浅谈算法之最小生成树Kruskal的Python实现
目录
- 一、前言
- 二、树是什么
- 三、从图到树
- 四、解决生成问题
- 五、从生成树到最小生成树
- 六、实际问题与代码实现
- 七、结尾
一、前言
我们先不讲算法的原理,也不讲一些七七八八的概念,因为对于初学者来说,看到这些术语和概念往往会很头疼。头疼也是正常的,因为无端突然出现这么多信息,都不知道它们是怎么来的,也不知道这些信息有什么用,自然就会觉得头疼。这也是很多人学习算法热情很高,但是最后又被劝退的原因。
我们先不讲什么叫生成树,怎么生成树,有向图、无向图这些,先简单点,从最基本的内容开始,完整地将这个算法梳理一遍。
二、树是什么
首先,我们先来看看最简单的数据结构——树。
树是一个很抽象的数据结构,因为它在自然界当中能找到对应的物体。我们在初学的时候,往往都会根据自然界中真实的树来理解这个概念。所以在我们的认知当中,往往树是长这样的:

上面这张图就是自然界中树的抽象,我们很容易理解。但是一般情况下,我们看到的树结构往往不是这样的,而是倒过来的。也就是树根在上,树叶在下。这样设计的原因很简单,没什么特别的道理,只是因为我们在遍历树的时候,往往从树根开始,从树根往叶子节点出发。所以我们倒过来很容易理解一些,我们把上面的树倒过来就成了这样:
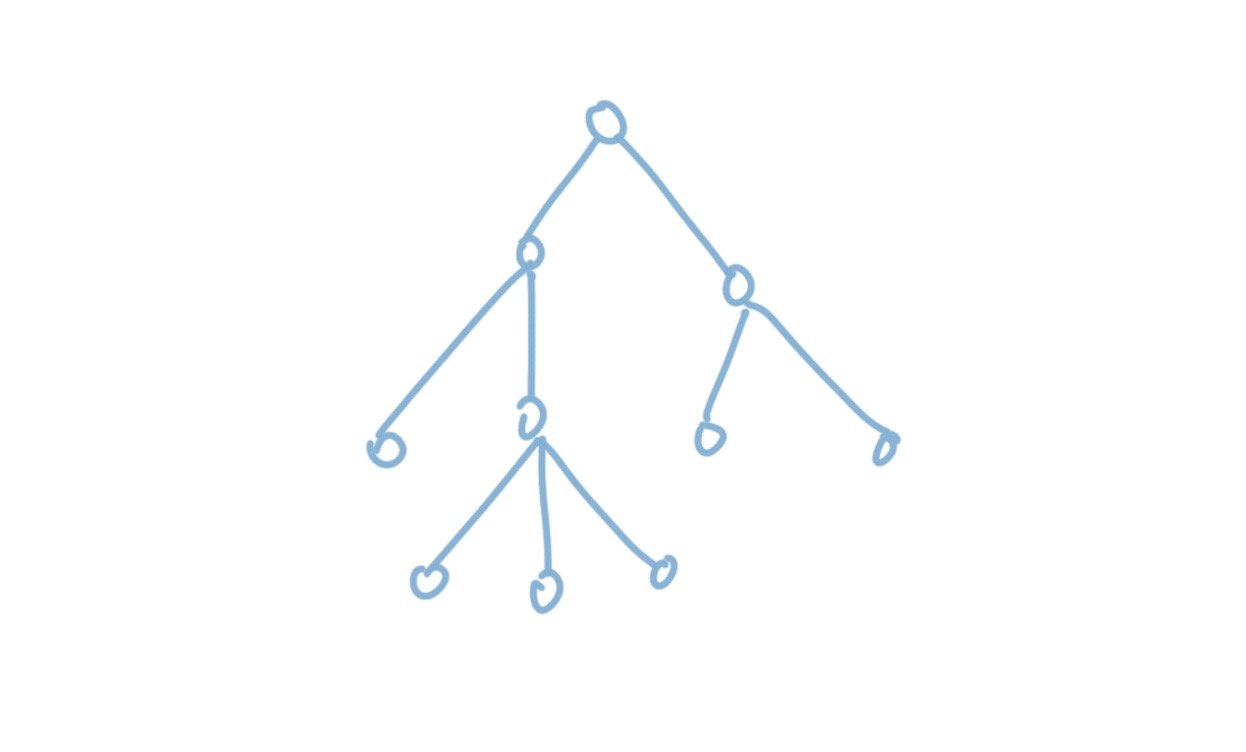
上面的两种画法当然都是正确的,但既然树可以正着放,也可以倒过来放,我们自然也可以将它伸展开来放。比如下面这张图,其实也是一棵树,只是我们把它画得不一样而已。
我们可以想象一下,假如有一只无形的大手抓住了树根将它“拎起来”,那么它自然而然就变成了上面的样子。
然后你会发现,如果真的有这样大手,它不管拎起哪个节点,都会得到一棵树。也就是说,如果树根的位置对我们不再重要的话,树其实就等价于上面这样的图。
那么这样的图究竟是什么图呢?它有什么性质呢?所有的图都能看成是树吗?
