes(data, clusterResult, clusterNum):
"""
结果可似化
: data: 样本集
: clusterResult: 聚类结果
: clusterNum: 聚类个数
:return:
n = len(data)
scatterColors = ['black', 'blue', 'red', 'yellow', 'green', 'purple', 'orange']
for i in range(clusterNum):
color = scatterColors[i % len(scatterColors)]
x1 = []
y1 = []
for j in range(n):
if clusterResult[j] == i:
x1.append(data[j, 0])
y1.append(data[j, 1])
plt.scatter(x1, y1, c=color, marker='+')
if __name__ == '__main__':
# # #月牙形数据集,sigma=0.1
# # # cluster_num = 2
# # # data, target = make_moons()
# # # label = cluster(data, cluster_num)
# # # print(label)
# # # plotRes(data, label, cluster_num)
# #
# # 圆形数据集,sigma=0.05
cluster_num = 2
data, target = make_circles(n_samples=1000, shuffle=True, noise=0.05, factor=0.5)
label = cluster(data, cluster_num)
print(label)
plotRes(data, label, cluster_num)
# # # # 正态数据集
# # # # n_samples是待生成的样本的总数。
# # # # n_features是每个样本的特征数。
# # # # centers表示类别数。
# # # # cluster_std表示每个类别的方差,例如我们希望生成2类数据,其中一类比另一类具有更大的方差,可以将cluster_std设置为[1.0, 3.0]。
# # # cluster_num = 2
# # # data, target = make_blobs(n_samples=1500, n_features=2, centers=4, random_state=24)
# # # label = cluster(data, cluster_num)
# # # print(label)
# # # plt.subplot(121)
# # # plotRes(data, target, cluster_num)
# # # plt.subplot(122)
# # # plotRes(data, label, cluster_num)
plt.show()
4.参考
1.<谱聚类(spectral clustering)原理总结 - 刘建平Pinard - 博客园
2.参考博客1
3.参考博客2
4.参考博客3
到此这篇关于Spectral clustering谱聚类算法的实现的文章就介绍到这了,更多相关Spectral clustering谱聚类算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现归一化算法详情
目录 1.前言 2.Min-Max方法 2.1 公式 2.2 算法实现逻辑 2.3 代码 2.4局限 3 Z-score标准化 3.1 公式 3.2 算法实现逻辑 3.3 代码 3.4 局限 4 小数定标法 4.1 公式 4.2 算法实现逻辑 4.3 代码实现 4.4 局限 1.前言 归一化算法Normalization将数据处理成量纲一直的数据,一般限定在[0,1].[-1,1]一般在进行建模的时候需要进行数据归一化处理, 原因如下: 降低计算难度 有可能提高模型的预测精度 消除量纲影响 下面
-
Python&Matlab实现灰狼优化算法的示例代码
目录 1 灰狼优化算法基本思想 2 灰狼捕食猎物过程 2.1 社会等级分层 2.2 包围猎物 2.3 狩猎 2.4 攻击猎物 2.5 寻找猎物 3 实现步骤及程序框图 3.1 步骤 3.2 程序框图 4 Python代码实现 5 Matlab实现 1 灰狼优化算法基本思想 灰狼优化算法是一种群智能优化算法,它的独特之处在于一小部分拥有绝对话语权的灰狼带领一群灰狼向猎物前进.在了解灰狼优化算法的特点之前,我们有必要了解灰狼群中的等级制度. 灰狼群一般分为4个等级:处于第一等级的灰狼用α表示,处于第
-
Python 分形算法代码详解
目录 1. 前言 什么是分形算法? 2. 分形算法 2.1 科赫雪花 2.2 康托三分集 2.3 谢尔宾斯基三角形 2.4 分形树 3. 总结 1. 前言 分形几何是几何数学中的一个分支,也称大自然几何学,由著名数学家本华曼德勃罗( 法语:BenoitB.Mandelbrot)在 1975 年构思和发展出来的一种新的几何学. 分形几何是对大自然中微观与宏观和谐统一之美的发现,分形几何最大的特点: 整体与局部的相似性: 一个完整的图形是由诸多相似的微图形组成,而整体图形又是微图形的放大. 局部是整
-
基于Python实现Hash算法
目录 1 前言 2 一般hash算法 2.1 算法逻辑 2.2 代码实现 2.3 总结 3 一致性hash算法 3.1 算法逻辑 3.2 代码实现 3.3 总结 1 前言 Simhash的算法简单的来说就是,从海量文本中快速搜索和已知simhash相差小于k位的simhash集合,这里每个文本都可以用一个simhash值来代表,一个simhash有64bit,相似的文本,64bit也相似,论文中k的经验值为3.该方法的缺点如优点一样明显,主要有两点,对于短文本,k值很敏感:另一个是由于算法是以空
-
Spectral clustering谱聚类算法的实现代码
