pandas数据处理之 标签列字符转数字的实现
机器学习中,当我们在进行数据预处理的时候,对于标签列非字符的数据,我们往往需要将其转换成字符,因为有的算法可能不支持非数字类型来做特征。
那么怎么快捷地来着这个转换呢,请看我的示例:
1.构建测试数据
import pandas as pd array = ['good','bad','well','bad','good','good','well','good']
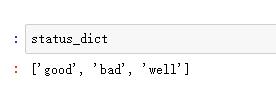
2.数据转换下,并获取标签列的字典
df = pd.DataFrame(array,columns=['status']) status_dict = df['status'].unique().tolist()
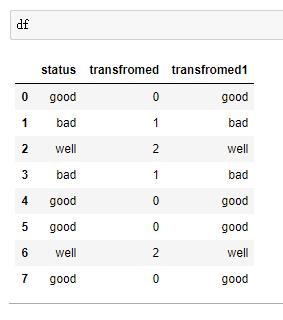
3.使用函数进行转换
df['transfromed']=df['status'].apply(lambda x : status_dict.index(x))

这样,就将标签列处理好了哈
等用完之后,再转回来
df['transfromed1']= df['transfromed'].apply(lambda x : status_dict[x])
补充:pandas factorize将字符串特征转化为数字特征
将原始数据中的字符串特征转化为模型可以识别的数字特征可是使用pandas自带的factorzie方法。
原始数据的job特征值如下

都是字符串特征,无法用于训练,当然可以单独建立map硬编码处理,但是pandas已经封装好了相应的方法。
data = pd.read_csv("data/test_set.csv")
data["job"] = pd.factorize(data["job"])[0].astype(np.uint16)