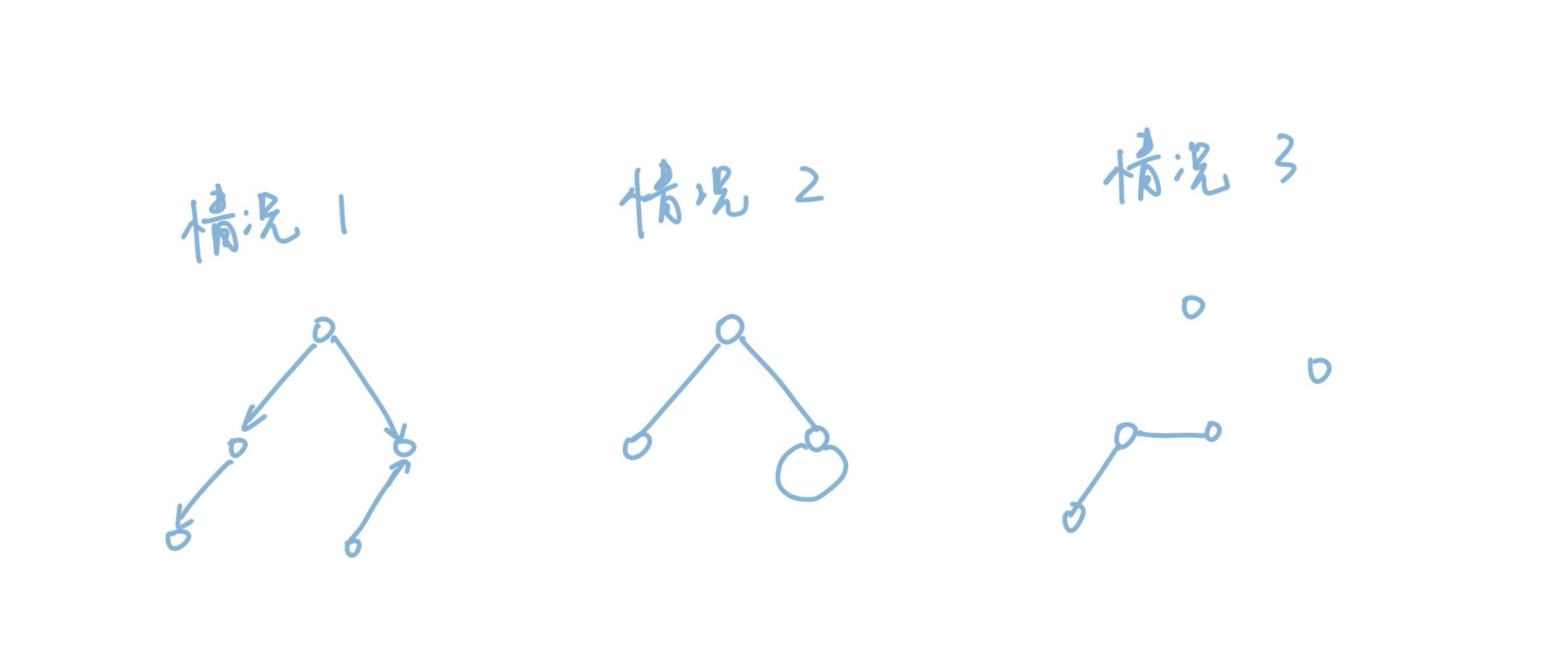
显然这三种情况都不是树,第一种是因为图中的边有方向了。有了方向之后,图中连通的情况就被破坏了。在我们认知当中树应该是全连通的,就好像自然界中的一只蚂蚁,可以走到树上任何位置。不能全连通,自然就不是树。情况2也不对,因为有了环,树是不应该有环的。自然界中的树是没有环的,不存在某根树枝自己绕一圈,同样,我们逻辑中的树也是没有环的,否则我们递归访问永远也找不到终点。第三种情况也一样,有些点孤立在外,不能连通,自然也不是树。
那我们总结一下,就可以回答这个问题。树是什么?树就是可以全连通(无向图),并且没有环路的图。
三、从图到树
从刚才的分析当中,我们得到了一个很重要的结论,树的本质就是图,只不过是满足了一些特殊性质的图。这也是为什么树的很多算法都会被收纳进图论这个大概念当中。
从全连通和没有环路这两个性质出发,我们又可以得到一个很重要的结论,对于一棵拥有n个节点的树而言,它的边数是固定的,一定是n-1条边。如果超过n-1条边,那么当中一定存在环路,如果小于n-1条边,那么一定存在不连通的部分。但注意,它只是一个必要条件,不是一个充分条件。也就是说并不是n个点n-1条边就一定是树,这很容易构造出反例。
这个结论虽然很简单,但是很有用处,它可以解决一个由图转化成树的问题。
