TensorFlow tf.nn.softmax_cross_entropy_with_logits的用法
在计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_entropy_with_logits,那么它到底是怎么做的呢?
首先明确一点,loss是代价值,也就是我们要最小化的值
tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None)
除去name参数用以指定该操作的name,与方法有关的一共两个参数:
第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[batchsize,num_classes],单样本的话,大小就是num_classes
第二个参数labels:实际的标签,大小同上
具体的执行流程大概分为两步:
第一步是先对网络最后一层的输出做一个softmax,这一步通常是求取输出属于某一类的概率,对于单样本而言,输出就是一个num_classes大小的向量([Y1,Y2,Y3...]其中Y1,Y2,Y3...分别代表了是属于该类的概率)
softmax的公式是: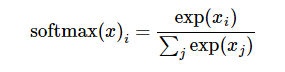
至于为什么是用的这个公式?这里不介绍了,涉及到比较多的理论证明
第二步是softmax的输出向量[Y1,Y2,Y3...]和样本的实际标签做一个交叉熵,公式如下:
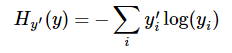
其中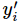 指代实际的标签中第i个的值(用mnist数据举例,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
指代实际的标签中第i个的值(用mnist数据举例,如果是3,那么标签是[0,0,0,1,0,0,0,0,0,0],除了第4个值为1,其他全为0)
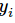 就是softmax的输出向量[Y1,Y2,Y3...]中,第i个元素的值
就是softmax的输出向量[Y1,Y2,Y3...]中,第i个元素的值
显而易见,预测越准确,结果的值越小(别忘了前面还有负号),最后求一个平均,得到我们想要的loss
注意!!!这个函数的返回值并不是一个数,而是一个向量,如果要求交叉熵,我们要再做一步tf.reduce_sum操作,就是对向量里面所有元素求和,最后才得到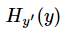 ,如果求loss,则要做一步tf.reduce_mean操作,对向量求均值!
,如果求loss,则要做一步tf.reduce_mean操作,对向量求均值!
理论讲完了,上代码
import tensorflow as tf
#our NN's output
logits=tf.constant([[1.0,2.0,3.0],[1.0,2.0,3.0],[1.0,2.0,3.0]])
#step1:do softmax
y=tf.nn.softmax(logits)
#true label
y_=tf.constant([[0.0,0.0,1.0],[0.0,0.0,1.0],[0.0,0.0,1.0]])
#step2:do cross_entropy
cross_entropy = -tf.reduce_sum(y_*tf.log(y))
#do cross_entropy just one step
cross_entropy2=tf.reduce_sum(tf.nn.softmax_cross_entropy_with_logits(logits, y_))#dont forget tf.reduce_sum()!!
with tf.Session() as sess:
softmax=sess.run(y)
c_e = sess.run(cross_entropy)
c_e2 = sess.run(cross_entropy2)
print("step1:softmax result=")
print(softmax)
print("step2:cross_entropy result=")
print(c_e)
print("Function(softmax_cross_entropy_with_logits) result=")
print(c_e2)
输出结果是:
step1:softmax result=
[[ 0.09003057 0.24472848 0.66524094]
[ 0.09003057 0.24472848 0.66524094]
[ 0.09003057 0.24472848 0.66524094]]
step2:cross_entropy result=
1.22282
Function(softmax_cross_entropy_with_logits) result=
1.2228
最后大家可以试试e^1/(e^1+e^2+e^3)是不是0.09003057,发现确实一样!!这也证明了我们的输出是符合公式逻辑的
到此这篇关于TensorFlow tf.nn.softmax_cross_entropy_with_logits的用法的文章就介绍到这了,更多相关TensorFlow tf.nn.softmax_cross_entropy_with_logits内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
TensorFlow tf.nn.conv2d实现卷积的方式
实验环境:tensorflow版本1.2.0,python2.7 介绍 惯例先展示函数: tf.nn.conv2d(input, filter, strides, padding, use_cudnn_on_gpu=None, name=None) 除去name参数用以指定该操作的name,与方法有关的一共五个参数: input: 指需要做卷积的输入图像,它要求是一个Tensor,具有[batch, in_height, in_width, in_channels]这样的shape,具体含义是[
