单身狗福利?Python爬取某婚恋网征婚数据
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1
一、打开界面
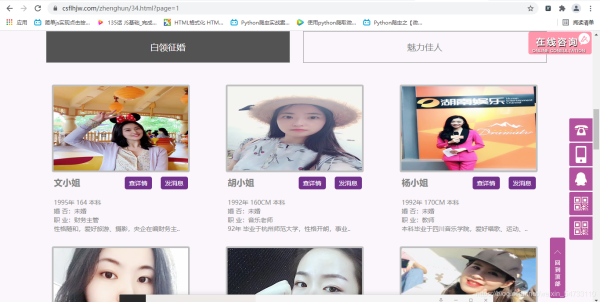
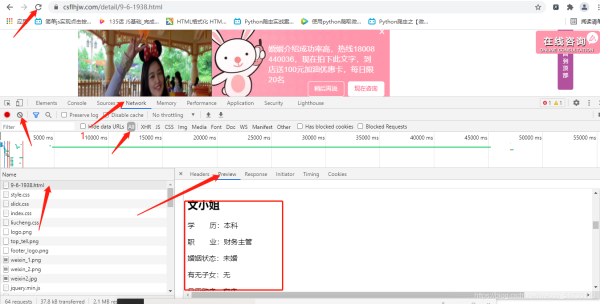
鼠标右键打开检查,方框里为你一个文小姐的征婚信息。。由此判断出为同步加载
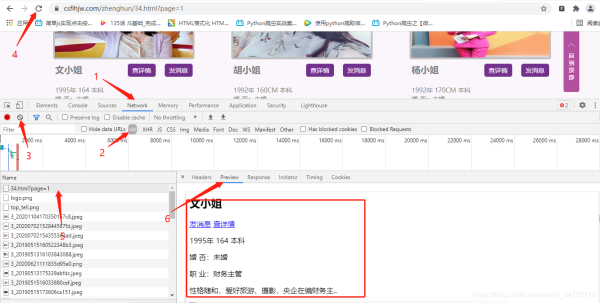
点击elements,定位图片地址,方框里为该女士的url地址及图片地址
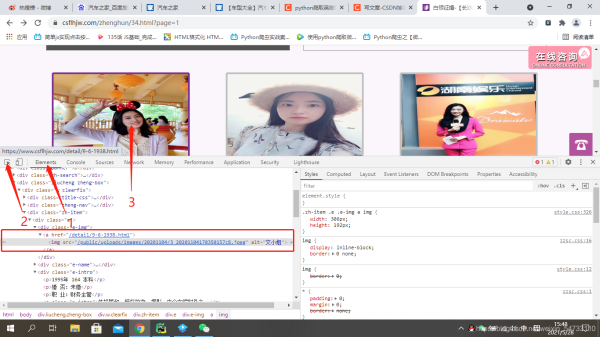
可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化
点击第2页
https://www.csflhjw.com/zhenghun/34.html?page=2
点击第3页
https://www.csflhjw.com/zhenghun/34.html?page=3
可以看出变化在最后
做一下fou循环格式化输出一下。。一共10页
二、代码解析
1.获取所有的女士的url,xpath的路径就不详细说了。。
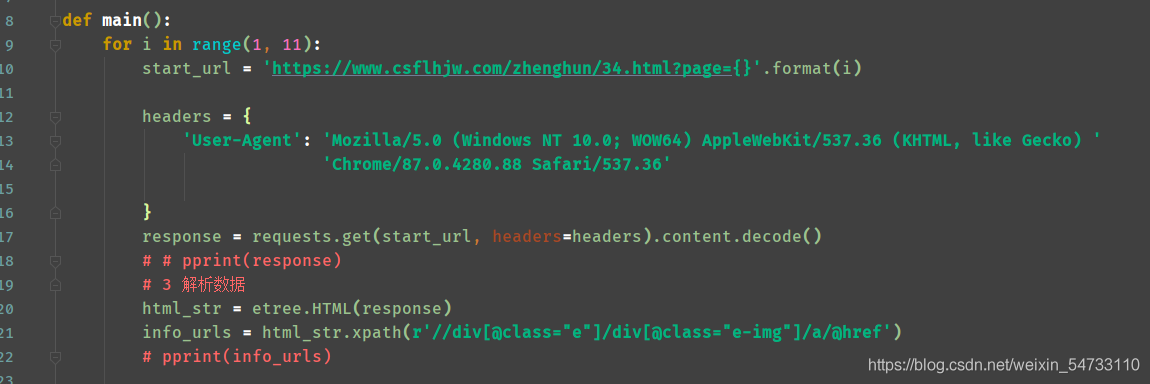
2.构造每一位女士的url地址

3.然后点开一位女士的url地址,用同样的方法,确定也为同步加载
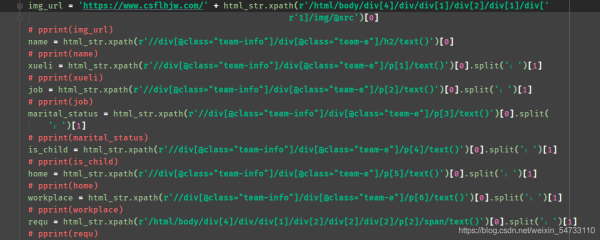
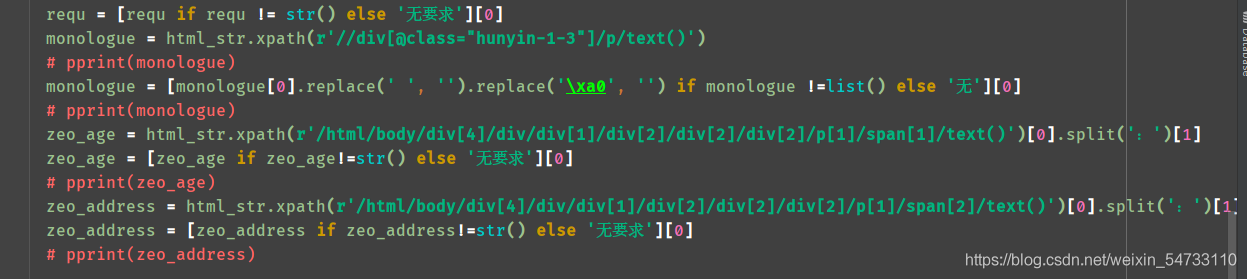
4.之后就是女士url地址html的xpath提取,每个都打印一下,把不要的过滤一下
5.最后就是文件的保存
打印结果:
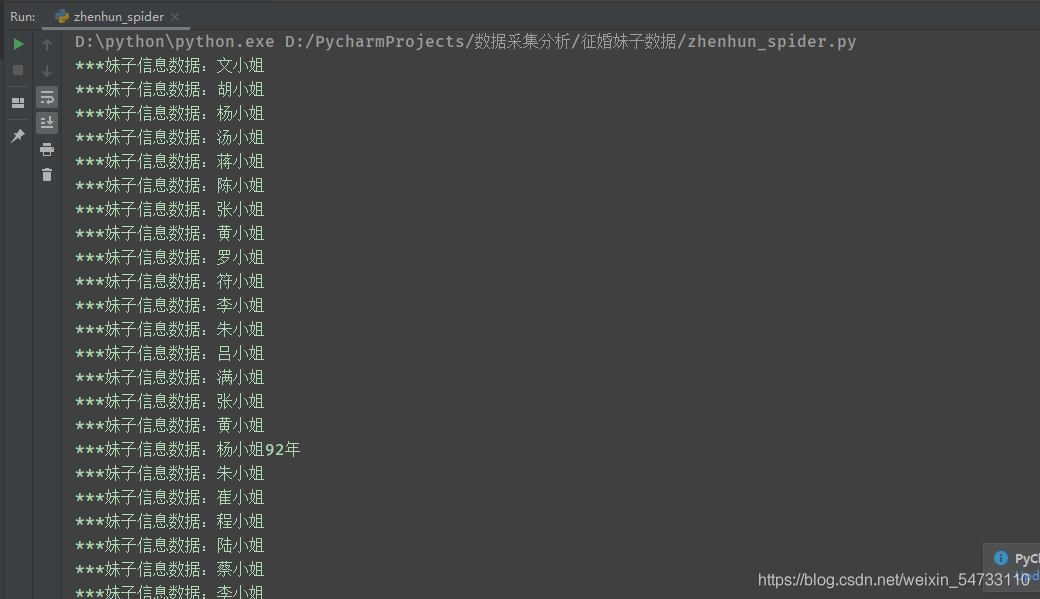
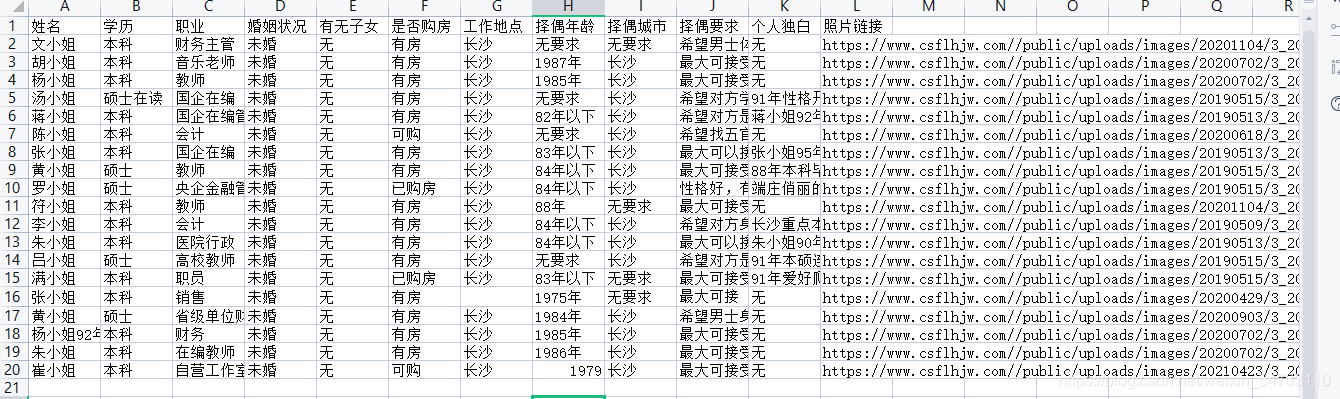
三、完整代码
# !/usr/bin/nev python
# -*-coding:utf8-*-
import requests, os, csv
from pprint import pprint
from lxml import etree
def main():
for i in range(1, 11):
start_url = 'https://www.csflhjw.com/zhenghun/34.html?page={}'.format(i)
headers = {
'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, like Gecko) '
'Chrome/87.0.4280.88 Safari/537.36'
}
response = requests.get(start_url, headers=headers).content.decode()
# # pprint(response)
# 3 解析数据
html_str = etree.HTML(response)
info_urls = html_str.xpath(r'//div[@class="e"]/div[@class="e-img"]/a/@href')
# pprint(info_urls)
# 4、循环遍历 构造img_info_url
for info_url in info_urls:
info_url = r'https://www.csflhjw.com' + info_url
# print(info_url)
# 5、对info_url发请求,解析得到img_urls
response = requests.get(info_url, headers=headers).content.decode()
html_str = etree.HTML(response)
# pprint(html_str)
img_url = 'https://www.csflhjw.com/' + html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[1]/div['
r'1]/img/@src')[0]
# pprint(img_url)
name = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/h2/text()')[0]
# pprint(name)
xueli = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[1]/text()')[0].split(':')[1]
# pprint(xueli)
job = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[2]/text()')[0].split(':')[1]
# pprint(job)
marital_status = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[3]/text()')[0].split(
':')[1]
# pprint(marital_status)
is_child = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[4]/text()')[0].split(':')[1]
# pprint(is_child)
home = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[5]/text()')[0].split(':')[1]
# pprint(home)
workplace = html_str.xpath(r'//div[@class="team-info"]/div[@class="team-e"]/p[6]/text()')[0].split(':')[1]
# pprint(workplace)
requ = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[2]/span/text()')[0].split(':')[1]
# pprint(requ)
requ = [requ if requ != str() else '无要求'][0]
monologue = html_str.xpath(r'//div[@class="hunyin-1-3"]/p/text()')
# pprint(monologue)
monologue = [monologue[0].replace(' ', '').replace('\xa0', '') if monologue !=list() else '无'][0]
