详解C++实现链表的排序算法
一、链表排序
最简单、直接的方式(直接采用冒泡或者选择排序,而且不是交换结点,只交换数据域)
//线性表的排序,采用冒泡排序,直接遍历链表
void Listsort(Node* & head) {
int i = 0;
int j = 0;
//用于变量链表
Node * L = head;
//作为一个临时量
Node * p;
Node * p1;
//如果链表为空直接返回
if (head->value == 0)return;
for (i = 0; i < head->value - 1; i++) {
L = head->next;
for (j = 0; j < head->value - i - 1; j++) {
//得到两个值
p = L;
p1 = L->next;
//如果前面的那个比后面的那个大,就交换它们之间的是数据域
if (p->value > p1->value) {
Elemtype temp = p->value;
p->value = p1->value;
p1->value = temp;
}
L = L->next;
}
}
}
因为排序中速度比较快的如快速排序是要求它们的数据域的地址是相连接的,它比较适合于顺序结构,而链式结构的时候,我们就只有使用只会进行前后两个比较多排序算法,比如冒泡排序等。我们这里是没有交换结点的一种排序方式,这种方式简单,明了,这样就是数组排序的时候是一样的。后面我会写通过交换结点的方式的排序。
下面我们就讨论讨论这个排序算法的时间复杂度了,因为它是使用冒泡排序的,它的时间只要消耗在那两重循环,所以时间复杂度为:O(n*n),这个效率实在是太低,下面我们对这个想(ˇˍˇ) 想~通过另外一种方式来实现链表的排序
二、另外一种链表排序方式
我们在讨论排序算法的时候,都是把数据存放在数组中进行讨论的,在顺序结构下,我们可以采取很多高效的排序算法,那么这个就是我们另外一种对链表排序的方式,先把链表的内容存放到数组中(时间为O(n)),然后,我们在对那个数组进行排序(最快为nlog(n)),最后,存放链表中(时间为O(n))。通过计算,我们可以得到它的时间复杂为(O(nlogn)),这个速度已经和顺序结构下差不多了,可以接受
void Listsort_1(Node* & head) {
int i = 0;
int j = 0;
//用于变量链表
Node * L = head;
//如果链表为空直接返回
if (head->value == 0)return;
Elemtype * copy = new Elemtype[head->value];
//变量链表,存放数组
for (i = 0; i < head->value; i++) {
L = L->next;
copy[i] = L->value;
}
//调用STL中的sort函数
sort(copy, copy + head->value);
L = head;
//存放回链表中
for (i = 0; i < head->value; i++) {
L = L->next;
L->value= copy[i];
}
}
三、比较两种排序的效率
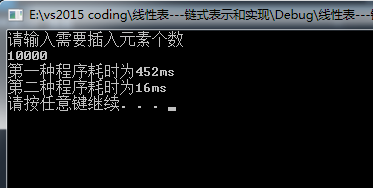
如图所示,在数据量为10000的时候,明显第二种排序算法消耗的时间比第一种快了28倍左右。
四、下面通过交换结点实现链表的排序
首先我们编写交换结点的函数,结点的交换主要就是考虑结点的指针域的问题,其中相邻两个结点是一种特殊的情况,要拿出来特别考虑。我们先画出结点交换的思路图,如下图
首先我们给出相邻两个结点交换的思路:
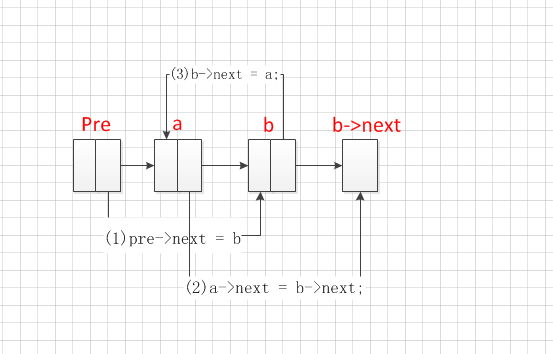
下面是普通情况下的交换如下图

//参数为头结点和需要交换的两个结点的位置(起点为1)
void swap_node(Node * & head,int i,int j) {
//位置不合法
if (i<1 || j<1 || i>head->value || j >head->value) {
cout << "请检查位置是否合法" << endl;
return;
}
//同一个位置不用交换
if (i == j)
{
return;
}
//相邻两个交换比较简单
if (abs(i - j) == 1) {
//位置靠前的那个结点的前一个结点
Node * pre;
if (i < j)
pre = getitem(head, i);
else
pre = getitem(head, j);
//保存第一个结点
Node * a = pre->next;
//保存第二结点
Node * b = a->next;
//改变pre下一个结点的值
pre->next = b;
//必须先把b的下一个结点值给a先
a->next = b->next;
//让b的下一个结点等于a
b->next = a;
return;
}
//第一个结点前一个结点
Node * a = getitem(head, i);
//第二个结点的前一个结点
Node * b = getitem(head, j);
//第一个结点
Node * p = a->next;
//第二个结点
Node * q = b->next;
