Pandas中Series的属性,方法,常用操作使用案例
目录
- 1. Series 对象的创建
- 1.1 创建一个空的 Series 对象
- 1.2 通过列表创建一个 Series 对象
- 1.3 通过元组创建一个 Series 对象
- 1.4 通过字典创建一个 Series 对象
- 1.5 通过 ndarray 创建一个 Series 对象
- 1.6 创建 Series 对象时指定索引
- 1.7 通过一个标量(数)创建一个 Series 对象
- 2. Series 的属性
- 2.1 values ---- 返回一个 ndarray 数组
- 2.2 index ---- 返回 Series 的索引序列
- 2.3 dtype ---- 返回 Series 中元素的数据类型
- 2. 4 size ---- 返回 Series 中元素的个数
- 2.5 ndim ---- 返回 Series 的维数
- 2.6 shape ---- 返回 Series 的维度
- 3. Series 的方法
- 3.1 mean() ---- 求算术平均数
- 3.2 min() max() ---- 求最值
- 3.3 argmax() argmin() idxmax() idxmin() ---- 获取最值索引
- 3.4 median() ---- 求中位数
- 3.5 value_counts() ---- 求频数
- 3.6 mode() ---- 求众数
- 3.7 quantile() ---- 求四分位数
- 3.8 std() ---- 标准差
- 3.9 describe() ---- 统计 Series 的常见统计学指标结果
- 3.10 sort_values() ---- 根据元素值进行排序
- 3.10.2 降序
- 3.11 sort_index() ---- 根据索引值进行排序
- 3.11.2 升序
- 3.11.2 降序
- 3.12 apply() ---- 根据传入的函数参数处理 Series 对象
- 3.13 head() ---- 查看 Series
- 3.14 tail() ---- 查看 Series 对象的后 x 个元素
- 4. Series 的常用操作
- 4.1 Series 对象的数据访问
- 4.1.1 使用数字索引进行访问
- 4.1.2 使用自定义标签索引进行访问
- 4.1.3 使用索引掩码进行访问
- 4.1.4 一次性访问多个元素
- 4.2 Series 对象数据元素的删除
- 4.2.1 pop()
- 4.2.2 drop()
- 4.3 Series 对象数据元素的修改
- 4.3.1 通过标签索引进行修改
- 4.3.2 通过数字索引进行修改
- 4.4 Series 对象数据元素的添加
- 4.4.1 通过标签索引添加
- 4.4.2 append()
包的引入:
import numpy as np import pandas as pd
1. Series 对象的创建
1.1 创建一个空的 Series 对象
s = pd.Series() print(s) print(type(s))

1.2 通过列表创建一个 Series 对象
需要传入一个列表序列
l = [1, 2, 3, 4]
s = pd.Series(l)
print(s)
print('-'*20)
print(type(s))

1.3 通过元组创建一个 Series 对象
需要传入一个元组序列
t = (1, 2, 3)
s = pd.Series(t)
print(s)
print('-'*20)
print(type(s))

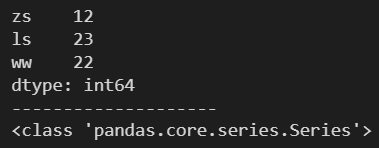
1.4 通过字典创建一个 Series 对象
需要传入一个字典
m = {'zs': 12, 'ls': 23, 'ww': 22}
s = pd.Series(m)
print(s)
print('-'*20)
print(type(s))
1.5 通过 ndarray 创建一个 Series 对象
需要传入一个 ndarray
ndarr = np.array([1, 2, 3])
s = pd.Series(ndarr)
print(s)
print('-'*20)
print(type(s))

1.6 创建 Series 对象时指定索引
index:用于设置 Series 对象的索引
age = [12, 23, 22, 34]
name = ['zs', 'ls', 'ww', 'zl']
s = pd.Series(age, index=name)
print(s)
print('-'*20)
print(type(s))

