利用机器学习预测房价
项目介绍
背景:
DC竞赛比赛项目,运用回归模型进行房价预测。
数据介绍:
数据主要包括2014年5月至2015年5月美国King County的房屋销售价格以及房屋的基本信息。
其中训练数据主要包括10000条记录,14个字段,分别代表:
- 销售日期(date):2014年5月到2015年5月房屋出售时的日期;
- 销售价格(price):房屋交易价格,单位为美元,是目标预测值;
- 卧室数(bedroom_num):房屋中的卧室数目;
- 浴室数(bathroom_num):房屋中的浴室数目;
- 房屋面积(house_area):房屋里的生活面积;
- 停车面积(park_space):停车坪的面积;
- 楼层数(floor_num):房屋的楼层数;
- 房屋评分(house_score):King County房屋评分系统对房屋的总体评分;
- 建筑面积(covered_area):除了地下室之外的房屋建筑面积;
- 地下室面积(basement_area):地下室的面积;
- 建筑年份(yearbuilt):房屋建成的年份;
- 修复年份(yearremodadd):房屋上次修复的年份;
- 纬度(lat):房屋所在纬度;
- 经度(long):房屋所在经度。
目标:
算法通过计算平均预测误差来衡量回归模型的优劣。平均预测误差越小,说明回归模型越好。
代码详解
数据导入
先导入分析需要的python包:
#导入类库和加载数据集 import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns %matplotlib inline
导入下载好的kc_train的csv文件:
#读取数据
train_names = ["date",
"price",
"bedroom_num",
"bathroom_num",
"house_area",
"park_space",
"floor_num",
"house_score",
"covered_area",
"basement_area",
"yearbuilt",
"yearremodadd",
"lat",
"long"]
data = pd.read_csv("kc_train.csv",names=train_names)
data.head()

数据预处理
查看数据集概况
# 观察数据集概况 data.info()
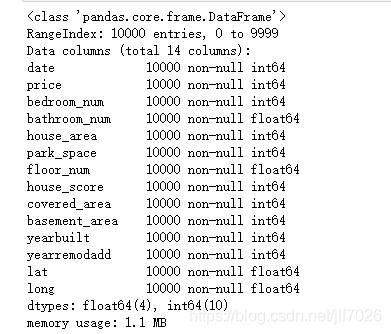
从图中可以看出没有任何缺失值,因此不需要对缺失值进行处理。
拆分数据:
把原始数据中的年月日拆开,然后根据房屋的建造年份和修复年份计算一下售出时已经过了多少年,这样就有17个特征。
sell_year,sell_month,sell_day=[],[],[]
house_old,fix_old=[],[]
for [date,yearbuilt,yearremodadd] in data[['date','yearbuilt','yearremodadd']].values:
year,month,day=date//10000,date%10000//100,date%100
sell_year.append(year)
sell_month.append(month)
sell_day.append(day)
house_old.append(year-yearbuilt)
if yearremodadd==0:
fix_old.append(0)
else:
fix_old.append(year-yearremodadd)
del data['date']
data['sell_year']=pd.DataFrame({'sell_year':sell_year})
data['sell_month']=pd.DataFrame({'sell_month':sell_month})