也就是说当下我们拥有一个复杂图,我们想要根据这个图生成能够连通所有节点的树,这个时候应该怎么办?如果我们没有上面的性质,会有一点无从下手的感觉。但有了这个性质之后,就明确多了。我们一共有两种办法,第一种办法是删减边,既然是一个复杂图,说明边的数量一定超过n-1。那么我们可以试着删去一些边,最后留下一棵树。第二种做法与之相反,是增加边。也就是说我们一开始把所有的边全部撤掉,然后一条一条地往当中添加n-1条边,让它变成一棵树。
我们试着想一下,会发现删减边的做法明显弱于添加边的方法。原因很简单,因为我们每一次在删除边的时候都面临是否会破坏树上连通关系的拷问。比如下图:
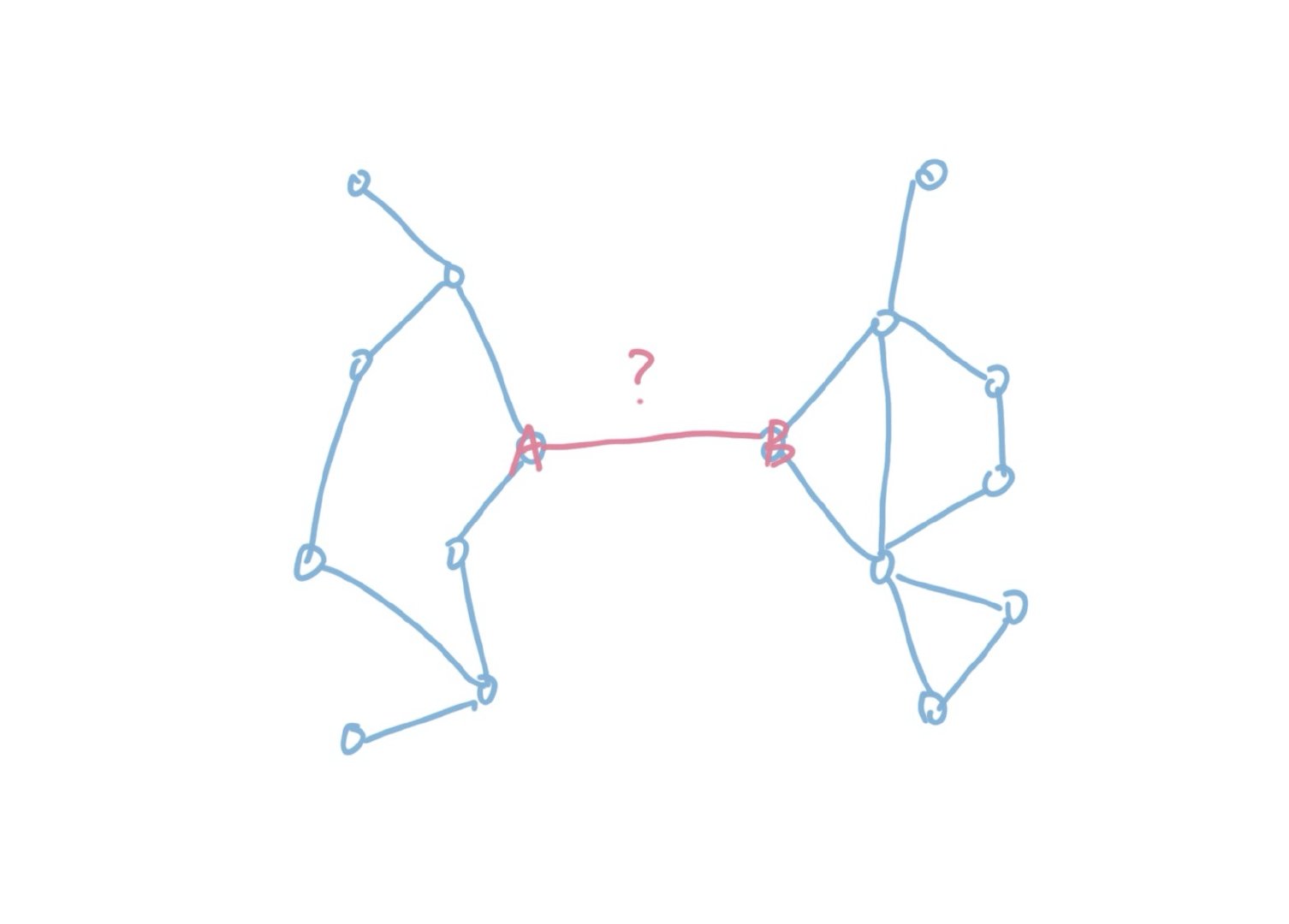
如果我们一旦删去了AB这条边,那么一定会破坏整个结构的连通性。我们要判断连通关系,最好的办法就是我们先删除这条边,然后试着从A点出发,看看能否到达B点。如果可以,那么则认为这条边可以删除。如果图很大的话,每一次删除都需要遍历整张图,这会带来巨大的开销。并且每一次删除都会改变图的结构,很难缓存这些结果。
因此,删除边的方式并不是不可行,只是复杂度非常高,正因此,目前比较流行的两种最小生成树的算法都是利用的第二种,也就是添加边的方式实现的。
到这里,我们就知道了,所谓的最小生成树算法,就是从图当中挑选出n-1条边将它转化成一棵树的算法。
四、解决生成问题