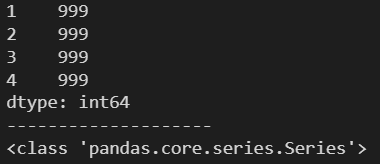
1.7 通过一个标量(数)创建一个 Series 对象
num = 999
s = pd.Series(num, index=[1, 2, 3, 4])
print(s)
print('-'*20)
print(type(s))
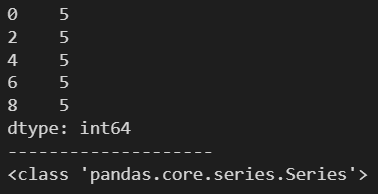
ndarr = np.arange(0, 10, 2)
s = pd.Series(5, index=ndarr)
print(s)
print('-'*20)
print(type(s))
2. Series 的属性
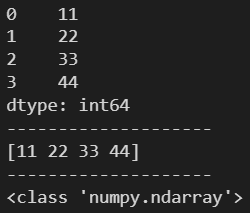
2.1 values ---- 返回一个 ndarray 数组
l = [11, 22, 33, 44]
s = pd.Series(l)
print(s)
print('-'*20)
ndarr = s.values
print(ndarr)
print('-'*20)
print(type(ndarr))
2.2 index ---- 返回 Series 的索引序列
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
idx = s.index
print(idx)
print('-'*20)
print(type(idx))
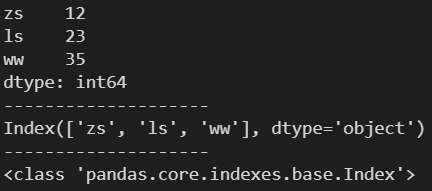
2.3 dtype ---- 返回 Series 中元素的数据类型
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
print(s.dtype)
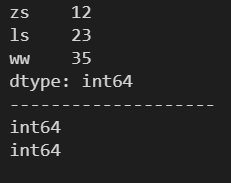
2. 4 size ---- 返回 Series 中元素的个数
d = {'zs': 12, 'ls': 23, 'ww': 35}
s = pd.Series(d)
print(s)
print('-'*20)
print(s.size)
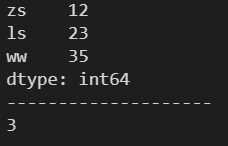
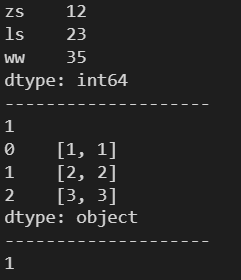
2.5 ndim ---- 返回 Series 的维数
d = {'zs': 12, 'ls': 23, 'ww': 35}
s1 = pd.Series(d)
print(s1)
print('-'*20)
print(s1.ndim)
l = [[1, 1], [2, 2], [3, 3]]
s2 = pd.Series(l)
print(s2)
print('-'*20)
print(s2.ndim)
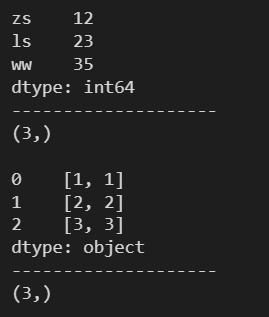
2.6 shape ---- 返回 Series 的维度
d = {'zs': 12, 'ls': 23, 'ww': 35}
s1 = pd.Series(d)
print(s1)
print('-'*20)
print(s1.shape)
print()
l = [[1, 1], [2, 2], [3, 3]]
s2 = pd.Series(l)
print(s2)
print('-'*20)
print(s2.shape)
3. Series 的方法
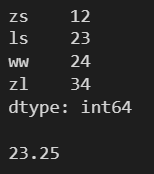
3.1 mean() ---- 求算术平均数
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s.mean())
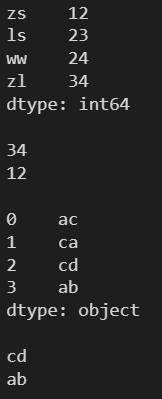
3.2 min() max() ---- 求最值
l1 = [12, 23, 24, 34] s1 = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s1) print() print(s1.max()) print(s1.min()) print() l2 = ['ac', 'ca', 'cd', 'ab'] s2 = pd.Series(l2) print(s2) print() print(s2.max()) print(s2.min())
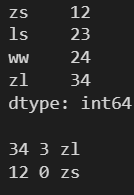
3.3 argmax() argmin() idxmax() idxmin() ---- 获取最值索引
l1 = [12, 23, 24, 34] s1 = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s1) print() # argmax() -- 最大值的数字索引 # idxmax() -- 最大值的标签索引 # 两个都不支持字符串类型的数据 print(s1.max(), s1.argmax(), s1.idxmax()) print(s1.min(), s1.argmin(), s1.idxmin())
3.4 median() ---- 求中位数
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s.median())

