pycharm利用pyspark远程连接spark集群的实现
0 背景
由于工作需要,利用spark完成机器学习。因此需要对spark集群进行操作。所以利用pycharm和pyspark远程连接spark集群。这里记录下遇到的问题及方法。
主要是参照下面的文献完成相应的内容,但是具体问题要具体分析。
1 方法
1.1 软件配置
spark2.3.3, hadoop2.6, python3
1.2 spark配置
Spark集群的每个节点的Python版本必须保持一致。在每个节点的$SPARK_HOME/conf/spark-env.sh中添加一行:具体看你的安装目录。
export PYSPARK_PYTHON=/home/hadoop/anaconda2/bin/python3
此步骤就是将python添加到spark的配置中。
此时,在服务器命令行输入pyspark时,可以正常进入spark。
1.3本地配置
1.3.1 首先将spark2.3.3从服务器拷贝到本地。
注意: 由于我集群安装的是spark-2.3.3-bin-without-hadoop。但是拷贝到本地后,总是报错Java gateway process… 。同时我将hadoop2.6,的包也从服务器拷贝到本地加载到程序中,同样报错。
最后,直接从spark的官网中,下载了spark-2.3.3-bin-hadoop2.6,这回就可以了。
pyspark的版本与spark的版本最好对应。比如pyspark2.3.3,spark2.3.3
# os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-without-hadoop"(无用) os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-hadoop2.6"(有用) # os.environ["HADOOP_HOME"] = r"F:\big_data\hadoop-2.6.5"(无用) # os.environ['JAVA_HOME'] = r"F:\Java\jdk1.8.0_144"(无用)
1.3.2
C:\Windows\System32….\hosts(Windows机器)中加入Spark集群Master节点的IP与主机名的映射。需要管理员权限修改。

其中的spark_cluster就是对于Master的IP的映射名。(直接写IP一样可以,映射名是为了方便)
1.3.3
添加刚刚下载解压好的spark的python目录到pycharm的project structure
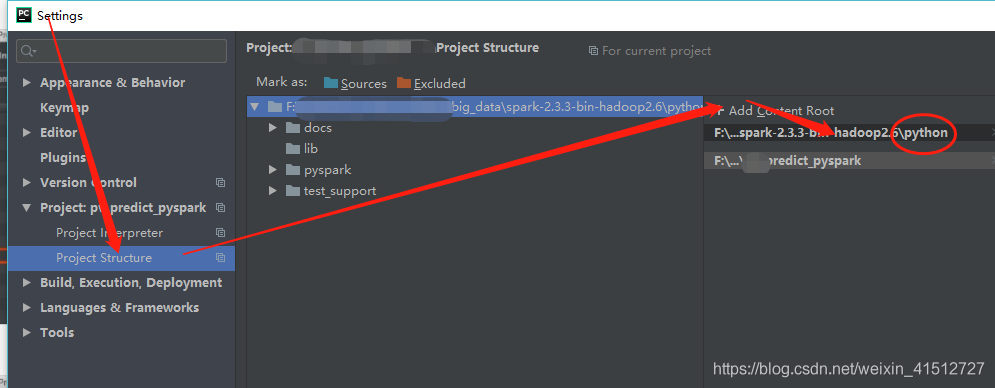
1.3.4
新建py文件,编辑Edit Configurations添加SPARK_HOME变量
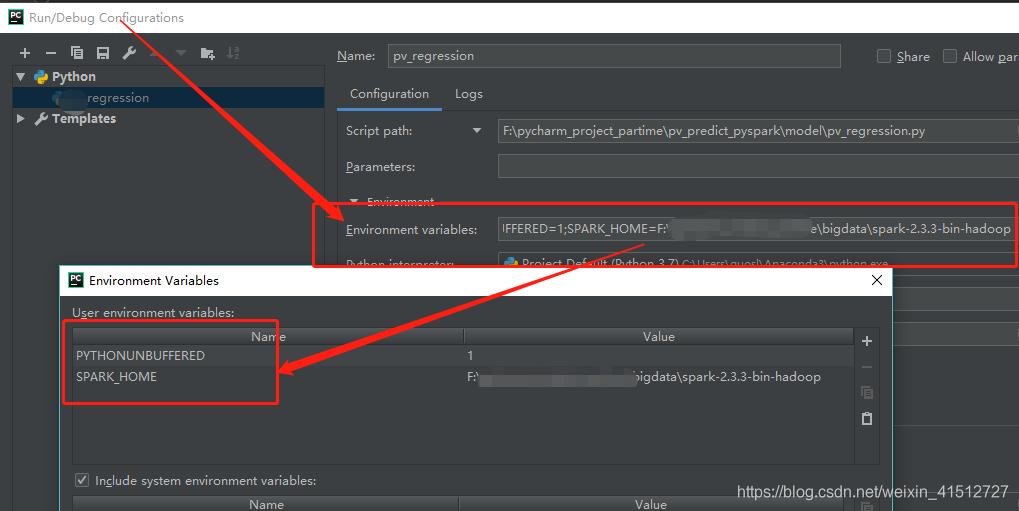
注意: 在实际中,这个不添加好像也可以。只需要在程序中加载了spark_home.比如os.envion(…spark…)
2 测试
import os
from pyspark import SparkContext
from pyspark import SparkConf
# os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-without-hadoop"
os.environ['SPARK_HOME'] = r"F:\big_data\spark-2.3.3-bin-hadoop2.6"
# os.environ["HADOOP_HOME"] = r"F:\big_data\hadoop-2.6.5"
# os.environ['JAVA_HOME'] = r"F:\Java\jdk1.8.0_144"
print(0)
conf = SparkConf().setMaster("spark://spark_cluster:7077").setAppName("test")
sc = SparkContext(conf=conf)
print(1)
logData = sc.textFile("file:///opt/spark-2.3.3-bin-without-hadoop/README.md").cache()
print(2)
print("num of a",logData)
sc.stop()