data['sell_day']=pd.DataFrame({'sell_day':sell_day})
data['house_old']=pd.DataFrame({'house_old':house_old})
data['fix_old']=pd.DataFrame({'fix_old':fix_old})
data.head()

观察因变量(price)数据情况
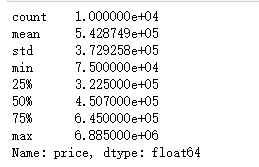
#观察数据 print(data['price'].describe())
#观察price的数据分布
plt.figure(figsize = (10,5))
# plt.xlabel('price')
sns.distplot(data['price'])
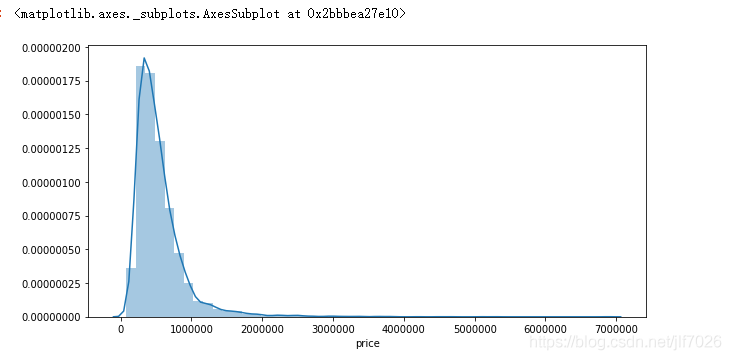
从数据和图片上可以看出,price呈现典型的右偏分布,但总体上看还是符合一般规律。
相关性分析
自变量与因变量的相关性分析,绘制相关性矩阵热力图,比较各个变量之间的相关性:
#自变量与因变量的相关性分析
plt.figure(figsize = (20,10))
internal_chars = ['price','bedroom_num','bathroom_num','house_area','park_space','floor_num','house_score','covered_area'
,'basement_area','yearbuilt','yearremodadd','lat','long','sell_year','sell_month','sell_day',
'house_old','fix_old']
corrmat = data[internal_chars].corr() # 计算相关系数
sns.heatmap(corrmat, square=False, linewidths=.5, annot=True) #热力图
csdn.net/jlf7026/article/details/84630414
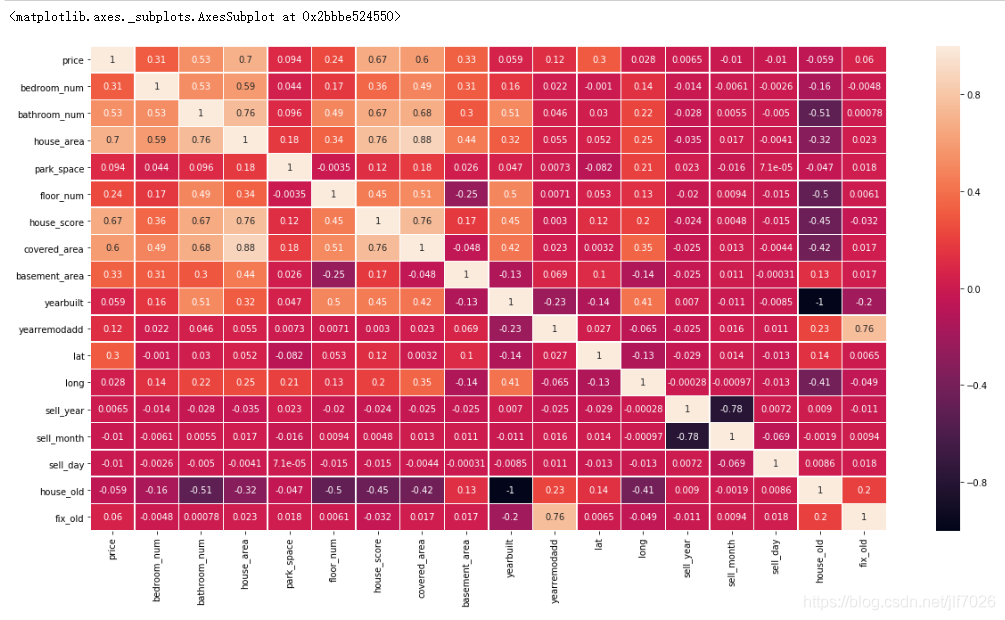
相关性越大,颜色越浅。看着可能不太清楚,因此看下排名
#打印出相关性的排名 print(corrmat["price"].sort_values(ascending=False))
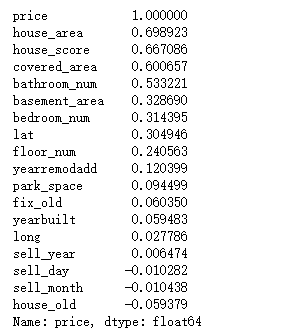
可以看出house_area,house_score,covered_area,bathroom_num这四个特征对price的影响最大,都超过了0.5。负数表明与price是负相关的。
特征选择
一般来说,选择一些与因变量(price)相关性比较大的做特征,但我尝试过选择前十的特征,然后进行建模预测,但得到的结果并不是很好,所以我还是把现有的特征全部用上。
归一化
对于各个特征的数据范围不一样,影响线性回归的效果,因此归一化数据。
#特征缩放
data = data.astype('float')
x = data.drop('price',axis=1)
y = data['price']
from sklearn.preprocessing import MinMaxScaler
scaler = MinMaxScaler()
newX= scaler.fit_transform(x)
newX = pd.DataFrame(newX, columns=x.columns)
newX.head()

划分数据集
#先将数据集分成训练集和测试集 from sklearn.model_selection import train_test_split X_train,X_test,y_train,y_test = train_test_split(newX, y, test_size=0.2, random_state=21)
