opencv3/C++ HOG特征提取方式
HOG特征
HOG(Histograms of Oriented Gradients)梯度方向直方图
通过利用梯度信息能反映图像目标的边缘信息并通过局部梯度的大小将图像局部的外观和形状特征化.在论文Histograms of Oriented Gradients for Human Detection中被提出.
HOG特征的提取过程为:
Gamma归一化;
计算梯度;
划分cell
组合成block,统计block直方图;
梯度直方图归一化;
收集HOG特征。
Gamma归一化:
对图像颜色进行Gamma归一化处理,降低局部阴影及背景因素的影响.
计算梯度:
通过差分计算出图像在水平方向上及垂直方向上的梯度:

然后得到各个像素点的梯度的幅值及方向:

划分cell
将整个窗口划分成大小相同互不重叠的细胞单元cell(如8×8像素),计算出每个cell的梯度大小及方向.然后将每像素的梯度方向在0−180o0−180o 区间内(无向:0-180,有向:0-360)平均分为9个bins,每个cell内的像素用幅值来表示权值,为其所在的梯度直方图进行加权投票.
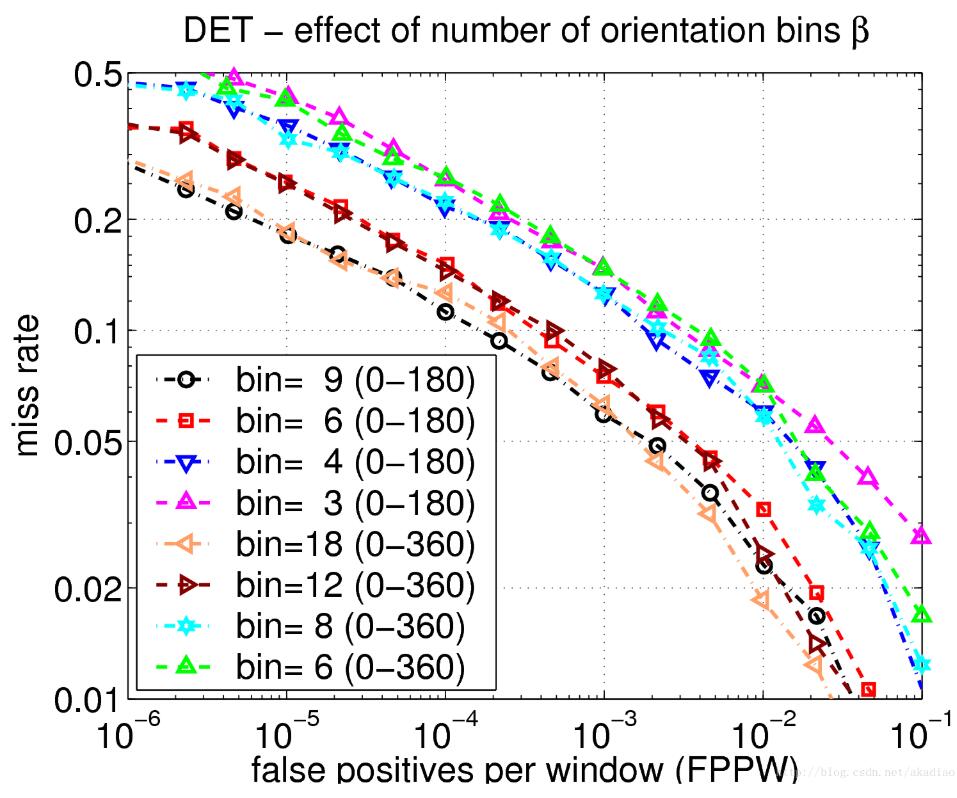
9bins:

如图,不同数量的bins下的错误率:
组合成block,统计block直方图
将2×2个相邻的cell组成大小为16×16的像素块即block.依次将block大小的滑动窗口从左到右从上到下滑动,求其梯度方向直方图向量.