我们先不考虑边上带权重的情况,我们假设所有边都是等价的,先来看看生成问题怎么解决,再来进行优化求最小。
如果采用添加边的方法,面临的问题和上面类似,当我们选择一条边的时候,我们如何判断这条边是有必要添加的呢?这个问题需要用到树的另外一个性质。
由于没有环路,树上任意两点之间的路径,有且只有一条。因为如果存在两点之间的路径有两条,那么必然可以找到一个环路。它的证明很简单,但是我们很难凭自己想到这个结论。有了这个结论,就可以回答上面的那个问题,什么样的边是有必要添加的?也就是两个点之间不存在通路的时候。如果两个点之间已经存在通路,那么当前这条边就不能添加了,否则必然会出现环。如果没有通路,那么可以添加。
所以我们要做的就是设计一个算法,可以维护树上点的连通性。
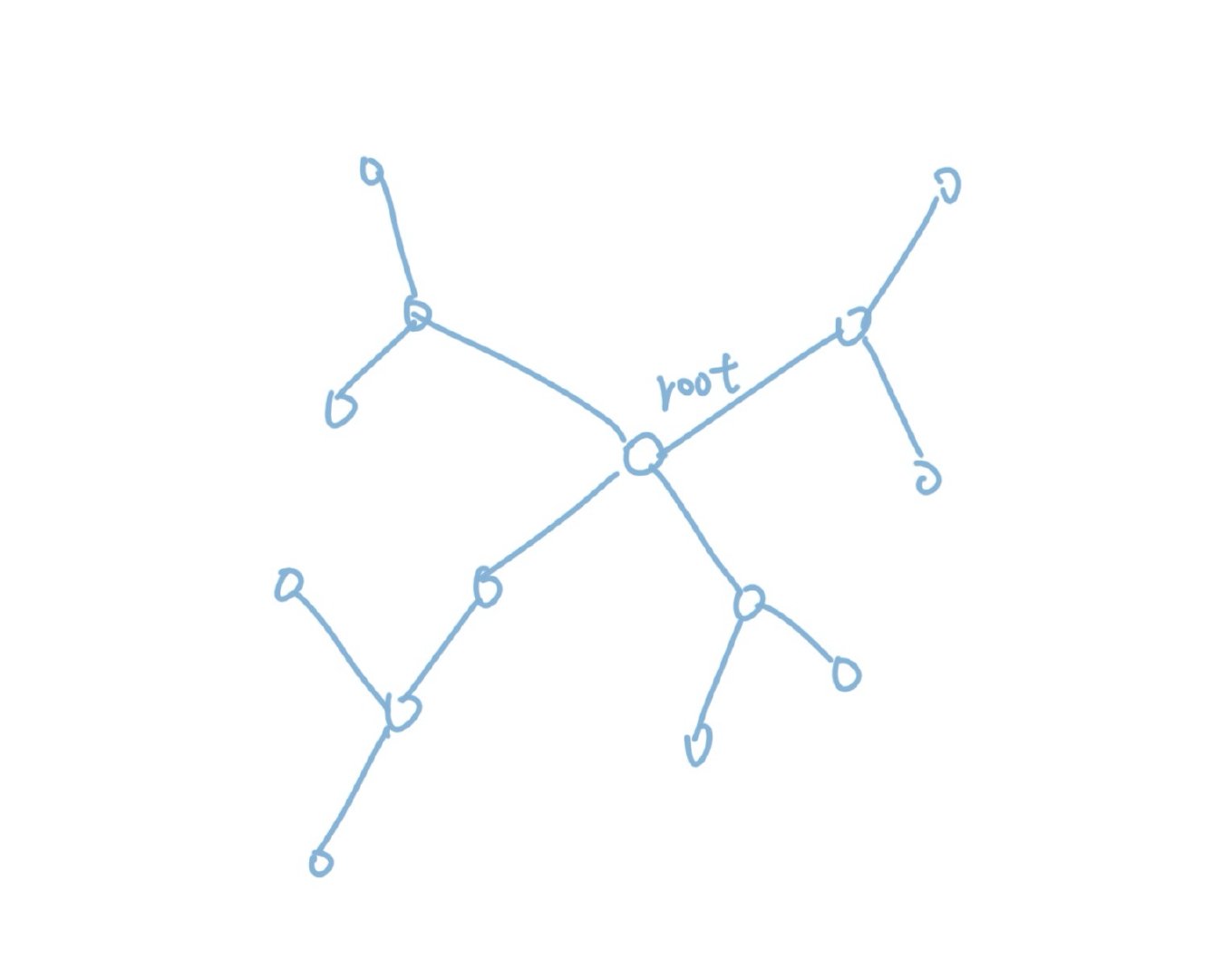
但是这又带来了一个新的问题,在树结构当中,连通性是可以传递的。两个点之间连了一条边,并不仅仅是这两个点连通,而是所有与这两个点之间连通的点都连通了。比如下图:
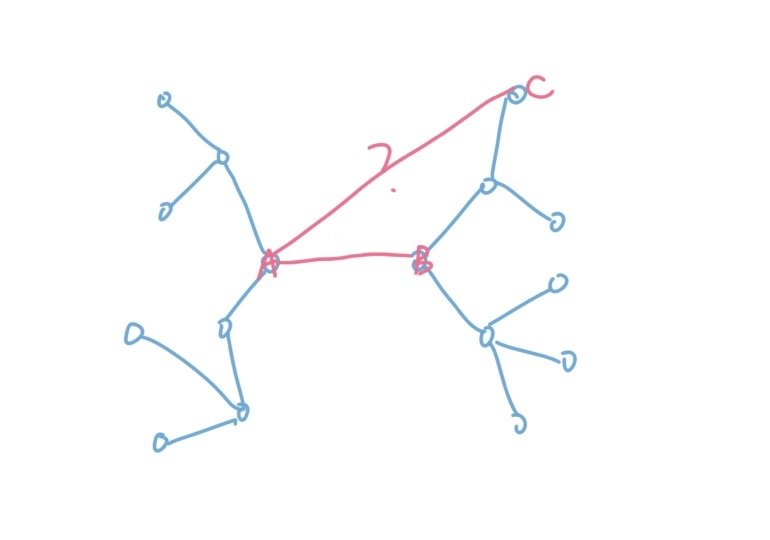
这张图当中A和B连了一条边,这不仅仅是A和B连通,而是左半边的集合和右半边集合的连通。所以,虽然A只是和B连通了,但是和C也连通了。AC这条边也一样不能被加入了。也就是说A和B连通,其实是A所在的集合和B所在的集合合并的过程。看到集合的合并,有没有一点熟悉的感觉?对嘛,上一篇文章当中我们讲的并查集算法就是用来解决集合合并和查询问题的。那么,显然可以用并查集来维护图中这些点集的连通性。