# pprint(monologue)
zeo_age = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[1]/text()')[0].split(':')[1]
zeo_age = [zeo_age if zeo_age!=str() else '无要求'][0]
# pprint(zeo_age)
zeo_address = html_str.xpath(r'/html/body/div[4]/div/div[1]/div[2]/div[2]/div[2]/p[1]/span[2]/text()')[0].split(':')[1]
zeo_address = [zeo_address if zeo_address!=str() else '无要求'][0]
# pprint(zeo_address)
if not os.path.exists(r'./{}'.format('妹子信息数据')):
os.mkdir(r'./{}'.format('妹子信息数据'))
csv_header = ['姓名', '学历', '职业', '婚姻状况', '有无子女', '是否购房', '工作地点', '择偶年龄', '择偶城市', '择偶要求', '个人独白', '照片链接']
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'w', newline='', encoding='gbk') as file_csv:
csv_writer_header = csv.DictWriter(file_csv, csv_header)
csv_writer_header.writeheader()
try:
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'a+', newline='',
encoding='gbk') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***妹子信息数据:{}'.format(name))
except Exception as e:
with open(r'./{}/{}.csv'.format('妹子信息数据', '妹子数据'), 'a+', newline='',
encoding='utf-8') as file_csv:
csv_writer = csv.writer(file_csv, delimiter=',')
csv_writer.writerow([name, xueli, job, marital_status, is_child, home, workplace, zeo_age,
zeo_address, requ, monologue, img_url])
print(r'***妹子信息数据保存成功:{}'.format(name))
if __name__ == '__main__':
main()
到此这篇关于单身狗福利?Python爬取某婚恋网征婚数据的文章就介绍到这了,更多相关Python爬取征婚数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫之爬取2020女团选秀数据
