python识别验证码图片实例详解
在编写自动化测试用例的时候,每次登录都需要输入验证码,后来想把让python自己识别图片里的验证码,不需要自己手动登陆,所以查了一下识别功能怎么实现,做一下笔记。
首选导入一些用到的库,re、Image、pytesseract、selenium、time
import re # 用于正则 from PIL import Image # 用于打开图片和对图片处理 import pytesseract # 用于图片转文字 from selenium import webdriver # 用于打开网站 import time # 代码运行停顿
首先需要获取验证码图片,才能进一步识别。
创建类,定义webdriver和find_element_by_selector方法,用来打开网页和定位验证码图片的元素
class VerificationCode:
def __init__(self):
self.driver = webdriver.Firefox()
self.find_element = self.driver.find_element_by_css_selector
然后打开浏览器截取验证码图片
def get_pictures(self):
self.driver.get('http://123.255.123.3') # 打开登陆页面
self.driver.save_screenshot('pictures.png') # 全屏截图
page_snap_obj = Image.open('pictures.png')
img = self.find_element('#pic') # 验证码元素位置
time.sleep(1)
location = img.location
size = img.size # 获取验证码的大小参数
left = location['x']
top = location['y']
right = left + size['width']
bottom = top + size['height']
image_obj = page_snap_obj.crop((left, top, right, bottom)) # 按照验证码的长宽,切割验证码
image_obj.show() # 打开切割后的完整验证码
self.driver.close() # 处理完验证码后关闭浏览器
return image_obj
未处理前的验证码图片如下:
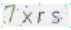
未处理的验证码图片,对于python来说识别率较低,仔细看可以发现图片里有很对五颜六色扰乱识别的点,非常影响识别率。
下面对获取的验证码进行处理。
首先用convert把图片转成黑白色。设置threshold阈值,超过阈值的为黑色
def processing_image(self):
image_obj = self.get_pictures() # 获取验证码
img = image_obj.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
threshold = 160 # 该阈值不适合所有验证码,具体阈值请根据验证码情况设置
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img
经过灰度处理后的图片
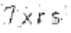
然后删除一些扰乱识别的像素点。
def delete_spot(self):
images = self.processing_image()
data = images.getdata()
w, h = images.size
black_point = 0
for x in range(1, w - 1):
for y in range(1, h - 1):
mid_pixel = data[w * y + x] # 中央像素点像素值
if mid_pixel < 50: # 找出上下左右四个方向像素点像素值
top_pixel = data[w * (y - 1) + x]
left_pixel = data[w * y + (x - 1)]
down_pixel = data[w * (y + 1) + x]
right_pixel = data[w * y + (x + 1)]
# 判断上下左右的黑色像素点总个数
if top_pixel < 10:
black_point += 1
if left_pixel < 10:
black_point += 1
if down_pixel < 10:
black_point += 1
if right_pixel < 10:
black_point += 1
if black_point < 1:
images.putpixel((x, y), 255)
black_point = 0
# images.show()
return images
经过去除噪点处理后的图片
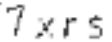
最后把处理后的图片转成文字。
先设置pytesseract的路径,因为默认路径是错的,然后转换图片为文字,由于个别图片中识别会出现处理遗漏,会被识别成空格或则点或则分号什么的,所以增加了一个去除验证码中特殊字符的处理。
def image_str(self):
image = self.delete_spot()
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe" # 设置pyteseract路径
result = pytesseract.image_to_string(image) # 图片转文字
resultj = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])", "", result) # 去除识别出来的特殊字符
result_four = resultj[0:4] # 只获取前4个字符
# print(resultj) # 打印识别的验证码
return result_four
完整代码如下:
import re # 用于正则
from PIL import Image # 用于打开图片和对图片处理
import pytesseract # 用于图片转文字
from selenium import webdriver # 用于打开网站
import time # 代码运行停顿
class VerificationCode:
def __init__(self):
self.driver = webdriver.Firefox()
self.find_element = self.driver.find_element_by_css_selector
def get_pictures(self):
self.driver.get('http://123.255.123.3') # 打开登陆页面
self.driver.save_screenshot('pictures.png') # 全屏截图
page_snap_obj = Image.open('pictures.png')
img = self.find_element('#pic') # 验证码元素位置
time.sleep(1)