如图,不同大小的cell与不同大小的block作用下的效果对比:

梯度直方图归一化
作者对比了L2-norm、L1-norm、L1-sqrt等归一化方法,发现都比非标准数据有显着的改善.其中L2-norm和L1-sqrt效果最好,而L1-norm检测效果要比L2-norm和L1-sqrt低5%.
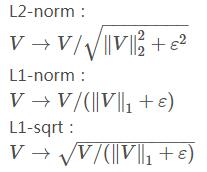
如图,不同的归一化方法效果对比:

这样通过归一化能够进一步地对光照、阴影和边缘进行压缩.
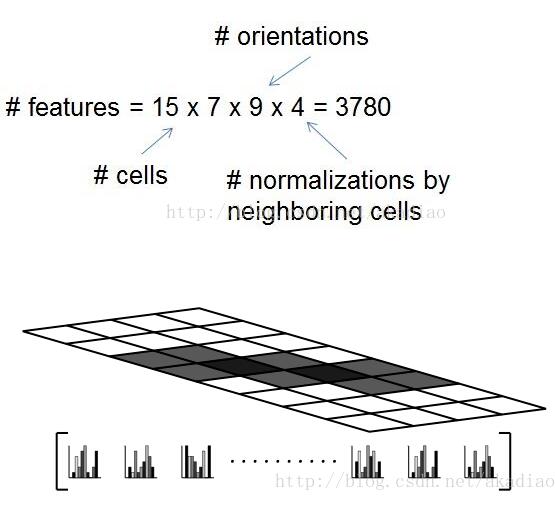
收集HOG特征
由于每个cell内的梯度方向分成了9个bins,这样每个细胞单元的HOG特征向量长度是9.

这样,对于大小为128×64大小的图像,采用8*8像素的sell,2×2个cell组成的16×16像素的block,采用8像素的block移动步长,这样检测窗口block的数量有((128-16)/8+1)×((64-16)/8+1)=15×7.则HOG特征描述符的维数为15×7×4×9.
HOG的缺点:
速度慢,实时性差;难以处理遮挡问题。
OpenCV应用
利用HOG进行行人检测时有两种用法:
1、采用HOG特征+SVM分类器进行行人检测;
2、利用HOG+SVM训练自己的XML文件。
采用第一种方法,使用HOG特征结合SVM分类器进行行人检测,简单示例:
#include <opencv2/opencv.hpp>
#include <opencv2/objdetect.hpp>
using namespace std;
using namespace cv;
int main()
{
Mat src, dst;
src = imread("E:/image/image/passerby.jpg",1);
if (src.empty())
{
printf("can not load the image...\n");
return -1;
}
dst = src.clone();
vector<Rect> findrects, findrect;
HOGDescriptor HOG;
//SVM分类器
HOG.setSVMDetector(HOGDescriptor::getDefaultPeopleDetector());
//多尺度检测
HOG.detectMultiScale(src, findrects, 0, Size(4,4), Size(0,0), 1.05, 2);
//若rects有嵌套,则取最外面的矩形存入rect
for(int i=0; i < findrects.size(); i++)
{
Rect rect = findrects[i];
int j=0;
for(; j < findrects.size(); j++)
if(j != i && (rect & findrects[j]) == rect)
break;
if( j == findrects.size())
findrect.push_back(rect);
}
//框选出检测结果
for(int i=0; i<findrect.size(); i++)
{
RNG rng(i);
Scalar color = Scalar(rng.uniform(0,255), rng.uniform(0,255), rng.uniform(0,255));
rectangle(dst, findrect[i].tl(), findrect[i].br(), color, 2);
}
imshow("src",src);
imshow("dst",dst);
waitKey();
return 0;
}


