使用高斯Redis实现二级索引的方法
目录
- 一、背景
- 二、场景一:词典补全
- 2.1 基本方案
- 2.2 与频率相关的词典补全
- 三、场景二:多维索引
- 3.1 数据编码
- 3.2 添加新元素
- 3.3 查询
- 四、总结
一、背景
提起索引,第一印象就是数据库的名词,但是,高斯Redis也可以实现二级索引!!!高斯Redis中的二级索引一般利用zset来实现。高斯Redis相比开源Redis有着更高的稳定性、以及成本优势,使用高斯Redis zset实现业务二级索引,可以获得性能与成本的双赢。
索引的本质就是利用有序结构来加速查询,因而通过Zset结构高斯Redis可以轻松实现数值类型以及字符类型索引。
• 数值类型索引(zset按分数排序):
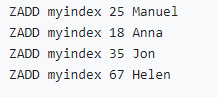
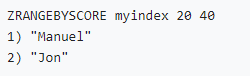
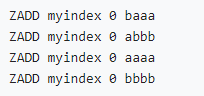
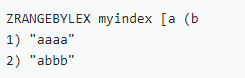
• 字符类型索引(分数相同时zset按字典序排序):
下面让我们切入两类经典业务场景,看看如何使用高斯Redis来构建稳定可靠的二级索引系统。
二、场景一:词典补全
当在浏览器中键入查询时,浏览器通常会按照可能性推荐相同前缀的搜索,这种场景可以用高斯Redis二级索引功能实现。
2.1 基本方案
最简单的方法是将用户的每个查询添加到索引中。当需要进行用户输入补全推荐时,使用ZRANGEBYLEX执行范围查询即可。如果不希望返回太多条目,高斯Redis还支持使用LIMIT选项来减少结果数量。
• 将用户搜索banana添加进索引:
ZADD myindex 0 banana:1
• 假设用户在搜索表单中输入“bit”,并且我们想提供可能以“bit”开头的搜索关键字。
ZRANGEBYLEX myindex "[bit" "[bit\xff"
即使用ZRANGEBYLEX进行范围查询,查询的区间为用户现在输入的字符串,以及相同的字符串加上一个尾随字节255(\xff)。通过这种方式,我们可以获得以用户键入字符串为前缀的所有字符串。
2.2 与频率相关的词典补全
实际应用中通常希望按照出现频率自动排序补全词条,同时可以清除不再流行的词条,并自动适应未来的输入。我们依然可以使用高斯Redis的ZSet结构实现这一目标,只是在索引结构中,不仅需要存储搜索词,还需要存储与之关联的频率。
• 将用户搜索banana添加进索引
• 判断banana是否存在
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1
• 假设banana不存在,添加banana:1,其中1是频率
ZADD myindex 0 banana:1
• 假设banana存在,需要递增频率
若ZRANGEBYLEX myindex "[banana:" + LIMIT 0 1 中返回的频率为1
1)删除旧条目:
ZREM myindex 0 banana:1
2)频率加一重新加入:
ZADD myindex 0 banana:2
请注意,由于可能存在并发更新,因此应通过Lua脚本发送上述三个命令,用Lua script自动获得旧计数并增加分数后重新添加条目。
• 假设用户在搜索表单中输入“banana”,并且我们想提供相似的搜索关键字。通过ZRANGEBYLEX获得结果后按频率排序。
ZRANGEBYLEX myindex "[banana:" + LIMIT 0 10 1) "banana:123" 2) "banaooo:1" 3) "banned user:49" 4) "banning:89"
• 使用流算法清除不常用输入。从返回的条目中随机选择一个条目,将其分数减1,然后将其与新分数重新添加。但是,如果新分数为0,我们需从列表中删除该条目。