//第一个结点的下一个结点
Node * p_next = p->next;
//第二结点的下一个结点
Node * q_next = q->next;
//a的下一个结点指向第二个结点q
a->next = q;
//第二结点的下一个结点指向第一个结点的下一个结点
q->next = p_next;
//b的下一个结点指向第一个结点p
b->next = p;
//第一个结点的下一个结点指向第二个结点的下一个结点
p->next = q_next;
}
排序时候的代码,切记交换结点都是前后结点交换,所以交换完成后,L就已经被移动到下一个结点了,故不要再执行:L=L->next
//线性表的排序,交换结点
void Listsort_Node(Node* & head) {
int i = 0;
int j = 0;
//用于变量链表
Node * L = head;
//作为一个临时量
Node * p;
Node * p1;
//如果链表为空直接返回
if (head->value == 0)return;
int flag = 0;
cout << head->value << endl;
for (i = 0; i < head->value - 1; i++) {
L = head->next;
for (j = 0; j < head->value - 1 - i; j++) {
//如果我们交换了结点,那么我们就已经在交换结点的时候,把L移动到下一个结点了,所以不要
//再执行:L = L->next;,否则会报错的
if (L->value > L->next->value) {
flag = 1;
swap_node(head, j + 1, j + 2);
}
if (flag == 1) {
flag = 0;
}
else {
L = L->next;
}
}
}
}
好了,今天的就写到这里了,今天通过写交换结点,发现链表真的很容易忽悠人,我就被忽悠了一个小时,才知道那个结点已经被移动到下一个结点了。
最后,补充一个实现链表反转的好方法(感觉你在头文件里面计算一下链表的长度可以带来很多遍历的)
void rollback(Node * & head) {
//先知道了最后一个元素和第一个元素的位置
int end = head->value;
int start = 1;
//两边同时开工
//进行调换
while (1) {
if (end == start)
return;
swap_node(head, end, start);
--end;
++start;
}
}
希望大家,对我写的代码做出一些评价。我想想还是直接贴个完成的代码出来好了,调转代码也在里面了
include<iostream>
#include<ctime>
#include<cstdlib>
#include<windows.h>
#include<algorithm>
using namespace std;
typedef int Elemtype;
//链式结构,我们打算在链表中添加一个
//保存长度的头结点,加入这个结点可以方便我们对结点做一些
//基本的操作,结点保存的是线性表的长度
struct Node
{
//结点的值,如果是头结点,保存是链表的长度
Elemtype value;
//下一个结点的地址
Node * next;
};
//创建一个空链表,每个头结点就代表一个链表
void InitList(Node * & head) {
head = new Node();
head->value = 0;
head->next = NULL;
}
//销毁一个链表
void DestroyList(Node * & head) {
delete head;
head = NULL;
}
//清空整个列表
void ClearList(Node * & head) {
head->value = 0;
head->next = NULL;
}
//插入函数
bool Listinsert(Node * & head, int i, Elemtype value) {
//插入到前面的方法
int j = 0;
Node * L = head;
//如果插入的位置不合法,直接返回错误提示
if (i<1 || i>head->value + 1)return false;
//得到插入位置的前一个结点
while (j < i - 1) {
L = L->next;
++j;
}
//s是一个临时结点
Node * s = new Node();
s->value = value; //先对临时结点赋值
s->next = L->next; //让临时结点下一个位置指向当前需要插入前一个结点的下一个位置
L->next = s; //让前一个结点下一个位置指向临时结点,完成
//线性表的长度加一
++head->value;
return true;
}
//得到某个位置上的值
Node * getitem(Node * & head, int i) {
//我们要求程序返回特定位置上的值
//我们一样是从头结点开始寻找该位置
int j = 0;
Node * L = head;
//想要的那个位置是否合法