以上这篇opencv3/C++ HOG特征提取方式就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
opencv3/C++基于颜色的目标跟踪方式
inRange函数 void inRange(InputArray src, InputArray lowerb, InputArray upperb, OutputArray dst); src:输入图像: lowerb:下边界数组,阈值下限: upperb:上边界数组,阈值上限: dst:输出图像: 颜色范围如图: 示例: 捕获摄像头中的黄色方块 #include<opencv2/opencv.hpp> using namespace cv; int main() { VideoCaptu
-
opencv3/C++图像像素操作详解
RGB图像转灰度图 RGB图像转换为灰度图时通常使用: 进行转换,以下尝试通过其他对图像像素操作的方式将RGB图像转换为灰度图像. #include<opencv2/opencv.hpp> #include<math.h> using namespace cv; int main() { //像素操作 Mat src,dst; src = imread("E:/image/image/daibola.jpg"); if(src.empty()) { printf
-
opencv3/C++ 使用Tracker实现简单目标跟踪
简介 MIL: TrackerMIL 以在线方式训练分类器将对象与背景分离;多实例学习避免鲁棒跟踪的漂移问题. OLB: TrackerBoosting 基于AdaBoost算法的在线实时对象跟踪.分类器在更新步骤中使用周围背景作为反例以避免漂移问题. MedianFlow: TrackerMedianFlow 跟踪器适用于非常平滑和可预测的运动,物体在整个序列中可见. TLD: TrackerTLD 将长期跟踪任务分解为跟踪,学习和检测.跟踪器在帧之间跟踪对象.探测器本地化所观察到的所有外观,
-
基于C++实现kinect+opencv 获取深度及彩色数据
开发环境 vs2010+OPENCV2.4.10 首先,下载最新的Kinect 2 SDK http://www.microsoft.com/en-us/kinectforwindows/develop/downloads-docs.aspx 下载之后不要插入Kinect,最好也不用插入除了键盘鼠标以外的其它USB设备,然后安装SDK,安装完成之后插入Kinect,会有安装新设备的提示.安装完成之后可以去"开始"那里找到两个新安装的软件,一个是可以显示Kinect深度图,另外一个软件
-
opencv3/C++实现光流点追踪
光流金字塔 calcOpticalFlowPyrLK()函数参数说明: void calcOpticalFlowPyrLK( InputArray prevImg, //第一个8位输入图像或者通过 buildOpticalFlowPyramid()建立的金字塔 InputArray nextImg,//第二个输入图像或者和prevImg相同尺寸和类型的金字塔 InputArray prevPts, //二维点向量存储找到的光流:点坐标必须是单精度浮点数 InputOutputArray next
-
opencv3/C++ HOG特征提取方式
HOG特征 HOG(Histograms of Oriented Gradients)梯度方向直方图 通过利用梯度信息能反映图像目标的边缘信息并通过局部梯度的大小将图像局部的外观和形状特征化.在论文Histograms of Oriented Gradients for Human Detection中被提出. HOG特征的提取过程为: Gamma归一化: 计算梯度: 划分cell 组合成block,统计block直方图: 梯度直方图归一化: 收集HOG特征. Gamma归一化: 对图像颜色进行
-
opencv3/C++图像边缘提取方式
canny算子实现 使用track bar 调整canny算子参数,提取到合适的图像边缘. #include<iostream> #include<opencv2/opencv.hpp> using namespace cv; void trackBar(int, void*); int s1=0,s2=0; Mat src, dst; int main() { src = imread("E:/image/image/daibola.jpg"); if(src
-