-
对tensorflow中tf.nn.conv1d和layers.conv1d的区别详解
在用tensorflow做一维的卷积神经网络的时候会遇到tf.nn.conv1d和layers.conv1d这两个函数,但是这两个函数有什么区别呢,通过计算得到一些规律. 1.关于tf.nn.conv1d的解释,以下是Tensor Flow中关于tf.nn.conv1d的API注解: Computes a 1-D convolution given 3-D input and filter tensors. Given an input tensor of shape [batch, in_wi
-
TensorFlow tf.nn.max_pool实现池化操作方式
max pooling是CNN当中的最大值池化操作,其实用法和卷积很类似 有些地方可以从卷积去参考[TensorFlow] tf.nn.conv2d实现卷积的方式 tf.nn.max_pool(value, ksize, strides, padding, name=None) 参数是四个,和卷积很类似: 第一个参数value:需要池化的输入,一般池化层接在卷积层后面,所以输入通常是feature map,依然是[batch, height, width, channels]这样的shape 第
-
TensorFlow tf.nn.softmax_cross_entropy_with_logits的用法
在计算loss的时候,最常见的一句话就是tf.nn.softmax_cross_entropy_with_logits,那么它到底是怎么做的呢? 首先明确一点,loss是代价值,也就是我们要最小化的值 tf.nn.softmax_cross_entropy_with_logits(logits, labels, name=None) 除去name参数用以指定该操作的name,与方法有关的一共两个参数: 第一个参数logits:就是神经网络最后一层的输出,如果有batch的话,它的大小就是[bat
-
TensorFlow tf.nn.conv2d_transpose是怎样实现反卷积的
今天来介绍一下Tensorflow里面的反卷积操作,网上反卷积的用法的介绍比较少,希望这篇教程可以帮助到各位 反卷积出自这篇论文:Deconvolutional Networks,有兴趣的同学自行了解 首先无论你如何理解反卷积,请时刻记住一点,反卷积操作是卷积的反向 如果你随时都记住上面强调的重点,那你基本就理解一大半了,接下来通过一些函数的介绍为大家强化这个观念 conv2d_transpose(value, filter, output_shape, strides, padding="SA
-
Tensorflow tf.nn.atrous_conv2d如何实现空洞卷积的
实验环境:tensorflow版本1.2.0,python2.7 介绍 关于空洞卷积的理论可以查看以下链接,这里我们不详细讲理论: 1.Long J, Shelhamer E, Darrell T, et al. Fully convolutional networks for semantic segmentation[C]. Computer Vision and Pattern Recognition, 2015. 2.Yu, Fisher, and Vladlen Koltun. "Mu
-
Tensorflow tf.nn.depthwise_conv2d如何实现深度卷积的
实验环境:tensorflow版本1.2.0,python2.7 介绍 depthwise_conv2d来源于深度可分离卷积: Xception: Deep Learning with Depthwise Separable Convolutions tf.nn.depthwise_conv2d(input,filter,strides,padding,rate=None,name=None,data_format=None) 除去name参数用以指定该操作的name,data_format指定
-

python人工智能tensorflow函数tf.nn.dropout使用方法
目录 前言 tf.nn.dropout函数介绍 例子 代码 keep_prob = 0.5 keep_prob = 1 前言 神经网络在设置的神经网络足够复杂的情况下,可以无限逼近一段非线性连续函数,但是如果神经网络设置的足够复杂,将会导致过拟合(overfitting)的出现,就好像下图这样. 看到这个蓝色曲线,我就知道: 很明显蓝色曲线是overfitting的结果,尽管它很好的拟合了每一个点的位置,但是曲线是歪歪曲曲扭扭捏捏的,这个的曲线不具有良好的鲁棒性,在实际工程实验中,我们更希望得到
-
Tensorflow tf.tile()的用法实例分析
tf.tile()应用于需要张量扩展的场景,具体说来就是: 如果现有一个形状如[width, height]的张量,需要得到一个基于原张量的,形状如[batch_size,width,height]的张量,其中每一个batch的内容都和原张量一模一样.tf.tile使用方法如: tile( input, multiples, name=None ) import tensorflow as tf a = tf.constant([7,19]) a1 = tf.tile(a,multiples=[
-
tf.truncated_normal与tf.random_normal的详细用法
本文介绍了tf.truncated_normal与tf.random_normal的详细用法,分享给大家,具体如下: tf.truncated_normal 复制代码 代码如下: tf.truncated_normal(shape, mean=0.0, stddev=1.0, dtype=tf.float32, seed=None, name=None) 从截断的正态分布中输出随机值. 生成的值服从具有指定平均值和标准偏差的正态分布,如果生成的值大于平均值2个标准偏差的值则丢弃重新选择. 在正态