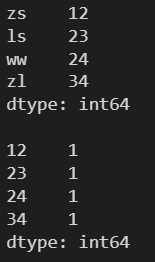
3.5 value_counts() ---- 求频数
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s.value_counts())
3.6 mode() ---- 求众数
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s.mode()) print() l = [12, 23, 24, 34, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl', 'zq']) print(s) print() print(s.mode())

3.7 quantile() ---- 求四分位数
四分位数:把数值从小到大排列并分成四等分,处于三个分割点位置的数值就是四分位数。
需要传入一个列表,列表中的元素为要获取的数的对应位置
l = [1, 1, 2, 2, 3, 3, 4, 4] s = pd.Series(l) print(s) print() print(s.quantile([0, .25, .50, .75, 1]))

3.8 std() ---- 标准差
总体标准差是反映研究总体内个体之间差异程度的一种统计指标。
总体标准差计算公式:

由于总体标准差计算出来会偏小,所以采用 ( n − d d o f ) (n-ddof) (n−ddof)的方式适当扩大标准差,即样本标准差。
样本标准差计算公式:

l = [1, 1, 2, 2, 3, 3, 4, 4] s = pd.Series(l) print(s) print() # 总体标准差 print(s.std()) print() print(s.std(ddof=1)) print() # 样本标准差 print(s.std(ddof=2))

3.9 describe() ---- 统计 Series 的常见统计学指标结果
l = [1, 1, 2, 2, 3, 3, 4, 4] s = pd.Series(l) print(s) print() print(s.describe())

3.10 sort_values() ---- 根据元素值进行排序
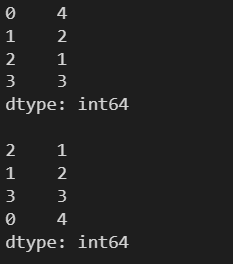
ascending:True为升序(默认),False为降序 3.10.1 升序
l = [4, 2, 1, 3] s = pd.Series(l) print(s) print() s = s.sort_values() print(s)
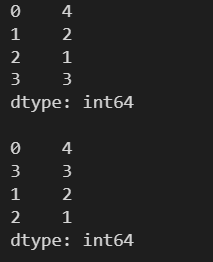
3.10.2 降序
l = [4, 2, 1, 3] s = pd.Series(l) print(s) print() s = s.sort_values(ascending=False) print(s)
3.11 sort_index() ---- 根据索引值进行排序
ascending:True为升序(默认),False为降序
3.11.2 升序
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s = s.sort_index() print(s)