利用并查集算法,问题就很简单了。一开始所有点之间都不连通,那么所有点单独是一个集合。如果当前边连通的两个点所属于同一个集合,那么说明它们之间已经有通路了,这条边不能被添加。否则的话,说明它们不连通,那么将这条边连上,并且合并这两个集合。
于是,我们就解决了生成树这个问题。
五、从生成树到最小生成树
接下来,我们为图中的每条边加上权重,希望最后得到的树的所有权重之和最小。
比如,我们有下面这张图,我们希望生成的树上所有边的权重和最小。
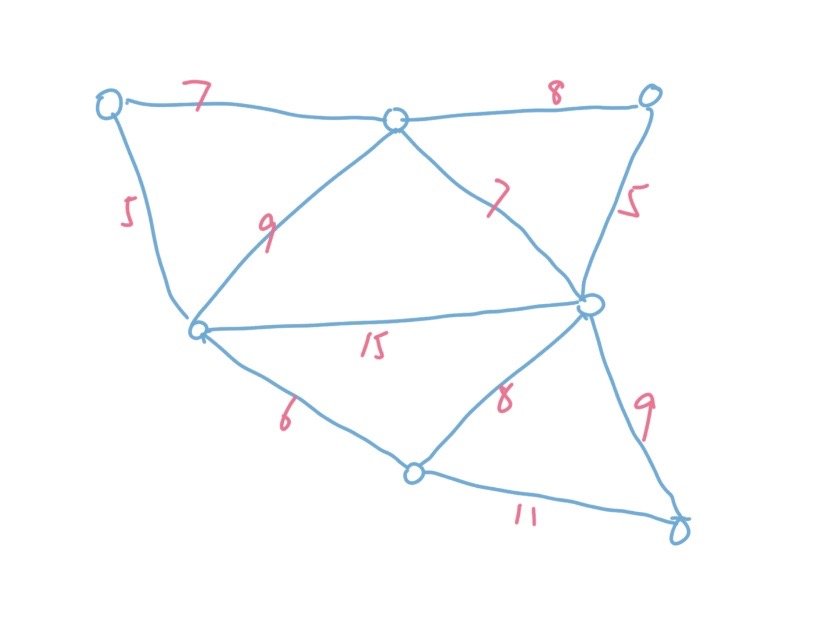
观察一下这张图上的边,长短不一。根据贪心算法,我们显然希望用尽量短的边来连通树。所以Kruskal算法的原理非常简单粗暴,就是对这些边进行长短排序,依次从短到长遍历这些边,然后通过并查集来维护边是否能够被添加,直到所有边都遍历结束。
可以肯定,这样生成出来的树一定是正确的,虽然我们对边进行了排序,但是每条边依然都有可能会被用上,排序并不会影响算法的可行性。但问题是,这样贪心出来的结果一定是最优的吗?
这里,我们还是使用之前讲过的等价判断方法。我们假设存在两条长度一样的边,那么我们的决策是否会影响最后的结果呢?