目录 1.作者介绍 2.关于谱聚类的介绍 2.1 谱聚类概述 2.2 无向权重图 2.3 邻接矩阵 2.4 相似矩阵 2.5 度矩阵 2.6 拉普拉斯矩阵 2.7 K-Means 3.Spectral clustering(谱聚类)算法实现 3.1 数据集 3.2 导入所需要的包 3.3 获取特征值和特征向量 3.4 利用K-Means聚类 3.5 完整代码 4.参考 1.作者介绍 刘然,女,西安工程大学电子信息学院,2021级研究生研究方向:图像处理电子邮件:1654790996@qq.com
-
php 二维数组快速排序算法的实现代码
php 二维数组快速排序算法的实现代码 二维数组排序算法与一维数组排序算法基本理论都是一样,都是通过比较把小的值放在左变的数组里,大的值放在右边的数组里在分别递归. 实例代码: <?php class Bubble { private function __construct() { } private static function sortt($data) { if (count ( $data ) <= 1) { return $data; } $tem = $data [0]['sco
-
vue2.0中goods选购栏滚动算法的实现代码
不多说,直接代码,以便以后重复利用: <script type="text/ecmascript-6"> import BScroll from 'better-scroll'; const ERR_OK = 0; export default { props: { sell: { type: Object } }, data() { return { goods: [], listHeight: [], scrollY: 0 }; }, computed: { curre
-
python常用排序算法的实现代码
这篇文章主要介绍了python常用排序算法的实现代码,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 排序是计算机语言需要实现的基本算法之一,有序的数据结构会带来效率上的极大提升. 1.插入排序 插入排序默认当前被插入的序列是有序的,新元素插入到应该插入的位置,使得新序列仍然有序. def insertion_sort(old_list): n=len(old_list) k=0 for i in range(1,n): temp=old_lis
-
php计数排序算法的实现代码(附四个实例代码)
计数排序只适合使用在键的变化不大于元素总数的情况下.它通常用作另一种排序算法(基数排序)的子程序,这样可以有效地处理更大的键. 总之,计数排序是一种稳定的线性时间排序算法.计数排序使用一个额外的数组C ,其中第i个元素是待排序数组 A中值等于 i的元素的个数.然后根据数组C 来将A中的元素排到正确的位置. 通常计数排序算法的实现步骤思路是: 1.找出待排序的数组中最大和最小的元素: 2.统计数组中每个值为i的元素出现的次数,存入数组C的第i项: 3.对所有的计数累加(从C中的第一个元素开始,每一
-
使用Python处理KNN分类算法的实现代码
目录 KNN分类算法的介绍 测试数据 Python代码实现 结果分析 简介: 我们在这世上,选择什么就成为什么,人生的丰富多彩,得靠自己成就.你此刻的付出,决定了你未来成为什么样的人,当你改变不了世界,你还可以改变自己. KNN分类算法的介绍 KNN分类算法(K-Nearest-Neighbors Classification),又叫K近邻算法,是一个概念极其简单,而分类效果又很优秀的分类算法. 他的核心思想就是,要确定测试样本属于哪一类,就寻找所有训练样本中与该测试样本“距离”最近的前K个样本
-
C/C++ MD5算法的实现代码
在逆向程序的时候,经常会碰到加密的算法的问题,前面分析UC的逆向工程师的面试题2的时候,发现使用了MD5的加密算法(MD5算法是自己实现的,不是使用的算法库函数).尤其是在逆向分析网络协议的时候,一般的程序使用的加密算法都是使用的库函数提供的算法,有些程序使用的算法是自己实现的:相对来说使用函数库提供的加密函数的算法相对来说比较好识别,因为有算法常见函数在:但是如果不是使用的函数库提供的加密的函数而是自己去实现某些算法话,识别起来有一定的难度,这就需要你对函数的加密原理以及流程还算法的特征比较熟
-
PHP 冒泡排序算法的实现代码
基本概念 冒泡排序的基本概念是:依次比较相邻的两个数,将小数放在前面,大数放在后面.即首先比较第1 个和第2个数,将小数放前,大数放后.然后比较第2个数和第3个数,将小数放前,大数放后,如此继续,直至比较最后两个数,将小数放前,大数放后.重复以上过程,仍从第一对数开始比较(因为可能由于第2个数和第3个数的交换,使得第1个数不再大于第2个数),将小数放前,大数放后,一直比较到最小数前的一对相邻数,将小数放前,大数放后,第二趟结束,在倒数第二个数中得到一个新的最小数.如此下去,直至最终完成排序. 由
-
python冒泡排序算法的实现代码
1.算法描述:(1)共循环 n-1 次(2)每次循环中,如果 前面的数大于后面的数,就交换(3)设置一个标签,如果上次没有交换,就说明这个是已经好了的. 2.python冒泡排序代码 复制代码 代码如下: #!/usr/bin/python# -*- coding: utf-8 -*- def bubble(l): flag = True for i in range(len(l)-1, 0, -1): if flag: flag = False
-
解析C#彩色图像灰度化算法的实现代码详解
代码如下所示: 复制代码 代码如下: public static Bitmap MakeGrayscale(Bitmap original) { //create a blank bitmap the same size as original Bitmap newBitmap = new Bitmap(original.Width, original.Height); //get a graphics object