• 若随机挑选的条目频率是1,如banaooo:1
ZREM myindex 0 banaooo:1
• 若随机挑选的条目频率大于1,如banana:123
ZREM myindex 0 banana:123 ZADD myindex 0 banana:122
从长远来看,该索引会包含热门搜索,如果热门搜索随时间变化,它还会自动适应。
三、场景二:多维索引
除了单一维度上的查询,高斯Redis同样支持在多维数据中的检索。例如,检索所有年龄在50至55岁之间,同时薪水在70000至85000之间的人。实现多维二级索引的关键是通过编码将二维的数据转化为一维数据,再基于高斯Redis zset存储。
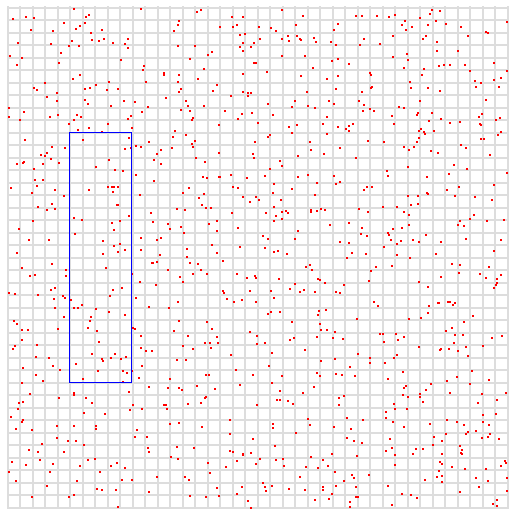
从可视化视角表示二维索引。下图空间中有一些点,它们代表我们的数据样本,其中x和y是两个变量,其最大值均为400。图片中的蓝色框代表我们的查询。我们希望查询x介于50和100之间,y介于100和300之间的所有点。
3.1 数据编码
若插入数据点为x = 75和y = 200
1)填充0(数据最大为400,故填充3位)
x = 075
y = 200
2)交织数字,以x表示最左边的数字,以y表示最左边的数字,依此类推,以便创建一个编码
027050
若使用00和99替换最后两位,即027000 to 027099,map回x和y,即:
x = 70-79
y = 200-209
因此,针对x=70-79和y = 200-209的二维查询,可以通过编码map成027000 to 027099的一维查询,这可以通过高斯Redis的Zset结构轻松实现。

同理,我们可以针对后四/六/etc位数字进行相同操作,从而获得更大范围。
3)使用二进制
为获得更细的粒度,可以将数据用二进制表示,这样在替换数字时,每次会得到比原来大二倍的搜索范围。假设我们每个变量仅需要9位(以表示最多400个值的数字),我们采用二进制形式的数字将是:
x = 75 -> 001001011
y = 200 -> 011001000
交织后,000111000011001010
让我们看看在交错表示中用0s ad 1s替换最后的2、4、6、8,...位时我们的范围是什么:

3.2 添加新元素
若插入数据点为x = 75和y = 200
x = 75和y = 200二进制交织编码后为000111000011001010,
ZADD myindex 0 000111000011001010
3.3 查询
查询:x介于50和100之间,y介于100和300之间的所有点
从索引中替换N位会给我们边长为2^(N/2)的搜索框。因此,我们要做的是检查搜索框较小的尺寸,并检查与该数字最接近的2的幂,并不断切分剩余空间,随后用ZRANGEBYLEX进行搜索。
下面是示例代码:
def spacequery(x0,y0,x1,y1,exp)
bits=exp*2
x_start = x0/(2**exp)
x_end = x1/(2**exp)
y_start = y0/(2**exp)
y_end = y1/(2**exp)
(x_start..x_end).each{|x|
(y_start..y_end).each{|y|
x_range_start = x*(2**exp)
x_range_end = x_range_start | ((2**exp)-1)
y_range_start = y*(2**exp)
y_range_end = y_range_start | ((2**exp)-1)
puts "#{x},#{y} x from #{x_range_start} to #{x_range_end}, y from #{y_range_start} to #{y_range_end}"