两个完全相等的边一共只有可能出现三种情况,为了简化图示,我们把一个集合看成是一个点。第一种情况是这两条边连通四个不同的集合:
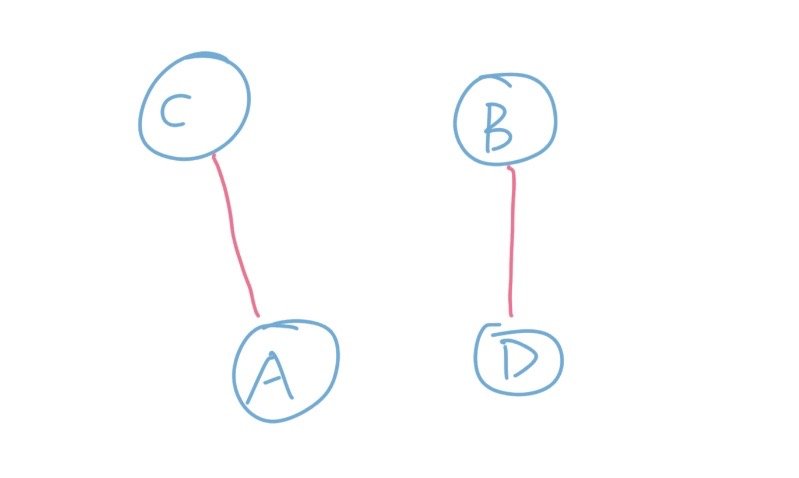
那么显然这两条边之间并不会引起冲突,所以我们可以都保留。所以这不会引起反例。
第二种情况是这两条边连通三个不同的集合:

这种情况和上面一样,我们可以都要,并不会影响连通情况。所以也不会引起反例。
最后一种是这两条边连通的是两个集合,也就是下面这样。
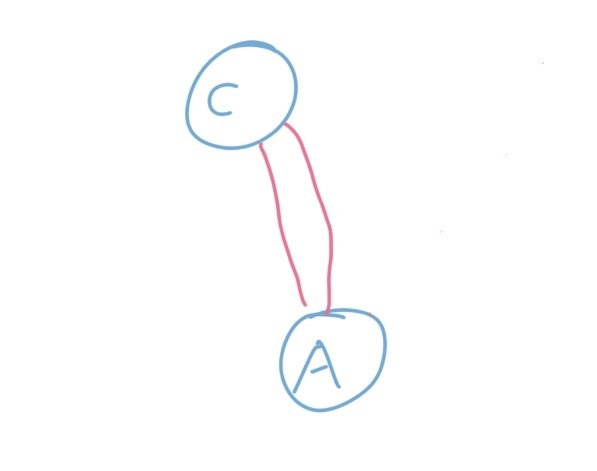
在这种情况下,这两条件之间互相冲突,我们只能选择其中的一条。但是显然,不论我们怎么选都是一样的。因为都是连接了这两个连通块,然后带来的价值也是一样的,并不会影响最终的结果。
当我们把所有情况列举出来之后,我们就可以明确,在这个问题当中贪心法是可行的,并不会引起反例,所以我们可以放心大胆地用。
六、实际问题与代码实现
明白了算法原理之后,我们来看看这个算法的实际问题。其实这个算法在现实当中的使用蛮多的,比如自来水公司要用水管连通所有的小区。而水管是有成本的,那么显然自来水公司希望水管的总长度尽量短。比如山里的村庄通电,要用尽量少的电缆将所有村庄连通,这些类似的问题其实都可以抽象成最小生成树来解决。当然现实中的问题可能没有这么简单,除了考虑成本和连通之外,还需要考虑地形、人文、社会等其他很多因素。
最后,我们试着用代码来实现一下这个算法。
class DisjointSet:
def __init__(self, element_num=None):
self._father = {}
self._rank = {}
# 初始化时每个元素单独成为一个集合
if element_num is not None:
for i in range(element_num):
self.add(i)
def add(self, x):
# 添加新集合
# 如果已经存在则跳过
if x in self._father:
return
self._father[x] = x
self._rank[x] = 0
def _query(self, x):
# 如果father[x] == x,说明x是树根
if self._father[x] == x:
return x
self._father[x] = self._query(self._father[x])
return self._father[x]
def merge(self, x, y):
if x not in self._father:
self.add(x)
if y not in self._father:
self.add(y)
# 查找到两个元素的树根
x = self._query(x)
y = self._query(y)
# 如果相等,说明属于同一个集合
if x == y:
return
# 否则将树深小的合并到树根大的上
if self._rank[x] < self._rank[y]:
self._father[x] = y
else:
self._father[y] = x
# 如果树深相等,合并之后树深+1
if self._rank[x] == self._rank[y]:
self._rank[x] += 1
# 判断是否属于同一个集合
def same(self, x, y):
return self._query(x) == self._query(y)
# 构造数据
edges = [[1, 2, 7], [2, 3, 8], [2, 4, 9], [1, 4, 5], [3, 5, 5], [2, 5, 7], [4, 5, 15], [4, 6, 6], [5, 6, 8], [6, 7, 11], [5, 7, 9]]
if __name__ == "__main__":
disjoinset = DisjointSet(8)
# 根据边长对边集排序
edges = sorted(edges, key=lambda x: x[2])
res = 0
for u, v, w in edges:
if disjoinset.same(u ,v):
continue
disjoinset.merge(u, v)
res += w
print(res)
其实主要都是利用并查集,我们额外写的代码就只有几行而已,是不是非常简单呢?
七、结尾
相信大家也都感觉到了Kruskal算法的原理非常简单,如果你是顺着文章脉络这样读下来,相信一定会有一种顺水推舟,一切都自然而然的感觉。也正是因此,它非常符合直觉,也非常容易理解,一旦记住了就不容易忘记,即使忘记了我们也很容易自己推导出来。这并不是笑话,有一次我在比赛的时候临时遇到了,当时许久不写Kruskal算法,一时想不起来。凭着仅有的一点印象,硬是在草稿纸上推导了一遍算法。
以上就是浅谈算法之最小生成树Kruskal的Python实现的详细内容,更多关于Python 最小生成树Kruskal 的资料请关注我们其它相关文章!
