python实现Scrapy爬取网易新闻
1. 新建项目
在命令行窗口下输入scrapy startproject scrapytest, 如下
然后就自动创建了相应的文件,如下
2. 修改itmes.py文件
打开scrapy框架自动创建的items.py文件,如下
# Define here the models for your scraped items # # See documentation in: # https://docs.scrapy.org/en/latest/topics/items.html import scrapy class ScrapytestItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() pass
编写里面的代码,确定我要获取的信息,比如新闻标题,url,时间,来源,来源的url,新闻的内容等
class ScrapytestItem(scrapy.Item): # define the fields for your item here like: # name = scrapy.Field() title = scrapy.Field() timestamp = scrapy.Field() category = scrapy.Field() content = scrapy.Field() url = scrapy.Field() pass
3. 定义spider,创建一个爬虫模板
3.1 创建crawl爬虫模板
在命令行窗口下面 创建一个crawl爬虫模板(注意在文件的根目录下面,指令检查别输入错误,-t 表示使用后面的crawl模板),会在spider文件夹生成一个news163.py文件
scrapy genspider -t crawl codingce news.163.com
然后看一下这个‘crawl'模板和一般的模板有什么区别,多了链接提取器还有一些爬虫规则,这样就有利于我们做一些深度信息的爬取
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'Items/'), callback='parse_item', follow=True),
)
def parse_item(self, response):
item = {}
#item['domain_id'] = response.xpath('//input[@id="sid"]/@value').get()
#item['name'] = response.xpath('//div[@id="name"]').get()
#item['description'] = response.xpath('//div[@id="description"]').get()
return item
3.2 补充知识:selectors选择器
支持xpath和css,xpath语法如下