# Turn it into interleaved form for ZRANGEBYLEX query.
# We assume we need 9 bits for each integer, so the final
# interleaved representation will be 18 bits.
xbin = x_range_start.to_s(2).rjust(9,'0')
ybin = y_range_start.to_s(2).rjust(9,'0')
s = xbin.split("").zip(ybin.split("")).flatten.compact.join("")
# Now that we have the start of the range, calculate the end
# by replacing the specified number of bits from 0 to 1.
e = s[0..-(bits+1)]+("1"*bits)
puts "ZRANGEBYLEX myindex [#{s} [#{e}"
}
}
end
spacequery(50,100,100,300,6)
四、总结
本文介绍了如何通过高斯Redis搭建二级索引,二级索引在电商、图(hexastore)、游戏等领域具有广泛的应用场景,高斯redis现网亦有很多类似应用。高斯Redis基于存算分离架构,依托分布式存储池确保数据强一致,可方便的支持二级索引功能,为企业客户提供稳定可靠、超高并发,且能够极速弹性扩容的核心数据存储服务。
到此这篇关于使用高斯Redis实现二级索引的文章就介绍到这了,更多相关Redis二级索引内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

springboot集成redis并使用redis生成全局唯一索引ID
部署redis Windows下搭建Reids本地集群,可参考https://www.jb51.net/article/242520.htm springboot集成 redis pom文件 <dependency> <groupId>org.springframework.boot</groupId> <artifactId>spring-boot-starter-data-redis</artifactId> </dependency&
-
简单谈谈Mysql索引与redis跳表
摘要 面试时,交流有关mysql索引问题时,发现有些人能够涛涛不绝的说出B+树和B树,平衡二叉树的区别,却说不出B+树和hash索引的区别.这种一看就知道是死记硬背,没有理解索引的本质.本文旨在剖析这背后的原理,欢迎留言探讨 问题 如果对以下问题感到困惑或一知半解,请继续看下去,相信本文一定会对你有帮助 mysql 索引如何实现 mysql 索引结构B+树与hash有何区别.分别适用于什么场景 数据库的索引还能有其他实现吗 redis跳表是如何实现的 跳表和B+树,LSM树有和区别呢 解析 首先
-
使用高斯Redis实现二级索引的方法
目录 一.背景 二.场景一:词典补全 2.1 基本方案 2.2 与频率相关的词典补全 三.场景二:多维索引 3.1 数据编码 3.2 添加新元素 3.3 查询 四.总结 一.背景 提起索引,第一印象就是数据库的名词,但是,高斯Redis也可以实现二级索引!!!高斯Redis中的二级索引一般利用zset来实现.高斯Redis相比开源Redis有着更高的稳定性.以及成本优势,使用高斯Redis zset实现业务二级索引,可以获得性能与成本的双赢. 索引的本质就是利用有序结构来加速查询,因而通过Zse
-
mybatis plus使用redis作为二级缓存的方法
建议缓存放到 service 层,你可以自定义自己的 BaseServiceImpl 重写注解父类方法,继承自己的实现.为了方便,这里我们将缓存放到mapper层.mybatis-plus整合redis作为二级缓存与mybatis整合redis略有不同. 1. mybatis-plus开启二级缓存 mybatis-plus.configuration.cache-enabled=true 2. 定义RedisTemplate的bean交给spring管理,这里为了能将对象直接存取到redis中,
-
MySQL和Redis实现二级缓存的方法详解
redis简介 Redis 是完全开源免费的,遵守BSD协议,是一个高性能的key-value数据库 Redis 与其他 key - value 缓存产品有以下三个特点: Redis支持数据的持久化,可以将内存中的数据保存在磁盘中,重启的时候可以再次加载进行使用 Redis不仅仅支持简单的key-value类型的数据,同时还提供list,set,zset,hash等数据结构的存储 Redis支持数据的备份,即master-slave模式的数据备份 优势 性能极高 - Redis能读的速度是110