if (i<1 || i >head->value)return NULL;
//同样是先得到前一个结点
while (j < i - 1) {
L = L->next;
++j;
}
//value = L->next->value;
return L;
}
//线性表的排序,采用冒泡排序,直接遍历链表
void Listsort(Node* & head) {
int i = 0;
int j = 0;
//用于变量链表
Node * L = head;
//作为一个临时量
Node * p;
Node * p1;
//如果链表为空直接返回
if (head->value == 0)return;
for (i = 0; i < head->value - 1; i++) {
L = head->next;
for (j = 0; j < head->value - i - 1; j++) {
//得到两个值
p = L;
p1 = L->next;
//如果前面的那个比后面的那个大,就交换它们之间的是数据域
if (p->value > p1->value) {
Elemtype temp = p->value;
p->value = p1->value;
p1->value = temp;
}
L = L->next;
}
}
}
//通过数组来完成我的排序
void Listsort_by_array(Node* & head) {
int i = 0;
int j = 0;
//用于变量链表
Node * L = head;
//如果链表为空直接返回
if (head->value == 0)return;
Elemtype * copy = new Elemtype[head->value];
//变量链表,存放数组
for (i = 0; i < head->value; i++) {
L = L->next;
copy[i] = L->value;
}
//调用STL中的sort函数
sort(copy, copy + head->value);
L = head;
//存放回链表中
for (i = 0; i < head->value; i++) {
L = L->next;
L->value = copy[i];
}
}
//参数为头结点和需要交换的两个结点的位置(起点为1)
void swap_node(Node * & head,int i,int j) {
//位置不合法
if (i<1 || j<1 || i>head->value || j >head->value) {
cout << "请检查位置是否合法" << endl;
return;
}
//同一个位置不用交换
if (i == j)
{
return;
}
//相邻两个交换比较简单
if (abs(i - j) == 1) {
//位置靠前的那个结点的前一个结点
Node * pre;
if (i < j)
pre = getitem(head, i);
else
pre = getitem(head, j);
//保存第一个结点
Node * a = pre->next;
//保存第二结点
Node * b = a->next;
//改变pre下一个结点的值
pre->next = b;
//必须先把b的下一个结点值给a先
a->next = b->next;
//让b的下一个结点等于a
b->next = a;
return;
}
//第一个结点前一个结点
Node * a = getitem(head, i);
//第二个结点的前一个结点
Node * b = getitem(head, j);
//第一个结点
Node * p = a->next;
//第二个结点
Node * q = b->next;
//第一个结点的下一个结点
Node * p_next = p->next;
//第二结点的下一个结点
Node * q_next = q->next;
//a的下一个结点指向第二个结点q
a->next = q;
//第二结点的下一个结点指向第一个结点的下一个结点
q->next = p_next;
//b的下一个结点指向第一个结点p
b->next = p;
//第一个结点的下一个结点指向第二个结点的下一个结点
p->next = q_next;
}
//反转
void rollback(Node * & head) {
//先知道了最后一个元素和第一个元素的位置
int end = head->value;
int start = 1;
//两边同时开工
//进行调换
while (1) {
if (end <= start)
return;
swap_node(head, end, start);
--end;
++start;
}
}
void print(Node * & head);
//线性表的排序,采用冒泡排序,直接遍历链表
//线性表的排序,交换结点
void Listsort_node(Node* & head) {
int i = 0;
int j = 0;
//用于变量链表
Node * L = head;
//作为一个临时量
Node * p;
Node * p1;
//如果链表为空直接返回
if (head->value == 0)return;