location = img.location
size = img.size # 获取验证码的大小参数
left = location['x']
top = location['y']
right = left + size['width']
bottom = top + size['height']
image_obj = page_snap_obj.crop((left, top, right, bottom)) # 按照验证码的长宽,切割验证码
image_obj.show() # 打开切割后的完整验证码
self.driver.close() # 处理完验证码后关闭浏览器
return image_obj
def processing_image(self):
image_obj = self.get_pictures() # 获取验证码
img = image_obj.convert("L") # 转灰度
pixdata = img.load()
w, h = img.size
threshold = 160
# 遍历所有像素,大于阈值的为黑色
for y in range(h):
for x in range(w):
if pixdata[x, y] < threshold:
pixdata[x, y] = 0
else:
pixdata[x, y] = 255
return img
def delete_spot(self):
images = self.processing_image()
data = images.getdata()
w, h = images.size
black_point = 0
for x in range(1, w - 1):
for y in range(1, h - 1):
mid_pixel = data[w * y + x] # 中央像素点像素值
if mid_pixel < 50: # 找出上下左右四个方向像素点像素值
top_pixel = data[w * (y - 1) + x]
left_pixel = data[w * y + (x - 1)]
down_pixel = data[w * (y + 1) + x]
right_pixel = data[w * y + (x + 1)]
# 判断上下左右的黑色像素点总个数
if top_pixel < 10:
black_point += 1
if left_pixel < 10:
black_point += 1
if down_pixel < 10:
black_point += 1
if right_pixel < 10:
black_point += 1
if black_point < 1:
images.putpixel((x, y), 255)
black_point = 0
# images.show()
return images
def image_str(self):
image = self.delete_spot()
pytesseract.pytesseract.tesseract_cmd = r"C:\Program Files\Tesseract-OCR\tesseract.exe" # 设置pyteseract路径
result = pytesseract.image_to_string(image) # 图片转文字
resultj = re.sub(u"([^\u4e00-\u9fa5\u0030-\u0039\u0041-\u005a\u0061-\u007a])", "", result) # 去除识别出来的特殊字符
result_four = resultj[0:4] # 只获取前4个字符
# print(resultj) # 打印识别的验证码
return result_four
if __name__ == '__main__':
a = VerificationCode()
a.image_str()
更多关于python识别验证码图片方法请查看下面的相关链接
相关推荐
-

Python+Selenium+PIL+Tesseract自动识别验证码进行一键登录
本文介绍了Python+Selenium+PIL+Tesseract自动识别验证码进行一键登录,分享给大家,具体如下: Python 2.7 IDE Pycharm 5.0.3 Firefox浏览器:47.0.1 Selenium PIL Pytesser Tesseract 扯淡 我相信每个脚本都有自己的故事,我这个脚本来源于自己GRD教务系统,每次进行登录时,即使我输入全部正确,第一次登录一定是登不上去的!我不知道设计人员什么想法?难道是为了反爬机制?你以为一次登不上,我tm就不爬了?我
-
[机器视觉]使用python自动识别验证码详解
前言 CAPTCHA全称Completely Automated Public Turing Test to Tell Computers and Humans Apart,即全自动区分人机的图灵测试.这也是验证码诞生的主要任务.但是随着近年来大数据运算和机器视觉的发展,用机器视觉识别图像已经变得非常容易,过去用于区分人机的验证码也开始变得不再安全. 接下来就让我们从零开始,深入图像处理和算法构建,来看看使用机器视觉来识别过时的验证码( 如下所示 )究竟可以有多简单. 载入需要的程序包 & 设置
-
python使用tensorflow深度学习识别验证码
本文介绍了python使用tensorflow深度学习识别验证码 ,分享给大家,具体如下: 除了传统的PIL包处理图片,然后用pytessert+OCR识别意外,还可以使用tessorflow训练来识别验证码. 此篇代码大部分是转载的,只改了很少地方. 代码是运行在linux环境,tessorflow没有支持windows的python 2.7. gen_captcha.py代码. #coding=utf-8 from captcha.image import ImageCaptcha # pi
-
python利用Tesseract识别验证码的方法示例
无论是是自动化登录还是爬虫,总绕不开验证码,这次就来谈谈python中光学识别验证码模块tesserocr和pytesseract.tesserocr和pytesseract是Python的一个OCR识别库,但其实是对tesseract做的一层Python API封装,pytesseract是Google的Tesseract-OCR引擎包装器:所以它们的核心是tesseract,因此在安装tesserocr之前,我们需要先安装tesseract. 下载安装 下载地址:https://digi.b
-
Python完全识别验证码自动登录实例详解
1.直接贴代码 #!C:/Python27 #coding=utf-8 from selenium import webdriver from selenium.webdriver.common.keys import Keys from pytesser import * from PIL import Image,ImageEnhance,ImageFilter from selenium.common.exceptions import NoSuchElementException,Tim
-
python+selenium识别验证码并登录的示例代码