-
Ajax通过XML异步提交的方法实现从数据库获取省份和城市信息实现二级联动(xml方法)
之前有写过是从JavaScript数组里获取省市信息来实现二级联动,但是似乎有很多需求是要从数据库里获取信息,所以就需要根据异步提交,局部刷新的思想来实现来提高用户交互问题 第一种方法是xml方法 1.首先在jsp页面的JavaScript,这段代码是通用的,所以把他放在函数外面,可以供其他的函数共同使用 var xhr=false; //创建XMLHttpRequst对象 if(window.XMLHttpRequest) { xhr=new XMLHttpRequest(); } else
-
Redis实现布隆过滤器的方法及原理
布隆过滤器(Bloom Filter)是1970年由布隆提出的.它实际上是一个很长的二进制向量和一系列随机映射函数.布隆过滤器可以用于检索一个元素是否在一个集合中.它的优点是空间效率和查询时间都比一般的算法要好的多,缺点是有一定的误识别率和删除困难. 本文将介绍布隆过滤器的原理以及Redis如何实现布隆过滤器. 应用场景 1.50亿个电话号码,现有10万个电话号码,如何判断这10万个是否已经存在在50亿个之中?(可能方案:数据库,set, hyperloglog) 2.新闻客户端看新闻时,它会不
-
MyBatis整合Redis实现二级缓存的示例代码
MyBatis框架提供了二级缓存接口,我们只需要实现它再开启配置就可以使用了. 特别注意,我们要解决缓存穿透.缓存穿透和缓存雪崩的问题,同时也要保证缓存性能. 具体实现说明,直接看代码注释吧! 1.开启配置 SpringBoot配置 mybatis: configuration: cache-enabled: true 2.Redis配置以及服务接口 RedisConfig.java package com.leven.mybatis.api.config; import com.fasterx
-
InnoDB主键索引树和二级索引树的场景分析
我们这里讨论InnoDB存储引擎,数据和索引存储在同一个文件student.ibd 场景1:主键索引树 uid是主键,其他字段没有添加任何索引 select * from student; 如果是这样查询,这表示整表搜索,从左到右遍历叶子节点链表,从小到大访问 select * from student where uid<5; 如果是这样查询,这表示范围查询,就直接在有序链表中遍历搜索就可以了,直到遍历到第一个不小于5的key结束遍历 select * from student where u
-
JSP 开发之hibernate配置二级缓存的方法
JSP 开发之hibernate配置二级缓存的方法 hibernate二级缓存也称为进程级的缓存或SessionFactory级的缓存. 二级缓存是全局缓存,它可以被所有的session共享. 二级缓存的生命周期和SessionFactory的生命周期一致,SessionFactory可以管理二级缓存. 常用的缓存插件 Hibernater二级缓存是一个插件,下面是几种常用的缓存插件: EhCache:可作为进程范围的缓存,存放数据的物理介质可以是内存或硬盘,对Hibernate的查询缓存提供了
-
ThinkPHP自定义Redis处理SESSION的实现方法
本文实例讲述了ThinkPHP自定义Redis处理SESSION的实现方法.分享给大家供大家参考,具体如下: 日常中我们都会使用到session来保存用户登录的信息,常用的session的保存方式有:文件保存(默认).数据库保存.Redis保存.memcached等.这里主要记录一下在用ThinkPHP处理session用Redis来保存session的用法. 1.在配置项中定义: 'SESSION_TYPE' => 'Redis', //session保存类型 'SESSION_PREFIX'
-
利用Redis实现SQL伸缩的方法
这篇文章主要介绍了利用Redis实现SQL伸缩的方法,包括讲到了锁和时间序列等方面来提升传统数据库的性能,需要的朋友可以参考下. 缓解行竞争 我们在Sentry开发的早起采用的是sentry.buffers. 这是一个简单的系统,它允许我们以简单的Last Write Wins策略来实现非常有效的缓冲计数器. 重要的是,我们借助它完全消除了任何形式的耐久性 (这是Sentry工作的一个非常可接受的方式). 操作非常简单,每当一个更新进来我们就做如下几步: 创建一个绑定到传入实体的哈希键(hash