/html/head/title /html/head/title/text() //td (深度提取的话就是两个/) //div[@class=‘mine']
3.3. 分析网页内容
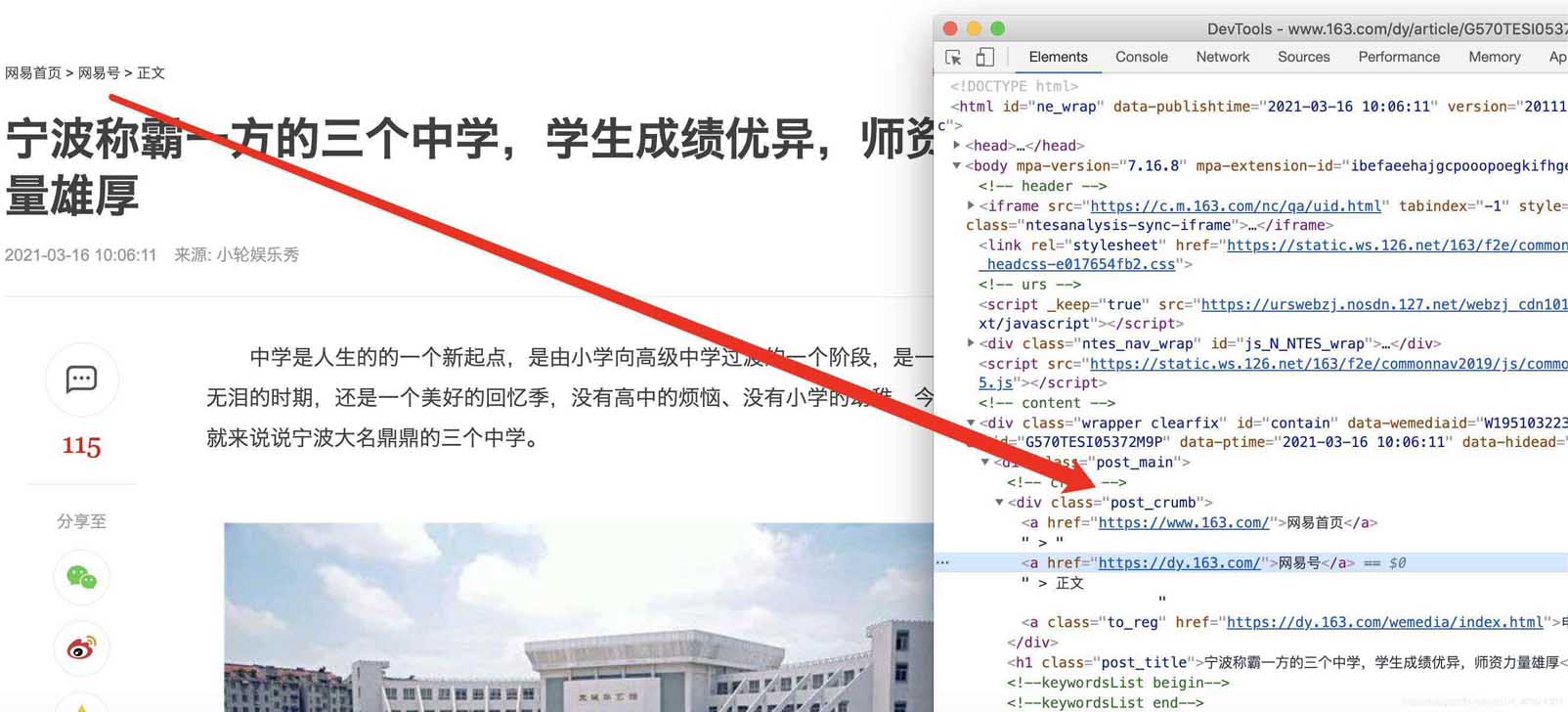
在谷歌chrome浏览器下,打在网页新闻的网站,选择查看源代码,确认我们可以获取到itmes.py文件的内容(其实那里面的要获取的就是查看了网页源代码之后确定可以获取的)
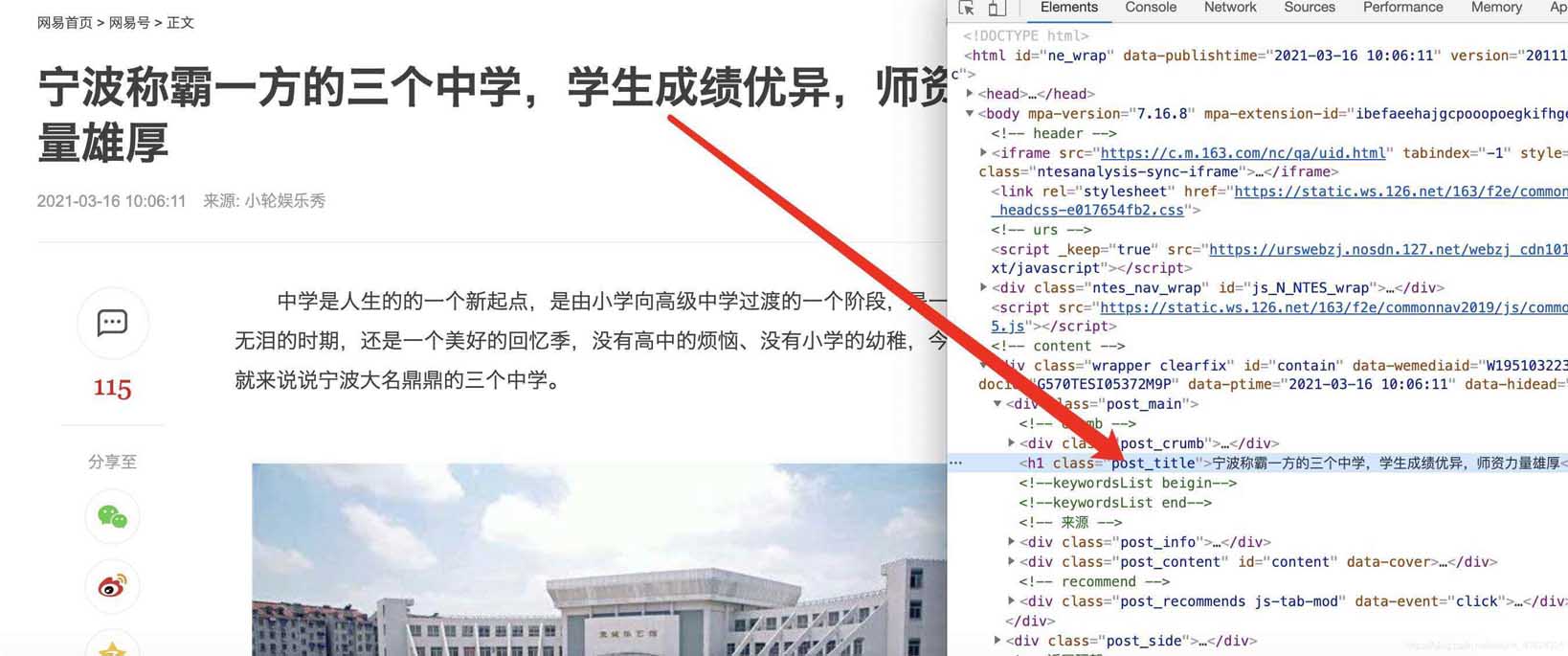
确认标题、时间、url、来源url和内容可以通过检查和标签对应上,比如正文部分
主体

标题
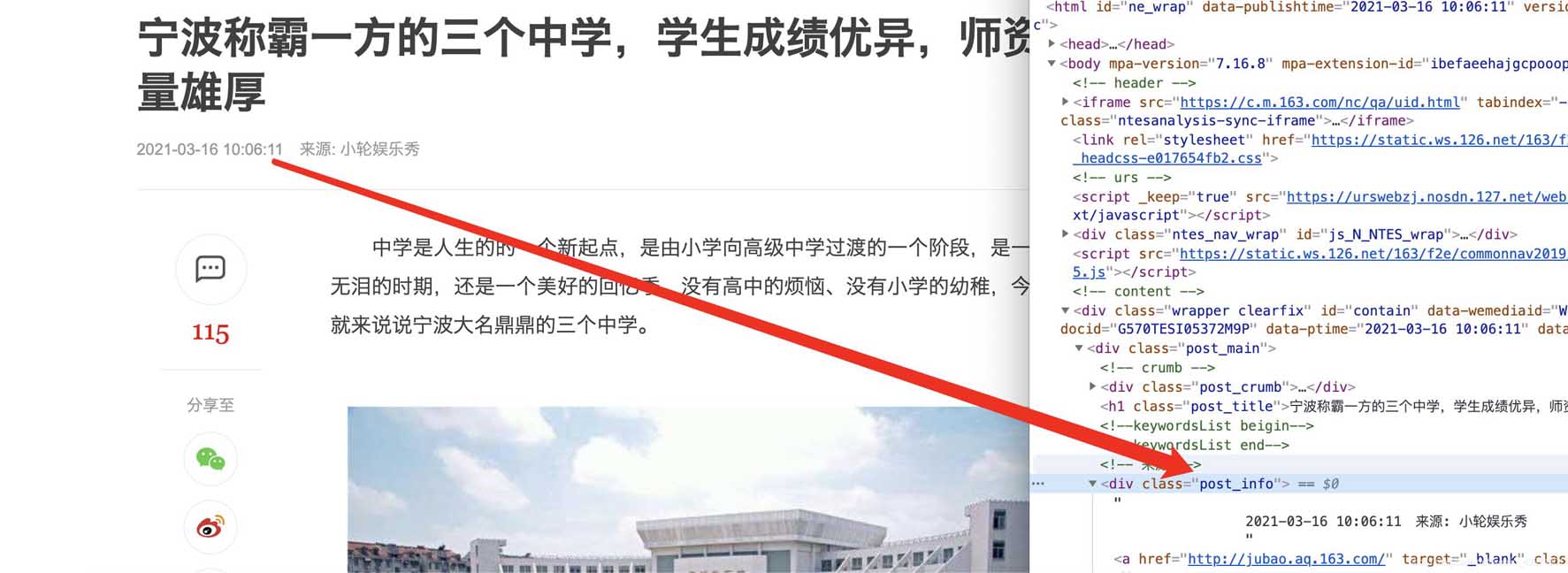
时间
分类
4. 修改spider下创建的爬虫文件
4.1 导入包
打开创建的爬虫模板,进行代码的编写,除了导入系统自动创建的三个库,我们还需要导入news.items(这里就涉及到了包的概念了,最开始说的–init–.py文件存在说明这个文件夹就是一个包可以直接导入,不需要安装)
注意:使用的类ExampleSpider一定要继承自CrawlSpider,因为最开始我们创建的就是一个‘crawl'的爬虫模板,对应上
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*\.163\.com/\d{2}/\d{4}/\d{2}/.*\.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = '<br>'.join(response.css('.post_content p::text').getall())
if len(content) < 100:
return
return item
Rule(LinkExtractor(allow=r'..163.com/\d{2}/\d{4}/\d{2}/..html'), callback=‘parse', follow=True), 其中第一个allow里面是书写正则表达式的(也是我们核心要输入的内容),第二个是回调函数,第三个表示是否允许深入
最终代码
from datetime import datetime
import re
import scrapy
from scrapy.linkextractors import LinkExtractor
from scrapy.spiders import CrawlSpider, Rule
from scrapytest.items import ScrapytestItem
class CodingceSpider(CrawlSpider):
name = 'codingce'
allowed_domains = ['163.com']
start_urls = ['http://news.163.com/']
rules = (
Rule(LinkExtractor(allow=r'.*\.163\.com/\d{2}/\d{4}/\d{2}/.*\.html'), callback='parse', follow=True),