相关推荐
-
C语言实现最小生成树构造算法
最小生成树 最小生成树(minimum spanning tree)是由n个顶点,n-1条边,将一个连通图连接起来,且使权值最小的结构. 最小生成树可以用Prim(普里姆)算法或kruskal(克鲁斯卡尔)算法求出. 我们将以下面的带权连通图为例讲解这两种算法的实现: 注:由于测试输入数据较多,程序可以采用文件输入 Prim(普里姆)算法 时间复杂度:O(N^2)(N为顶点数) prim算法又称"加点法",用于边数较多的带权无向连通图 方法:每次找与之连线权值最小的顶点,将该点加入最小
-

Prim(普里姆)算法求最小生成树的思想及C语言实例讲解
Prim 算法思想: 从任意一顶点 v0 开始选择其最近顶点 v1 构成树 T1,再连接与 T1 最近顶点 v2 构成树 T2, 如此重复直到所有顶点均在所构成树中为止. 最小生成树(MST):权值最小的生成树. 生成树和最小生成树的应用:要连通n个城市需要n-1条边线路.可以把边上的权值解释为线路的造价.则最小生成树表示使其造价最小的生成树. 构造网的最小生成树必须解决下面两个问题: 1.尽可能选取权值小的边,但不能构成回路: 2.选取n-1条恰当的边以连通n个顶点: MST性质:假设G=(V
-
python最小生成树kruskal与prim算法详解
kruskal算法基本思路:先对边按权重从小到大排序,先选取权重最小的一条边,如果该边的两个节点均为不同的分量,则加入到最小生成树,否则计算下一条边,直到遍历完所有的边. prim算法基本思路:所有节点分成两个group,一个为已经选取的selected_node(为list类型),一个为candidate_node,首先任取一个节点加入到selected_node,然后遍历头节点在selected_node,尾节点在candidate_node的边,选取符合这个条件的边里面权重最小的边,加入到
-
C++使用Kruskal和Prim算法实现最小生成树
很久以前就学过最小生成树之Kruskal和Prim算法,这两个算法很容易理解,但实现起来并不那么容易.最近学习了并查集算法,得知并查集可以用于实现上述两个算法后,我自己动手实现了最小生成树算法. 宏观上讲,Kruskal算法就是一个合并的过程,而Prim算法是一个吞并的过程,另外在Prim算法中还用到了一种数据结构--优先级队列,用于动态排序.由于这两个算法很容易理解,在此不再赘述.接下来给出我的源代码. 输入 第一行包含两个整数n和m,n表示图中结点个数,m表示图中边的条数:接下来m行,每一行
-
详解图的应用(最小生成树、拓扑排序、关键路径、最短路径)
1.最小生成树:无向连通图的所有生成树中有一棵边的权值总和最小的生成树 1.1 问题背景: 假设要在n个城市之间建立通信联络网,则连通n个城市只需要n-1条线路.这时,自然会考虑这样一个问题,如何在最节省经费的前提下建立这个通信网.在每两个城市之间都可以设置一条线路,相应地都要付出一定的经济代价.n个城市之间,最多可能设置n(n-1)/2条线路,那么,如何在这些可能的线路中选择n-1条,以使总的耗费最少呢? 1.2 分析问题(建立模型): 可以用连通网来表示n个城市以及n个城市间可能设置的通信线
-
JS使用Prim算法和Kruskal算法实现最小生成树
之前都是看书,大部分也是c++的实现,但是搞前端不能忘了JS啊,所以JS实现一遍这两个经典的最小生成树算法. 一.权重图和最小生成树 权重图:图的边带权重 最小生成树:在连通图的所有生成树中,所有边的权重和最小的生成树 本文使用的图如下: 它的最小生成树如下: 二.邻接矩阵 邻接矩阵:用来表示图的矩阵就是邻接矩阵,其中下标表示顶点,矩阵中的值表示边的权重(或者有无边,方向等). 本文在构建邻接矩阵时,默认Number.MAX_SAFE_INTEGER表示两个节点之间没有边,Number.MIN_
-
最小生成树算法之Prim算法
本文介绍了最小生成树的定义,Prim算法的实现步骤,通过简单举例实现了C语言编程. 1.什么是最小生成树算法? 简言之,就是给定一个具有n个顶点的加权的无相连通图,用n-1条边连接这n个顶点,并且使得连接之后的所有边的权值之和最小.这就叫最小生成树算法,最典型的两种算法就是Kruskal算法和本文要讲的Prim算法. 2.Prim算法的步骤是什么? 这就要涉及一些图论的知识了. a.假定图的顶点集合为V,边集合为E. b.初始化点集合U={u}.//u为V中的任意选定的一点 c.从u的邻接结点中
-
最小生成树算法C语言代码实例
在贪婪算法这一章提到了最小生成树的一些算法,首先是Kruskal算法,实现如下: MST.h 复制代码 代码如下: #ifndef H_MST#define H_MST #define NODE node *#define G graph *#define MST edge ** /* the undirect graph start */typedef struct _node { char data; int flag; struct _node *parent;} node; typede
-
使用C语言实现最小生成树求解的简单方法
最小生成树Prim算法朴素版 有几点需要说明一下. 1.2个for循环都是从2开始的,因为一般我们默认开始就把第一个节点加入生成树,因此之后不需要再次寻找它. 2.lowcost[i]记录的是以节点i为终点的最小边权值.初始化时因为默认把第一个节点加入生成树,因此lowcost[i] = graph[1][i],即最小边权值就是各节点到1号节点的边权值. 3.mst[i]记录的是lowcost[i]对应的起点,这样有起点,有终点,即可唯一确定一条边了.初始化时mst[i] = 1,即每条边都是从