Python中人脸图像特征提取方法(HOG、Dlib、CNN)简述
目录 人脸图像特征提取方法 (一)HOG特征提取 (二)Dlib库 (三)卷积神经网络特征提取(CNN) 人脸图像特征提取方法 (一)HOG特征提取 1.HOG简介 Histogram of Oriented Gridients,缩写为HOG,是目前计算机视觉.模式识别领域很常用的一种描述图像局部纹理的特征.它的主要思想是在一副图像中,局部目标的表象和形状能够被梯度或边缘的方向密度分布很好地描述.其本质为:梯度的统计信息,而梯度主要存在于边缘的地方. 2.实现方法 首先将图像分成小的连通区域,这
-
Python基于HOG+SVM/RF/DT等模型实现目标人行检测功能
当下基本所有的目标检测类的任务都会选择基于深度学习的方式,诸如:YOLO.SSD.RCNN等等,这一领域不乏有很多出色的模型,而且还在持续地推陈出新,模型的迭代速度很快,其实最早实现检测的时候还是基于机器学习去做的,HOG+SVM就是非常经典有效的一套框架,今天这里并不是说要做出怎样的效果,而是基于HOG+SVM来实践机器学习检测的流程. 这里为了方便处理,我是从网上找的一个数据集,主要是行人检测方向的,当然了这个用车辆检测.火焰检测等等的数据集都是可以的,本质都是一样的. 首先看下数据集,数据
-
python基于opencv实现人脸识别
将opencv中haarcascade_frontalface_default.xml文件下载到本地,我们调用它辅助进行人脸识别. 识别图像中的人脸 #coding:utf-8 import cv2 as cv # 读取原始图像 img = cv.imread('face.png') # 调用熟悉的人脸分类器 识别特征类型 # 人脸 - haarcascade_frontalface_default.xml # 人眼 - haarcascade_eye.xml # 微笑 - haarcascad
-
用Python实现简单的人脸识别功能步骤详解
前言 让我的电脑认识我,我的电脑只有认识我,才配称之为我的电脑! 今天,我们用Python实现简单的人脸识别技术! Python里,简单的人脸识别有很多种方法可以实现,依赖于python胶水语言的特性,我们通过调用包可以快速准确的达成这一目的.这里介绍的是准确性比较高的一种. 一.首先 梳理一下实现人脸识别需要进行的步骤: 流程大致如此,在此之前,要先让人脸被准确的找出来,也就是能准确区分人脸的分类器,在这里我们可以用已经训练好的分类器,网上种类较全,分类准确度也比较高,我们也可以节约在这方面花
-
10分钟学会使用python实现人脸识别(附源码)
前言 今天,我们用Python实现简单的人脸识别技术! Python里,简单的人脸识别有很多种方法可以实现,依赖于python胶水语言的特性,我们通过调用包可以快速准确的达成这一目的.这里介绍的是准确性比较高的一种. 一.首先 梳理一下实现人脸识别需要进行的步骤: 流程大致如此,在此之前,要先让人脸被准确的找出来,也就是能准确区分人脸的分类器,在这里我们可以用已经训练好的分类器,网上种类较全,分类准确度也比较高,我们也可以节约在这方面花的时间. 既然用的是python,那自然少不了包的使用了,在
-
使用Python实现简单的人脸识别功能(附源码)
目录 前言 一.首先 二.接下来 1.对照人脸获取 2. 通过算法建立对照模型 3.识别 前言 今天,我们用Python实现简单的人脸识别技术! Python里,简单的人脸识别有很多种方法可以实现,依赖于python胶水语言的特性,我们通过调用包可以快速准确的达成这一目的.这里介绍的是准确性比较高的一种. 一.首先 梳理一下实现人脸识别需要进行的步骤: 流程大致如此,在此之前,要先让人脸被准确的找出来,也就是能准确区分人脸的分类器,在这里我们可以用已经训练好的分类器,网上种类较全,分类准确度也比
-
基于opencv的行人检测(支持图片视频)
基于方向梯度直方图(HOG)/线性支持向量机(SVM)算法的行人检测方法中存在检测速度慢的问题,如下图所示,对一张400*490像素的图片进行检测要接近800毫秒,所以hog+svm的方法放在视频中进行行人检测时,每秒只能检测1帧图片,1帧/s根本不能达到视频播放的流畅性. 本文采用先从视频每帧的图像中提取出物体的轮廓(也可以对前后两针图片做差,只对有变化的部分进行检测,其目的一样,都是减少运算的面积),再对每个轮廓进行HOG+SVM检测,判断是否为行人.可以大大的缩减HOG+SVM的面积,经实
-
Python3+OpenCV实现简单交通标志识别流程分析
由于该项目是针对中小学生竞赛并且是第一次举行,所以识别的目标交通标志仅仅只有直行.右转.左转和停车让行. 数据集: 链接: https://pan.baidu.com/s/1SL0qE-qd4cuatmfZeNuK0Q 提取码: vuvi 源代码:https://github.com/ccxiao5/Traffic_sign_recognition 整体流程如下: 数据集收集(包括训练集和测试集的分类) 图像预处理 图像标注 根据标注分割得到目标图像 HOG特征提取 训练得到模型 将模型带入识