建立模型
选择两个模型进行预测,观察那个模型更好。
- 线性回归
- 随机森林
#模型建立
from sklearn import metrics
def RF(X_train, X_test, y_train, y_test): #随机森林
from sklearn.ensemble import RandomForestRegressor
model= RandomForestRegressor(n_estimators=200,max_features=None)
model.fit(X_train, y_train)
predicted= model.predict(X_test)
mse = metrics.mean_squared_error(y_test,predicted)
return (mse/10000)
def LR(X_train, X_test, y_train, y_test): #线性回归
from sklearn.linear_model import LinearRegression
LR = LinearRegression()
LR.fit(X_train, y_train)
predicted = LR.predict(X_test)
mse = metrics.mean_squared_error(y_test,predicted)
return (mse/10000)
评价标准
算法通过计算平均预测误差来衡量回归模型的优劣。平均预测误差越小,说明回归模型越好。
print('RF mse: ',RF(X_train, X_test, y_train, y_test))
print('LR mse: ',LR(X_train, X_test, y_train, y_test))

可以看出,随机森林算法比线性回归算法要好很多。
总结
对机器学习有了初步了解。但对于数据的预处理,和参数,特征,模型的调优还很欠缺。
希望通过以后的学习,能不断提高。也希望看这篇文章的朋友和我一起感受机器学习的魅力,更多相关机器学习内容请搜索我们以前的文章或继续浏览下面的相关文章,希望大家以后多多支持我们!
相关推荐
-
Python实现新型冠状病毒传播模型及预测代码实例
1.传染及发病过程 一个健康人感染病毒后进入潜伏期(时间长度为Q天),潜伏期之后进入发病期(时间长度为D天),发病期之后该患者有三个可能去向,分别是自愈.接收隔离.死亡. 2.模型假设 潜伏期Q=7天,根据报道潜伏期为2~14天,取中间值:发病期D=10天,根据文献报告,WHO认定SARS发病期为10天,假设武汉肺炎与此相同:潜伏期的患者不具有将病毒传染给他人的能力:发病期的患者具有将病毒传染给他人的能力:患者在发病期之后不再具有将病毒传染他人的能力:假设处于发病期的患者平均每天密切接触1人,致
-

如何用Python进行时间序列分解和预测
预测是一件复杂的事情,在这方面做得好的企业会在同行业中出类拔萃.时间序列预测的需求不仅存在于各类业务场景当中,而且通常需要对未来几年甚至几分钟之后的时间序列进行预测.如果你正要着手进行时间序列预测,那么本文将带你快速掌握一些必不可少的概念. 目录 什么是时间序列? 如何在Python中绘制时间序列数据? 时间序列的要素是什么? 如何分解时间序列? 经典分解法 如何获得季节性调整值? STL分解法 时间序列预测的基本方法: Python中的简单移动平均(SMA) 为什么使用简单移动平均? Pyth
-
详解用Python进行时间序列预测的7种方法
数据准备 数据集(JetRail高铁的乘客数量)下载. 假设要解决一个时序问题:根据过往两年的数据(2012 年 8 月至 2014 年 8月),需要用这些数据预测接下来 7 个月的乘客数量. import pandas as pd import numpy as np import matplotlib.pyplot as plt df = pd.read_csv('train.csv') df.head() df.shape 依照上面的代码,我们获得了 2012-2014 年两年每个小时的乘