由于工作需要,登录网站需要用到验证码.最初是研究过验证码识别的,但是总是不能获取到我需要的那个验证码.直到这周五,才想起这事来,昨天顺利的解决了. 下面正题: python版本:3.4.3 所需要的代码库:PIL,selenium,tesseract 先上代码: #coding:utf-8 import subprocess from PIL import Image from PIL import ImageOps from selenium import webdriver import t
-
python入门教程之识别验证码
前言 验证码?我也能破解? 关于验证码的介绍就不多说了,各种各样的验证码在人们生活中时不时就会冒出来,身为学生日常接触最多的就是教务处系统的验证码了,比如如下的验证码: 识别办法 模拟登陆有着复杂的步骤,在这里咱们不管其他操作,只负责根据输入的一张验证码图片返回一个答案字符串. 我们知道验证码为了制作干扰,会把图片弄成五颜六色的样子,而我们首先就是要去除这些干扰,这一步就需要不断试验了,增强图片色彩,加大对比度等等都可以产生帮助. 在经过各种对图片的操作之后,终于找到了比较完美的去除干扰方案.可
-
python识别验证码图片实例详解
在编写自动化测试用例的时候,每次登录都需要输入验证码,后来想把让python自己识别图片里的验证码,不需要自己手动登陆,所以查了一下识别功能怎么实现,做一下笔记. 首选导入一些用到的库,re.Image.pytesseract.selenium.time import re # 用于正则 from PIL import Image # 用于打开图片和对图片处理 import pytesseract # 用于图片转文字 from selenium import webdriver # 用于打开网站
-
Python 通过URL打开图片实例详解
Python 通过URL打开图片实例详解 不论是用OpenCV还是PIL,skimage等库,在之前做图像处理的时候,几乎都是读取本地的图片.最近尝试爬虫爬取图片,在保存之前,我希望能先快速浏览一遍图片,然后有选择性的保存.这里就需要从url读取图片了.查了很多资料,发现有这么几种方法,这里做个记录. 本文用到的图片URL如下: img_src = 'http://wx2.sinaimg.cn/mw690/ac38503ely1fesz8m0ov6j20qo140dix.jpg' 1.用Open
-
python读取二进制mnist实例详解
python读取二进制mnist实例详解 training data 数据结构: <br>[offset] [type] [value] [description] 0000 32 bit integer 0x00000803(2051) magic number 0004 32 bit integer 60000 number of images 0008 32 bit integer 28 number of rows 0012 32 bit integer 28 number of co
-
JSP 制作验证码的实例详解
JSP 制作验证码的实例详解 验证码 验证码(CAPTCHA)是"Completely Automated Public Turing test to tell Computers and Humans Apart"(全自动区分计算机和人类的图灵测试)的缩写,是一种区分用户是计算机还是人的公共全自动程序.可以防止:恶意破解密码.刷票.论坛灌水,有效防止某个黑客对某一个特定注册用户用特定程序暴力破解方式进行不断的登陆尝试,实际上用验证码是现在很多网站通行的方式,我们利用比较简易的方式实现
-
SpringBoot 集成Kaptcha实现验证码功能实例详解
在一个web应用中验证码是一个常见的元素.不管是防止机器人还是爬虫都有一定的作用,我们是自己编写生产验证码的工具类,也可以使用一些比较方便的验证码工具.在网上收集一些资料之后,今天给大家介绍一下kaptcha的和springboot一起使用的简单例子. 准备工作: 1.你要有一个springboot的hello world的工程,并能正常运行. 2.导入kaptcha的maven: <!-- https://mvnrepository.com/artifact/com.github.penggl
-
python 中xpath爬虫实例详解
案例一: 某套图网站,套图以封面形式展现在页面,需要依次点击套图,点击广告盘链接,最后到达百度网盘展示页面. 这一过程通过爬虫来实现,收集百度网盘地址和提取码,采用xpath爬虫技术 1.首先分析图片列表页,该页按照更新先后顺序暂时套图封面,查看HTML结构.每一组"li"对应一组套图.属性href后面即为套图的内页地址(即广告盘链接页).所以,我们先得获取列表页内所有的内页地址(即广告盘链接页) 代码如下: import requests 倒入requests库 from lxml
-
如何利用Python识别图片中的文字详解
一.Tesseract 文字识别是ORC的一部分内容,ORC的意思是光学字符识别,通俗讲就是文字识别.Tesseract是一个用于文字识别的工具,我们结合Python使用可以很快的实现文字识别.但是在此之前我们需要完成一个繁琐的工作. (1)Tesseract的安装及配置 Tesseract的安装我们可以移步到该网址 https://digi.bib.uni-mannheim.de/tesseract/,我们可以看到如下界面: 有很多版本供大家选择,大家可以根据自己的需求选择.其中w32表示32
-
Python操作xlwings的实例详解
目录 数据来源 上手 pandas读取表1-2的数据 xlwings获取表1-1sheet xlwings修改表1-1数据 总结 阿里云产品费用巡检,一般流程是登录账号,再逐项核对填写.虽然简单,但如果帐号多表格多,帐号间的数据有关联,填写起来就比较费力气.几张表格,可能从下载数据到核写完毕,辗转半个小时. 因此在保留excel原文件格式不变的基础上,自动填写相关数值变得重要. python操作excel的模块多,xlrd,pandas,xlwings,openpyxl.经常搞不清这么多功能类似
-
Android 通过网络图片路径查看图片实例详解
Android 通过网络图片路径查看图片实例详解 1.在项目清单中添加网络访问权限 <!--访问网络的权限--> <uses-permission android:name="android.permission.INTERNET"/> 2.获取网络图片数据 /** * 获取网络图片的数据 * @param path 网络图片路径 * @return * @throws Exception */ public static byte[] getImage(Str
-
python实现rsa加密实例详解
python实现rsa加密实例详解 一 代码 import rsa key = rsa.newkeys(3000)#生成随机秘钥 privateKey = key[1]#私钥 publicKey = key[0]#公钥 message ='sanxi Now is better than never.' print('Before encrypted:',message) message = message.encode() cryptedMessage = rsa.encrypt(messag