int flag = 0;
for (i = 0; i < head->value - 1; i++) {
L = head->next;
for (j = 0; j < head->value - 1 - i; j++) {
//如果我们交换了结点,那么我们就已经在交换结点的时候,把L移动到下一个结点了,所以不要
//再执行:L = L->next;,否则会报错的
if (L->value > L->next->value) {
flag = 1;
swap_node(head, j + 1, j + 2);
}
if (flag == 1) {
flag = 0;
}
else {
L = L->next;
}
}
}
}
void print(Node * & head) {
//输出我们只需要传入头结点,然后循环判断当前结点下一个结点是否为空,
//这样就可以输出所有内容
Node * L = head;
while (L->next) {
L = L->next;
cout << L->value << " ";
}
cout << endl;
}
int main() {
//链表的头结点,不存放任何值,首先初始化头结点
Node * head;
Node * head_array;
Node * head_node;
Node * head_roll;
srand((int)time(NULL)); //每次执行种子不同,生成不同的随机数
//创建一个链表
InitList(head);
InitList(head_array);
InitList(head_node);
InitList(head_roll);
int i;
cout << "请输入需要插入元素个数" << endl;
int n;
cin >> n;//5
//cout << "请输入" << n << "个值" << endl;
for (i = 0; i < n; i++) {
Elemtype temp;
temp = rand();
if (!Listinsert(head, i + 1, temp)) {
cout << "插入元素失败" << endl;
}
if (!Listinsert(head_array, i + 1, temp)) {
cout << "插入元素失败" << endl;
}
if (!Listinsert(head_node, i + 1, temp)) {
cout << "插入元素失败" << endl;
}
if (!Listinsert(head_roll, i + 1, temp)) {
cout << "插入元素失败" << endl;
}
}
cout << "初始化结果" << endl;
print(head);
cout << "反转结果" << endl;
rollback(head_roll);
print(head_roll);
cout << "冒泡排序(数据域交换)" << endl;
Listsort(head);
print(head);
cout << "借数组为媒介进行排序(数据域交换)" << endl;
Listsort_by_array(head_array);
print(head_array);
cout << "冒泡排序(结点交换)" << endl;
Listsort_node(head_node);
print(head_node);
system("pause");
return 0;
}
运行环境:vs2015
输出结果:

以上就是详解C++实现链表的排序算法的详细内容,更多关于C++ 链表排序算法的资料请关注我们其它相关文章!
相关推荐
-

Java实现单链表反转的多种方法总结
对于单链表不熟悉的可以看一下基于Java实现单链表的增删改查 一.原地反转 1.新建一个哨兵节点下一结点指向头结点 2.把待反转链表的下一节点插入到哨兵节点的下一节点 反转之前的链表:1–>2–>3–>4>–>5 加入哨兵节点:dummp–>1–>2–>3–>4>–>5 原地反转: 定义:prev=dummp.next; pcur=prev.next; prev.next=pcur.next; pcur.next=dummp.next; d
-
C语言单链表实现通讯录管理系统
本文实例为大家分享了C语言单链表实现通讯录管理系统的具体代码,供大家参考,具体内容如下 本人前几天刚刚自学了单链表,趁热打铁,赶紧写一个小小的项目练练手. 单链表的实现在本人之前的博客中有:C语言编写一个链表 通讯录管理系统 保存人的信息有: 名字 name 电话 telephone 性别 sex 年龄 age 用一个结构体来装这些信息: struct infor{ char name[20]; int age; char sex[8]; char telephone[16];
-
C语言链表实现简易通讯录
本文实例为大家分享了C语言链表实现简易通讯录的具体代码,供大家参考,具体内容如下 链表实现通讯录功能: 1.添加–(输入 姓名,电话) 2.删除-- (输入人名,删除该人) 3.查询-- (直接打印所有联系人) 4.修改-- (输入人名,修改电话) 运行效果: 代码分主函数块 和 链表块: Linklist.h #ifndef LINKLIST_H_INCLUDED #define LINKLIST_H_INCLUDED //链表节点 typedef struct Node { char nam