以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-

pandas 选取行和列数据的方法详解
前言 本文介绍在 pandas 中如何读取数据行列的方法.数据由行和列组成,在数据库中,一般行被称作记录 (record),列被称作字段 (field).回顾一下我们对记录和字段的获取方式:一般情况下,字段根据名称获取,记录根据筛选条件获取.比如获取 student_id 和 studnent_name 两个字段:记录筛选,比如 sales_amount 大于 10000 的所有记录.对于熟悉 SQL 语句的人来说,就是下面的语句: select student_id, student_name
-
利用Pandas来清除重复数据的实现方法
一.前言 最近刚好在练手一个数据挖掘的项目,众所周知,数据挖掘中比较重要的一步为数据清洗,而对重复数据的处理也是数据清洗中经常碰到的一项.本文将仅介绍如何利用Pandas来清除重复数据(主要指重复行),话不多说请看下文. 二.具体介绍 2.1. 导入Pandas库 pandas是python的核心数据分析库,你可以把它理解为python版的excel,倘若你还没有安装相应的库,请查询相关教程进行安装,导入pandas的代码为: import pandas as pd 2.2. DataFrame
-
Pandas实现数据类型转换的一些小技巧汇总
前言 Pandas是Python当中重要的数据分析工具,利用Pandas进行数据分析时,确保使用正确的数据类型是非常重要的,否则可能会导致一些不可预知的错误发生. Pandas 的数据类型:数据类型本质上是编程语言用来理解如何存储和操作数据的内部结构.例如,一个程序需要理解你可以将两个数字加起来,比如 5 + 10 得到 15.或者,如果是两个字符串,比如「cat」和「hat」,你可以将它们连接(加)起来得到「cathat」.尚学堂•百战程序员陈老师指出有关 Pandas 数据类型的一个可能令人
-
pandas对dataFrame中某一个列的数据进行处理的方法
背景:dataFrame的数据,想对某一个列做逻辑处理,生成新的列,或覆盖原有列的值 下面例子中的df均为pandas.DataFrame()的数据 1.增加新列,或更改某列的值 df["列名"]=值 如果值为固定的一个值,则dataFrame中该列所有值均为这个数据 2.处理某列 df["列名"]=df.apply(lambda x:方法名(x,入参2),axis=1) 说明: 1.方法名为单独的方法名,可以处理传入的x数据 2.x为每一行的数据,做为方法的入参1
-
pandas数据处理之 标签列字符转数字的实现
机器学习中,当我们在进行数据预处理的时候,对于标签列非字符的数据,我们往往需要将其转换成字符,因为有的算法可能不支持非数字类型来做特征. 那么怎么快捷地来着这个转换呢,请看我的示例: 1.构建测试数据 import pandas as pd array = ['good','bad','well','bad','good','good','well','good'] 2.数据转换下,并获取标签列的字典 df = pd.DataFrame(array,columns=['status']) sta
-
使用pandas把某一列的字符值转换为数字的实例
今天小编就为大家分享一篇使用pandas把某一列的字符值转换为数字的实例,具有很好的参考价值,希望对大家有所帮助.一起跟随小编过来看看吧 使用map的方法就可以实现把某一列的字符类型的值转换为数字. class_mapping = {'A':0, 'B':1} data[class] = data[class].map(class_mapping) 首先定义一个字典,然后使用map方法就可以把某一列的字符类型的值转换为数字. 以上就是对使用pandas把某一列的字符值转换为数字的认识. 这篇使用
-
pandas数据处理基础之筛选指定行或者指定列的数据
pandas主要的两个数据结构是:series(相当于一行或一列数据机构)和DataFrame(相当于多行多列的一个表格数据机构). 本文为了方便理解会与excel或者sql操作行或列来进行联想类比 1.重新索引:reindex和ix 上一篇中介绍过数据读取后默认的行索引是0,1,2,3...这样的顺序号.列索引相当于字段名(即第一行数据),这里重新索引意思就是可以将默认的索引重新修改成自己想要的样子. 1.1 Series 比方说:data=Series([4,5,6],index=['a',
-
python pandas数据处理之删除特定行与列
目录 dropna() 方法过滤任何含有缺失值的行 方法一:dropna() 其他参数解析 方法二:替换并删除,Python pandas 如果某列值为空,过滤删除所在行数据 总结 dropna() 方法过滤任何含有缺失值的行 pandas.DataFrame里,如果一行数据有任意值为空,则过滤掉整行,这时候使用dropna()方法是合适的.下面的案例,任意列只要有一个为空数据,则整行都干掉.但是我们常常遇到的情况,是根据一个指标(一列)数据的情况,去过滤行数据,类似Excel里面的过滤漏斗,怎
-
Python Pandas数据处理高频操作详解
目录 引入依赖 算法相关依赖 获取数据 生成df 重命名列 增加列 缺失值处理 独热编码 替换值 删除列 数据筛选 差值计算 数据修改 时间格式转换 设置索引列 折线图 散点图 柱状图 热力图 66个最常用的pandas数据分析函数 从各种不同的来源和格式导入数据 导出数据 创建测试对象 查看.检查数据 数据选取 数据清理 筛选,排序和分组依据 数据合并 数据统计 16个函数,用于数据清洗 1.cat函数 2.contains 3.startswith/endswith 4.count 5.ge
-
Pandas 数据处理,数据清洗详解
如下所示: # -*-coding:utf-8-*- from pandas import DataFrame import pandas as pd import numpy as np """ 获取行列数据 """ df = DataFrame(np.random.rand(4, 5), columns=['A', 'B', 'C', 'D', 'E']) print df print df['col_sum'] = df.apply(lam
-
pandas.loc 选取指定列进行操作的实例
今天发现用pandas里面的数据结构可以减少大量的编程工作,从现在开始逐渐积累,记录一下: 使用标签选取数据: df.loc[行标签,列标签] df.loc['a':'b']#选取ab两行数据 df.loc[:,'one']#选取one列的数据 df.loc的第一个参数是行标签,第二个参数为列标签(可选参数,默认为所有列标签),两个参数既可以是列表也可以是单个字符,如果两个参数都为列表则返回的是DataFrame,否则,则为Series. 示例代码: df.loc[ (df.Cabin.notn
-
pandas添加自增列的2种实现方案
有时候我们需要添加一列自动增加数字的列,可以用下面两种方法: 第一种 >>> import pandas as pd >>> df = pd.DataFrame([{'name':'apple', 'count':4},\ {'name':'orange', 'count':2}]) >>> df = df.reset_index() >>> df.columns.values[0] = 'New_ID' >>> d
-
python pandas数据处理教程之合并与拼接
目录 前言 一.join 1.leftjoin 2.rightjoin 3.innerjoin 4.outjoin 二.merge 三.concat 1.纵向合并 2.横向合并 四.append 1.同结构数据追加 2.不同结构数据追加 3.追加合并多个数据集 五.combine_first 六.update 总结 前言 在许多应用中,数据可能来自不同的渠道,在数据处理的过程中常常需要将这些数据集进行组合合并拼接,形成更加丰富的数据集.pandas提供了多种方法完全可以满足数据处理的常用需求.具
-
Pandas数据处理加速技巧汇总
目录 数据准备 日期时间数据优化 数据的简单循环 循环 .itertuples() 和 .iterrows() 方法 .apply() 方法 .isin() 数据选择 .cut() 数据分箱 Numpy 方法处理 处理效率比较 HDFStore 防止重新处理 Pandas 处理数据的效率还是很优秀的,相对于大规模的数据集只要掌握好正确的方法,就能让在数据处理时间上节省很多很多的时间. Pandas 是建立在 NumPy 数组结构之上的,许多操作都是在 C 中执行的,要么通过 NumPy,要么通过