一.先看结果 1.1创造营2020撑腰榜前三甲 创造营2020撑腰榜前三名分别是 希林娜依·高.陈卓璇 .郑乃馨 >>>df1[df1['排名']<=3 ][['排名','姓名','身高','体重','生日','出生地']] 排名 姓名 身高 体重 生日 出生地 0 1.0 希林娜依·高 NaN NaN 1998年07月31日 新疆 1 2.0 陈卓璇 168.0 42.0 1997年08月13日 贵州 2 3.0 郑乃馨 NaN NaN 1997年06月25日 泰国 1.2青春有
-
Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路: 在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表. ①此方法用于爬取每日详细疫情数据 import requests import json import time def get_details(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410284820553141302
-
Python数据分析之Python和Selenium爬取BOSS直聘岗位
一.数据爬取的代码 #encoding='utf-8' from selenium import webdriver import time import re import pandas as pd import os def close_windows(): #如果有登录弹窗,就关闭 try: time.sleep(0.5) if dr.find_element_by_class_name("jconfirm").find_element_by_class_name("c
-
python爬虫之教你如何爬取地理数据
一.shapely模块 1.shapely shapely是python中开源的针对空间几何进行处理的模块,支持点.线.面等基本几何对象类型以及相关空间操作. 2.point→Point类 curve→LineString和LinearRing类: surface→Polygon类 集合方法分别对应MultiPoint.MultiLineString.MultiPolygon 3.导入所需模块 # 导入所需模块 from shapely import geometry as geo from s
-
python爬取豆瓣电影TOP250数据
在执行程序前,先在MySQL中创建一个数据库"pachong". import pymysql import requests import re #获取资源并下载 def resp(listURL): #连接数据库 conn = pymysql.connect( host = '127.0.0.1', port = 3306, user = 'root', password = '******', #数据库密码请根据自身实际密码输入 database = 'pachong', cha
-
python利用xpath爬取网上数据并存储到django模型中
帮朋友制作一个网站,需要一些产品数据信息,因为是代理其他公司产品,直接爬取代理公司产品数据 1.设计数据库 from django.db import models from uuslug import slugify import uuid import os def products_directory_path(instance, filename): ext = filename.split('.')[-1] filename = '{}.{}'.format(uuid.uuid4().