)
def parse(self, response):
item = {}
content = '<br>'.join(response.css('.post_content p::text').getall())
if len(content) < 100:
return
title = response.css('h1::text').get()
category = response.css('.post_crumb a::text').getall()[-1]
print(category, "=======category")
time_text = response.css('.post_info::text').get()
timestamp_text = re.search(r'\d{4}-\d{2}-\d{2} \d{2}:\d{2}:\d{2}', time_text).group()
timestamp = datetime.fromisoformat(timestamp_text)
print(title, "=========title")
print(content, "===============content")
print(timestamp, "==============timestamp")
print(response.url)
return item

到此这篇关于python实现Scrapy爬取网易新闻的文章就介绍到这了,更多相关python Scrapy爬取网易新闻内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
Python使用Scrapy爬取妹子图
Python Scrapy爬虫,听说妹子图挺火,我整站爬取了,上周一共搞了大概8000多张图片.和大家分享一下. 核心爬虫代码 # -*- coding: utf-8 -*- from scrapy.selector import Selector import scrapy from scrapy.contrib.loader import ItemLoader, Identity from fun.items import MeizituItem class MeizituSpider(sc
-
Python Scrapy多页数据爬取实现过程解析
1.先指定通用模板 url = 'https://www.qiushibaike.com/text/page/%d/'#通用的url模板 pageNum = 1 2.对parse方法递归处理 parse第一次调用表示的是用来解析第一页对应页面中的数据 对后面的页码的数据要进行手动发送 if self.pageNum <= 5: self.pageNum += 1 new_url = format(self.url%self.pageNum) #手动请求(get)的发送 yield scrapy.