-
利用keras使用神经网络预测销量操作
keras非常方便. 不解释,直接上实例. 数据格式如下: 序号 天气 是否周末 是否有促销 销量 1 坏 是 是 高 2 坏 是 是 高 3 坏 是 是 高 4 坏 否 是 高 5 坏 是 是 高 6 坏 否 是 高 7 坏 是 否 高 8 好 是 是 高 9 好 是 否 高 10 好 是 是 高 11 好 是 是 高 12 好 是 是 高 13 好 是 是 高 14 坏 是 是 低 15 好 否 是 高 16 好 否 是 高 17 好 否 是 高 18 好 否 是 高 19 好 否 否 高
-
Datawhale练习之二手车价格预测
数据探索性分析(EDA) 1. 总览数据概况 数据库载入 #coding:utf-8 #导入warnings包,利用过滤器来实现忽略警告语句. import warnings warnings.filterwarnings('ignore') import pandas as pd import numpy as np import matplotlib.pyplot as plt import seaborn as sns import missingno as msno 数据载入 ## 1)
-
利用机器学习预测房价
项目介绍 背景: DC竞赛比赛项目,运用回归模型进行房价预测. 数据介绍: 数据主要包括2014年5月至2015年5月美国King County的房屋销售价格以及房屋的基本信息. 其中训练数据主要包括10000条记录,14个字段,分别代表: 销售日期(date):2014年5月到2015年5月房屋出售时的日期: 销售价格(price):房屋交易价格,单位为美元,是目标预测值: 卧室数(bedroom_num):房屋中的卧室数目: 浴室数(bathroom_num):房屋中的浴室数目: 房屋面积(
-
python基于机器学习预测股票交易信号
引言 近年来,随着技术的发展,机器学习和深度学习在金融资产量化研究上的应用越来越广泛和深入.目前,大量数据科学家在Kaggle网站上发布了使用机器学习/深度学习模型对股票.期货.比特币等金融资产做预测和分析的文章.从金融投资的角度看,这些文章可能缺乏一定的理论基础支撑(或交易思维),大都是基于数据挖掘.但从量化的角度看,有很多值得我们学习参考的地方,尤其是Pyhton的深入应用.数据可视化和机器学习模型的评估与优化等.下面借鉴Kaggle上的一篇文章<Building an Asset Trad
-
Python利用机器学习算法实现垃圾邮件的识别
开发工具 **Python版本:**3.6.4 相关模块: scikit-learn模块: jieba模块: numpy模块: 以及一些Python自带的模块. 环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 逐步实现 (1)划分数据集 网上用于垃圾邮件识别的数据集大多是英文邮件,所以为了表示诚意,我花了点时间找了一份中文邮件的数据集.数据集划分如下: 训练数据集: 7063封正常邮件(data/normal文件夹下): 7775封垃圾邮件(data/spam文件夹下
-
运用PyTorch动手搭建一个共享单车预测器
本文摘自 <深度学习原理与PyTorch实战> 我们将从预测某地的共享单车数量这个实际问题出发,带领读者走进神经网络的殿堂,运用PyTorch动手搭建一个共享单车预测器,在实战过程中掌握神经元.神经网络.激活函数.机器学习等基本概念,以及数据预处理的方法.此外,还会揭秘神经网络这个"黑箱",看看它如何工作,哪个神经元起到了关键作用,从而让读者对神经网络的运作原理有更深入的了解. 3.1 共享单车的烦恼 大约从2016年起,我们的身边出现了很多共享单车.五颜六色.各式各样的共