-
Python爬虫之爬取某文库文档数据
一.基本开发环境 Python 3.6 Pycharm 二.相关模块的使用 import os import requests import time import re import json from docx import Document from docx.shared import Cm 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.目标网页分析 网站的文档内容,都是以图片形式存在的.它有自己的数据接口 接口链接: https://openapi.book11
-
Python爬虫之自动爬取某车之家各车销售数据
一.目标网页分析 目标网站是某车之家关于品牌汽车车型的口碑模块相关数据,比如我们演示的案例奥迪Q5L的口碑页面如下: https://k.autohome.com.cn/4851/#pvareaid=3311678 为了演示方式,大家可以直接打开上面这个网址,然后拖到全部口碑位置,找到我们本次采集需要的字段如下图所示: 采集字段 我们进行翻页发现,浏览器网址发生了变化,大家可以对下如下几页的网址找出规律: https://k.autohome.com.cn/4851/index_2.html#d
-
python基于scrapy爬取京东笔记本电脑数据并进行简单处理和分析
一.环境准备 python3.8.3 pycharm 项目所需第三方包 pip install scrapy fake-useragent requests selenium virtualenv -i https://pypi.douban.com/simple 1.1 创建虚拟环境 切换到指定目录创建 virtualenv .venv 创建完记得激活虚拟环境 1.2 创建项目 scrapy startproject 项目名称 1.3 使用pycharm打开项目,将创建的虚拟环境配置到项目中来
-
单身狗福利?Python爬取某婚恋网征婚数据
目标网址https://www.csflhjw.com/zhenghun/34.html?page=1 一.打开界面 鼠标右键打开检查,方框里为你一个文小姐的征婚信息..由此判断出为同步加载 点击elements,定位图片地址,方框里为该女士的url地址及图片地址 可以看出该女士的url地址不全,之后在代码中要进行url的拼接,看一下翻页的url地址有什么变化 点击第2页 https://www.csflhjw.com/zhenghun/34.html?page=2 点击第3页 https://
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
python 爬取学信网登录页面的例子
我们以学信网为例爬取个人信息 **如果看不清楚 按照以下步骤:** 1.火狐为例 打开需要登录的网页–> F12 开发者模式 (鼠标右击,点击检查元素)–点击网络 –>需要登录的页面登录下–> 点击网络找到 一个POST提交的链接点击–>找到post(注意该post中信息就是我们提交时需要构造的表单信息) import requests from bs4 import BeautifulSoup from http import cookies import urllib impo
-
使用Python爬取最好大学网大学排名
本文实例为大家分享了Python爬取最好大学网大学排名的具体代码,供大家参考,具体内容如下 源代码: #-*-coding:utf-8-*- ''''' Created on 2017年3月17日 @author: lavi ''' import requests from bs4 import BeautifulSoup import bs4 def getHTMLText(url): try: r = requests.get(url) r.raise_for_status r.encodi
-
Python爬取股票信息,并可视化数据的示例
前言 截止2019年年底我国股票投资者数量为15975.24万户, 如此多的股民热衷于炒股,首先抛开炒股技术不说, 那么多股票数据是不是非常难找, 找到之后是不是看着密密麻麻的数据是不是头都大了? 今天带大家爬取雪球平台的股票数据, 并且实现数据可视化 先看下效果图 基本环境配置 python 3.6 pycharm requests csv time 目标地址 https://xueqiu.com/hq 爬虫代码 请求网页 import requests url = 'https://xueq
-
python爬取”顶点小说网“《纯阳剑尊》的示例代码
爬取"顶点小说网"<纯阳剑尊> 代码 import requests from bs4 import BeautifulSoup # 反爬 headers = { 'User-Agent': 'Mozilla/5.0 (Windows NT 10.0; WOW64) AppleWebKit/537.36 (KHTML, \ like Gecko) Chrome/70.0.3538.102 Safari/537.36' } # 获得请求 def open_url(url):
-
python爬取链家二手房的数据
一.查找数据所在位置: 打开链家官网,进入二手房页面,选取某个城市,可以看到该城市房源总数以及房源列表数据. 二.确定数据存放位置: 某些网站的数据是存放在html中,而有些却api接口,甚至有些加密在js中,还好链家的房源数据是存放到html中: 三.获取html数据: 通过requests请求页面,获取每页的html数据 # 爬取的url,默认爬取的南京的链家房产信息 url = 'https://nj.lianjia.com/ershoufang/pg{}/'.format(page) #
-
实操Python爬取觅知网素材图片示例
目录 [一.项目背景] [二.项目目标] [三.涉及的库和网站] [四.项目分析] [五.项目实施] [六.效果展示] [七.总结] [一.项目背景] 在素材网想找到合适图片需要一页一页往下翻,现在学会python就可以用程序把所有图片保存下来,慢慢挑选合适的图片. [二.项目目标] 1.根据给定的网址获取网页源代码. 2.利用正则表达式把源代码中的图片地址过滤出来. 3.过滤出来的图片地址下载素材图片. [三.涉及的库和网站] 1.网址如下: https://www.51miz.com/
-
用Python爬取某乎手机APP数据
目录 一.配置抓包工具 二.配置手机代理 三.抓取数据 四.总结 一.配置抓包工具 1.安装软件 本文选择的抓包工具:Fiddler 具体的下载安装这里不详细赘述!(网上搜Fiddler安装,一大堆教程),本文以实战为例,就不再这里浪费时间了! 2.配置Fiddler 安装好之后,接下来就开始配置Fiddler工具(这里是关键,仔细阅读!) 配置Connections 打开Fiddler后,点击Tools->Options 点击Connections 勾选上对应的选项 配置HTTPS 由于目