-

基于python框架Scrapy爬取自己的博客内容过程详解
前言 python中常用的写爬虫的库常有urllib2.requests,对于大多数比较简单的场景或者以学习为目的,可以用这两个库实现.这里有一篇我之前写过的用urllib2+BeautifulSoup做的一个抓取百度音乐热门歌曲的例子,有兴趣可以看一下. 本文介绍用Scrapy抓取我在博客园的博客列表,只抓取博客名称.发布日期.阅读量和评论量这四个简单的字段,以求用较简单的示例说明Scrapy的最基本的用法. 环境配置说明 操作系统:Ubuntu 14.04.2 LTS Python:Pyth
-
Python下使用Scrapy爬取网页内容的实例
上周用了一周的时间学习了Python和Scrapy,实现了从0到1完整的网页爬虫实现.研究的时候很痛苦,但是很享受,做技术的嘛. 首先,安装Python,坑太多了,一个个爬.由于我是windows环境,没钱买mac, 在安装的时候遇到各种各样的问题,确实各种各样的依赖. 安装教程不再赘述.如果在安装的过程中遇到 ERROR:需要windows c/c++问题,一般是由于缺少windows开发编译环境,晚上大多数教程是安装一个VisualStudio,太不靠谱了,事实上只要安装一个WindowsS
-
使用Python的Scrapy框架十分钟爬取美女图
简介 scrapy 是一个 python 下面功能丰富.使用快捷方便的爬虫框架.用 scrapy 可以快速的开发一个简单的爬虫,官方给出的一个简单例子足以证明其强大: 快速开发 下面开始10分钟倒计时: 当然开始前,可以先看看之前我们写过的 scrapy 入门文章 <零基础写python爬虫之使用Scrapy框架编写爬虫 1. 初始化项目 scrapy startproject mzt cd mzt scrapy genspider meizitu meizitu.com 2. 添加 spide
-
Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据
-
Scrapy框架爬取Boss直聘网Python职位信息的源码
分析 使用CrawlSpider结合LinkExtractor和Rule爬取网页信息 LinkExtractor用于定义链接提取规则,一般使用allow参数即可 LinkExtractor(allow=(), # 使用正则定义提取规则 deny=(), # 排除规则 allow_domains=(), # 限定域名范围 deny_domains=(), # 排除域名范围 restrict_xpaths=(), # 使用xpath定义提取队则 tags=('a', 'area'), attrs=(
-
Python Scrapy图片爬取原理及代码实例
1.在爬虫文件中只需要解析提取出图片地址,然后将地址提交给管道 在管道文件对图片进行下载和持久化存储 class ImgSpider(scrapy.Spider): name = 'img' # allowed_domains = ['www.xxx.com'] start_urls = ['http://www.521609.com/daxuemeinv/'] url = 'http://www.521609.com/daxuemeinv/list8%d.html' pageNum = 1 d
-
Python使用scrapy爬取阳光热线问政平台过程解析
目的:爬取阳光热线问政平台问题反映每个帖子里面的标题.内容.编号和帖子url CrawlSpider版流程如下: 创建爬虫项目dongguang scrapy startproject dongguang 设置items.py文件 # -*- coding: utf-8 -*- import scrapy class NewdongguanItem(scrapy.Item): # define the fields for your item here like: # name = scrapy
-
Python scrapy增量爬取实例及实现过程解析
这篇文章主要介绍了Python scrapy增量爬取实例及实现过程解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 开始接触爬虫的时候还是初学Python的那会,用的还是request.bs4.pandas,再后面接触scrapy做个一两个爬虫,觉得还是框架好,可惜都没有记录都忘记了,现在做推荐系统需要爬取一定的文章,所以又把scrapy捡起来.趁着这次机会做一个记录. 目录如下: 环境 本地窗口调试命令 工程目录 xpath选择器 一个简单