3 参考
PyCharm+PySpark远程调试的环境配置的方法
Spark下:Java gateway process exited before sending the driver its port number等问题
估计每个人遇到的问题不一样,但是大同小异,具体问题具体分析。
到此这篇关于pycharm利用pyspark远程连接spark集群的实现的文章就介绍到这了,更多相关pyspark远程连接spark集群内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pyspark.sql.DataFrame与pandas.DataFrame之间的相互转换实例
代码如下,步骤流程在代码注释中可见: # -*- coding: utf-8 -*- import pandas as pd from pyspark.sql import SparkSession from pyspark.sql import SQLContext from pyspark import SparkContext #初始化数据 #初始化pandas DataFrame df = pd.DataFrame([[1, 2, 3], [4, 5, 6]], index=['row1
-

pyspark对Mysql数据库进行读写的实现
pyspark是Spark对Python的api接口,可以在Python环境中通过调用pyspark模块来操作spark,完成大数据框架下的数据分析与挖掘.其中,数据的读写是基础操作,pyspark的子模块pyspark.sql 可以完成大部分类型的数据读写.文本介绍在pyspark中读写Mysql数据库. 1 软件版本 在Python中使用Spark,需要安装配置Spark,这里跳过配置的过程,给出运行环境和相关程序版本信息. win10 64bit java 13.0.1 spark 3.0
-
PyCharm搭建Spark开发环境实现第一个pyspark程序
一, PyCharm搭建Spark开发环境 Windows7, Java1.8.0_74, Scala 2.12.6, Spark 2.2.1, Hadoop2.7.6 通常情况下,Spark开发是基于Linux集群的,但这里作为初学者并且囊中羞涩,还是在windows环境下先学习吧. 参照这个配置本地的Spark环境. 之后就是配置PyCharm用来开发Spark.本人在这里浪费了不少时间,因为百度出来的无非就以下两种方式: 1.在程序中设置环境变量 import os import sys
-
pyspark创建DataFrame的几种方法
pyspark创建DataFrame 为了便于操作,使用pyspark时我们通常将数据转为DataFrame的形式来完成清洗和分析动作. RDD和DataFrame 在上一篇pyspark基本操作有提到RDD也是spark中的操作的分布式数据对象. 这里简单看一下RDD和DataFrame的类型. print(type(rdd)) # <class 'pyspark.rdd.RDD'> print(type(df)) # <class 'pyspark.sql.dataframe.Dat
-
pyspark 读取csv文件创建DataFrame的两种方法
方法一:用pandas辅助 from pyspark import SparkContext from pyspark.sql import SQLContext import pandas as pd sc = SparkContext() sqlContext=SQLContext(sc) df=pd.read_csv(r'game-clicks.csv') sdf=sqlc.createDataFrame(df) 方法二:纯spark from pyspark import SparkCo
-
pyspark给dataframe增加新的一列的实现示例
熟悉pandas的pythoner 应该知道给dataframe增加一列很容易,直接以字典形式指定就好了,pyspark中就不同了,摸索了一下,可以使用如下方式增加 from pyspark import SparkContext from pyspark import SparkConf from pypsark.sql import SparkSession from pyspark.sql import functions spark = SparkSession.builder.conf
-
pycharm编写spark程序,导入pyspark包的3中实现方法
一种方法: File --> Default Setting --> 选中Project Interpreter中的一个python版本-->点击右边锯齿形图标(设置)-->选择more-->选择刚才选中的那个python版本-->点击最下方编辑(也就是增加到这个python版本下)-->点击➕-->选中spark安装目录下的python目录-->一路OK. 再次在python文件中写入如下 from pyspark import SparkConf
-
windowns使用PySpark环境配置和基本操作
下载依赖 首先需要下载hadoop和spark,解压,然后设置环境变量. hadoop清华源下载 spark清华源下载 HADOOP_HOME => /path/hadoop SPARK_HOME => /path/spark 安装pyspark. pip install pyspark 基本使用 可以在shell终端,输入pyspark,有如下回显: 输入以下指令进行测试,并创建SparkContext,SparkContext是任何spark功能的入口点. >>> fro
-
如何将PySpark导入Python的放实现(2种)
方法一 使用findspark 使用pip安装findspark: pip install findspark 在py文件中引入findspark: >>> import findspark >>> findspark.init() 导入你要使用的pyspark库 >>> from pyspark import * 优点:简单快捷 缺点:治标不治本,每次写一个新的Application都要加载一遍findspark 方法二 把预编译包中的Python库
-
Linux下远程连接Jupyter+pyspark部署教程
博主最近试在服务器上进行spark编程,因此,在开始编程作业之前,要先搭建一个便利的编程环境,这样才能做到舒心地开发.本文主要有以下内容: 1.python多版本管理利器-pythonbrew 2.Jupyter notebooks 安装与使用以及远程连接方法 3.Jupyter连接pyspark,实现web端sprak开发 一.python多版本管理利器-pythonbrew 在利用python进行编程开发的时候,很多时候我们需要多个Python版本进行测试,博主之前一直在Python2.x和