-
C++归并法+快速排序实现链表排序的方法
本文主要介绍了C++归并法+快速排序实现链表排序的方法,分享给大家,具体如下: 我们可以试用归并排序解决: 对链表归并排序的过程如下. 找到链表的中点,以中点为分界,将链表拆分成两个子链表.寻找链表的中点可以使用快慢指针的做法,快指针每次移动 2 步,慢指针每次移动 1步,当快指针到达链表末尾时,慢指针指向的链表节点即为链表的中点. 对两个子链表分别排序. 将两个排序后的子链表合并,得到完整的排序后的链表 上述过程可以通过递归实现.递归的终止条件是链表的节点个数小于或等于 1,即当链表为空或者链
-
Java如何实现单链表的增删改查
一.新建学生节点类 Stu_Node节点包含: 学号:int num; 姓名:String name; 性别:String gender; 下一个节点:Stu_Node next; 为了便于打印节点内容需要重写toString方法 class Stu_Node{ int num; String name; String gender; Stu_Node next; @Override public String toString() { return "Stu_Node{" + &qu
-
C语言基于单链表实现通讯录功能
本文实例为大家分享了C语言基于单链表实现通讯录功能的具体代码,供大家参考,具体内容如下 #include<stdio.h> #include<stdlib.h> #include<string.h> #pragma warning(disable:4996)://解决VS报严重性代码错误 typedef struct LNode { char name[20]; double ph_number; struct LNode* next; }LinkNode; //创建通
-
Java数据结构之链表实现(单向、双向链表及链表反转)
前言 之前学习的顺序表查询非常快,时间复杂度为O(1),但是增删改效率非常低,因为每一次增删改都会元素的移动.可以使用另一种存储方式-链式存储结构. 链表是一种物理存储单元上非连续.非顺序的存储结构.链表由一序列的结点(链表中的每一个元素成为结点)组成. 结点API设计: 类名 Node 构造方法 Node(T t,Node next) 创建Node对象 成员变量 T item:存储数据 Node next :指向下一个结点 结点类: public class Node<T>{ Node ne
-
详解C++实现链表的排序算法
一.链表排序 最简单.直接的方式(直接采用冒泡或者选择排序,而且不是交换结点,只交换数据域) //线性表的排序,采用冒泡排序,直接遍历链表 void Listsort(Node* & head) { int i = 0; int j = 0; //用于变量链表 Node * L = head; //作为一个临时量 Node * p; Node * p1; //如果链表为空直接返回 if (head->value == 0)return; for (i = 0; i < head->
-
详解Java Fibonacci Search斐波那契搜索算法代码实现
一, 斐波那契搜索算法简述 斐波那契搜索(Fibonacci search) ,又称斐波那契查找,是区间中单峰函数的搜索技术. 斐波那契搜索采用分而治之的方法,其中我们按照斐波那契数列对元素进行不均等分割.此搜索需要对数组进行排序. 与二进制搜索不同,在二进制搜索中,我们将元素分成相等的两半以减小数组范围-在斐波那契搜索中,我们尝试使用加法或减法来获得较小的范围. 斐波那契数列的公式是: Fibo(N)=Fibo(N-1)+Fibo(N-2) 此系列的前两个数字是Fibo(0) = 0和Fibo
-
详解MySQL中Order By排序和filesort排序的原理及实现
目录 1.Order By原理 2.filesort排序算法 3.优化排序 1.Order By原理 MySQL的Order By操作用于排序,并且会有多种不同的排序算法,他们的性能都是不一样的. 假设有一个表,建表的sql如下: CREATE TABLE `obtest` ( `id` BIGINT NOT NULL AUTO_INCREMENT, `a` VARCHAR ( 100 ) NOT NULL, `b` VARCHAR ( 100 ) NOT NULL, `c` VARCHAR (
-
详解Java中Collections.sort排序
Comparator是个接口,可重写compare()及equals()这两个方法,用于比价功能:如果是null的话,就是使用元素的默认顺序,如a,b,c,d,e,f,g,就是a,b,c,d,e,f,g这样,当然数字也是这样的. compare(a,b)方法:根据第一个参数小于.等于或大于第二个参数分别返回负整数.零或正整数. equals(obj)方法:仅当指定的对象也是一个 Comparator,并且强行实施与此 Comparator 相同的排序时才返回 true. Collections.