-
深度学习详解之初试机器学习
机器学习可应用在各个方面,本篇将在系统性进入机器学习方向前,初步认识机器学习,利用线性回归预测波士顿房价: 原理简介 利用线性回归最简单的形式预测房价,只需要把它当做是一次线性函数y=kx+b即可.我要做的就是利用已有数据,去学习得到这条直线,有了这条直线,则对于某个特征x(比如住宅平均房间数)的任意取值,都可以找到直线上对应的房价y,也就是模型的预测值. 从上面的问题看出,这应该是一个有监督学习中的回归问题,待学习的参数为实数k和实数b(因为就只有一个特征x),从样本集合sample中取出一对
-
Python机器学习入门(一)序章
目录 前言 写在前面 1.什么是机器学习? 1.1 监督学习 1.2无监督学习 2.Python中的机器学习 3.必须环境安装 Anacodna安装 总结 前言 每一次变革都由技术驱动.纵观人类历史,上古时代,人类从采集狩猎社会,进化为农业社会:由农业社会进入到工业社会:从工业社会到现在信息社会.每一次变革,都由新技术引导. 在历次的技术革命中,一个人.一家企业,甚至一个国家,可以选择的道路只有两条:要么加入时代的变革,勇立潮头:要么徘徊观望,抱憾终生. 要想成为时代弄潮儿,就要积极拥抱这次智能
-
Tensorflow 利用tf.contrib.learn建立输入函数的方法
在实际的业务中,可能会遇到很大量的特征,这些特征良莠不齐,层次不一,可能有缺失,可能有噪声,可能规模不一致,可能类型不一样,等等问题都需要我们在建模之前,先预处理特征或者叫清洗特征.那么这清洗特征的过程可能涉及多个步骤可能比较复杂,为了代码的简洁,我们可以将所有的预处理过程封装成一个函数,然后直接往模型中传入这个函数就可以啦~~~ 接下来我们看看究竟如何做呢? 1. 如何使用input_fn自定义输入管道 当使用tf.contrib.learn来训练一个神经网络时,可以将特征,标签数据直接输入到
-
使用Python机器学习降低静态日志噪声
持续集成(CI)作业可以产生大量的数据.当作业失败时,找出了什么问题可能是一个繁琐的过程,需要对日志进行调查以发现根本原因-这通常是在作业总输出的一小部分中发现的.为了更容易地将最相关的数据从其他数据中分离出来,日志还原机器学习模型使用以前成功的作业运行来训练,以从失败的运行日志中提取异常. 此原则也可应用于其他用例,例如,从期刊或其他系统范围的常规日志文件. 利用机器学习降低噪声 一个典型的日志文件包含许多名义事件("基线")以及一些与开发人员相关的异常.基线可能包含难以检测和删除的
-
python神经网络学习利用PyTorch进行回归运算
目录 学习前言 PyTorch中的重要基础函数 1.class Net(torch.nn.Module)神经网络的构建: 2.optimizer优化器 3.loss损失函数定义 4.训练过程 全部代码 学习前言 我发现不仅有很多的Keras模型,还有很多的PyTorch模型,还是学学Pytorch吧,我也想了解以下tensor到底是个啥. PyTorch中的重要基础函数 1.class Net(torch.nn.Module)神经网络的构建: PyTorch中神经网络的构建和Tensorflow
-
PyTorch搭建LSTM实现多变量时序负荷预测
目录 I. 前言 II. 数据处理 III. LSTM模型 IV. 训练 V. 测试 VI. 源码及数据 I. 前言 在前面的一篇文章PyTorch搭建LSTM实现时间序列预测(负荷预测)中,我们利用LSTM实现了负荷预测,但我们只是简单利用负荷预测负荷,并没有利用到其他一些环境变量,比如温度.湿度等. 本篇文章主要考虑用PyTorch搭建LSTM实现多变量时间序列预测. 系列文章: PyTorch搭建LSTM实现多变量多步长时序负荷预测 PyTorch深度学习LSTM从input输入到Line