-
浅谈算法之最小生成树Kruskal的Python实现
目录 一.前言 二.树是什么 三.从图到树 四.解决生成问题 五.从生成树到最小生成树 六.实际问题与代码实现 七.结尾 一.前言 我们先不讲算法的原理,也不讲一些七七八八的概念,因为对于初学者来说,看到这些术语和概念往往会很头疼.头疼也是正常的,因为无端突然出现这么多信息,都不知道它们是怎么来的,也不知道这些信息有什么用,自然就会觉得头疼.这也是很多人学习算法热情很高,但是最后又被劝退的原因. 我们先不讲什么叫生成树,怎么生成树,有向图.无向图这些,先简单点,从最基本的内容开始,完整地将这个算
-
浅谈PyQt5中异步刷新UI和Python多线程总结
目前任务需要做一个界面程序,PyQt是非常方便的选择,QT丰富的控件以及python方便的编程.近期遇到界面中执行一些后台任务时界面卡死的情况,解决了在这里记录下. PyQt PyQt简介 PyQt是Qt的python接口,PyQt的文档较少,但接口和函数可以完全参照Qt,继承了Qt中大量的控件以及信号机制,十分方便.以下简介一个基本的PyQt程序. - 需要导入的类主要来自三个包 - from PyQt5.QtWidgets import 常用的控件 - PyQt5.QtCore 核心功能类,
-
浅谈python中copy和deepcopy中的区别
在下是个编程爱好者,最近将魔爪伸向了Python编程.....遇到copy和deepcopy感到很困惑,现在针对这两个方法进行区分,一种是浅复制(copy),一种是深度复制(deepcopy). 首先说一下deepcopy,所谓的深度复制,在这里我理解的是完全复制然后变成一个新的对象,复制的对象和被复制的对象没有任何关系,彼此之间无论怎么改变都相互不影响. 然后说一下copy,在这里我分为两类来说,一种是字典数据类型的copy函数,一种是copy包的copy函数. 一.字典数据类型的copy函数
-
浅谈python中的数字类型与处理工具
python中的数字类型工具 python中为更高级的工作提供很多高级数字编程支持和对象,其中数字类型的完整工具包括: 1.整数与浮点型, 2.复数, 3.固定精度十进制数, 4.有理分数, 5.集合, 6.布尔类型 7.无穷的整数精度 8.各种数字内置函数及模块. 基本数字类型 python中提供了两种基本类型:整数(正整数金额负整数)和浮点数(注:带有小数部分的数字),其中python中我们可以使用多种进制的整数.并且整数可以用有无穷精度. 整数的表现形式以十进制数字字符串写法出现,浮点数带
-
浅谈python迭代器
1.yield,将函数变为 generator (生成器) 例如:斐波那契数列 def fib(num): a, b, c = 1, 0, 1 while a <= num: yield c b, c = c, b + c a += 1 for n in fib(10): print(n, end=' ') # 1 1 2 3 5 8 13 21 34 55 2.Iterable 所有可以使用for循环的对象,统称为 Iterable (可迭代) from collections import
-
浅谈机器学习需要的了解的十大算法
毫无疑问,近些年机器学习和人工智能领域受到了越来越多的关注.随着大数据成为当下工业界最火爆的技术趋势,机器学习也借助大数据在预测和推荐方面取得了惊人的成绩.比较有名的机器学习案例包括Netflix根据用户历史浏览行为给用户推荐电影,亚马逊基于用户的历史购买行为来推荐图书. 那么,如果你想要学习机器学习的算法,该如何入门呢?就我而言,我的入门课程是在哥本哈根留学时选修的人工智能课程.老师是丹麦科技大学应用数学和计算机专业的全职教授,他的研究方向是逻辑学和人工智能,主要是用逻辑学的方法来建模.课程包
-
浅谈Python对内存的使用(深浅拷贝)
本文主要研究的是Python对内存的使用(深浅拷贝)的相关问题,具体介绍如下. 浅拷贝就是对引用的拷贝(只拷贝父对象) 深拷贝就是对对象的资源的拷贝 >>> a=[1,2,3,'a','b'] >>> b=a >>> b [1, 2, 3, 'a', 'b'] >>> a [1, 2, 3, 'a', 'b'] >>> id(a) 3021737547592 >>> id(b) 3021737547
-
浅谈Python中的私有变量
私有变量表示方法 在变量前加上两个下划线的是私有变量. class Teacher(): def __init__(self,name,level): self.__name=name self.__level=level #获取老师的等级 def get_level(self): return self.__level #获取名字 def get_in_name(self): return self.__name 动态方法无法读取私有变量 即使是动态方法也无法读取私有变量,强行读取会报错. #
-
浅谈Python在pycharm中的调试(debug)
作为一名程序员,调试(debug)程序是一项必会的事情,在利用pycharm这个pythonIDE时,不好好利用其调试功能真的是太可惜了. 借用这两天学习机器学习的工程. 在Deep_Learing工程中创建两个python文件,其中执行程序的文件名称为main.py,另一个KNN.py则是机器学习中一个小的模块,其中有算法代码. 在main.py中这样编写: 最关键的是写出 if __name__ == "__main__": 这句代码,这句代码代表主函数运行的入口,在其中写要进行测