-
一文详解Vue 的双端 diff 算法
目录 前言 diff 算法 简单 diff 双端 diff 总结 前言 Vue 和 React 都是基于 vdom 的前端框架,组件渲染会返回 vdom,渲染器再把 vdom 通过增删改的 api 同步到 dom. 当再次渲染时,会产生新的 vdom,渲染器会对比两棵 vdom 树,对有差异的部分通过增删改的 api 更新到 dom. 这里对比两棵 vdom 树,找到有差异的部分的算法,就叫做 diff 算法. diff 算法 我们知道,两棵树做 diff,复杂度是 O(n^3) 的,因为每个节
-
详解Java实现的k-means聚类算法
需求 对MySQL数据库中某个表的某个字段执行k-means算法,将处理后的数据写入新表中. 源码及驱动 kmeans_jb51.rar 源码 import java.sql.*; import java.util.*; /** * @author tianshl * @version 2018/1/13 上午11:13 */ public class Kmeans { // 源数据 private List<Integer> origins = new ArrayList<>()
-
详解用java描述矩阵求逆的算法
今天很开心把困扰几天的问题解决了,在学习线性代数这门课程的时候.想通过程序实现里面的计算方法,比如矩阵求逆,用java代码该如何描述呢? 首先,咱们先用我们所交流语言描述一下算法思路: 1.求出一个矩阵A对应的行列式在第i,j(i表示行,j表示列)位置的余子式(余子式前面乘以-1^(i+j)即得代数余子式): 2.根据代数余子式求得矩阵A行列式的值.(行列式展开法): 3.根据代数余子式和行列式的值求出伴随矩阵: 4.由伴随矩阵和矩阵行列式值求逆矩阵.(A^-1 = A* / |A|). 了解上
-
详解Redis用链表实现消息队列
前言 Redis链表经常会被用于消息队列的服务,以完成多程序之间的消息交换.个人认为redis消息队列有一个好处,就是可以实现分布式和共享,就和memcache作为mysql的缓存和mysql自带的缓存一样. 链表实现消息队列 Redis链表支持前后插入以及前后取出,所以如果往尾部插入元素,往头部取出元素,这就是一种消息队列,也可以说是消费者/生产者模型.可以利用lpush和rpop来实现.但是有一个问题,如果链表中没有数据,那么消费者将要在while循环中调用rpop,这样以来就浪费cpu资源
-
详解js数组的完全随机排列算法
Array.prototype.sort 方法被许多 JavaScript 程序员误用来随机排列数组.最近做的前端星计划挑战项目中,一道实现 blackjack 游戏的问题,就发现很多同学使用了 Array.prototype.sort 来洗牌. 洗牌 以下就是常见的完全错误的随机排列算法: function shuffle(arr){ return arr.sort(function(){ return Math.random() - 0.5; }); } 以上代码看似巧妙利用了 Array.
-
Python数据结构与算法之链表定义与用法实例详解【单链表、循环链表】
本文实例讲述了Python数据结构与算法之链表定义与用法.分享给大家供大家参考,具体如下: 本文将为大家讲解: (1)从链表节点的定义开始,以类的方式,面向对象的思想进行链表的设计 (2)链表类插入和删除等成员函数实现时需要考虑的边界条件, prepend(头部插入).pop(头部删除).append(尾部插入).pop_last(尾部删除) 2.1 插入: 空链表 链表长度为1 插入到末尾 2.2 删除 空链表 链表长度为1 删除末尾元素 (3)从单链表到单链表的一众变体: 带尾节点的单链表