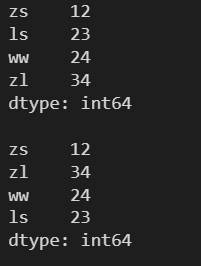
3.11.2 降序
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s = s.sort_index() print(s)
3.12 apply() ---- 根据传入的函数参数处理 Series 对象
需要传入一个函数参数
# x 为当前遍历到的元素 def func(x): if (x%2==0): return x+1 else: return x l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # 调用 apply 方法,会将 Series 中的每个元素带入 func 函数中进行处理 s = s.apply(func) print(s)
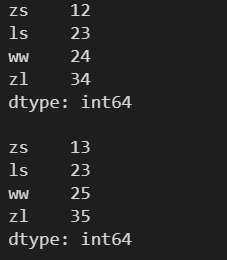
3.13 head() ---- 查看 Series
对象的前 x 个元素 需要传入一个数 x ,表示查看前 x 个元素,默认为前5个
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # head(x) 查看 Series 对象的前 x 个元素 print(s.head(2))
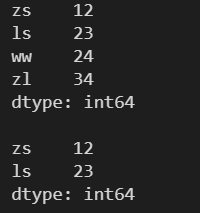
3.14 tail() ---- 查看 Series 对象的后 x 个元素
需要传入一个数 x ,表示查看后 x 个元素,默认为后5个
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # tail(x) 查看 Series 对象的后 x 个元素 print(s.tail(2))
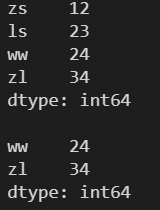
4. Series 的常用操作
4.1 Series 对象的数据访问
4.1.1 使用数字索引进行访问
4.1.1.1 未自定义索引
l = [12, 23, 24, 34] s = pd.Series(l) print(s) print() print(s[0]) print() print(s[1:-2]) print() print(s[::2]) print() print(s[::-1])

4.1.1.2 自定义索引
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s[0]) print() print(s[1:-2]) print() print(s[::2]) print() print(s[::-1])
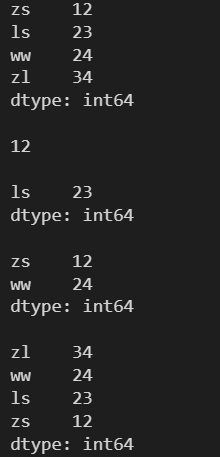
4.1.2 使用自定义标签索引进行访问
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() print(s['zs']) print() # 自定义标签索引进行切片包含开始与结束位置 print(s['ls':'zl']) print() print(s['zs':'zl':2]) print() # 注意切边范围的方向与步长的方向 print(s['zl':'zs':-1])
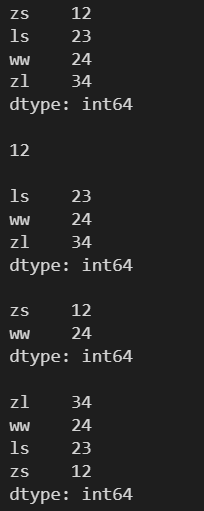
4.1.3 使用索引掩码进行访问
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() idx = (s%2==0) print(idx) print() # 索引掩码(也是一个数组) # 索引掩码个数与原数组的个数一致,数组每个元素都与索引掩码中的元素一一对应 # 数组每个元素都对应着索引掩码中的一个True或False # 只有索引掩码中为True所对应元素组中的元素才会被选中 print(s[idx])
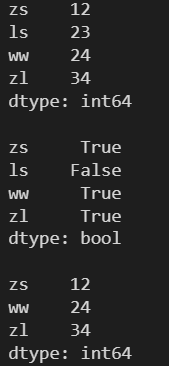
4.1.4 一次性访问多个元素
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # 选出指定索引对应的元素 print(s[['zs', 'ww']]) print() print(s[[1, 2]])
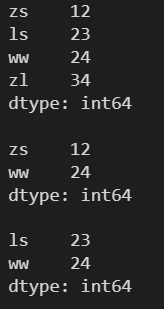
4.2 Series 对象数据元素的删除
4.2.1 pop()
传入要删除元素的标签索引
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
s.pop('ww')
print(s)
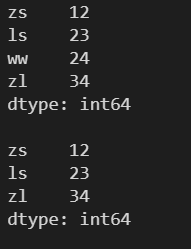
4.2.2 drop()
传入要删除元素的标签索引
l = [12, 23, 24, 34]
s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl'])
print(s)
print()
# drop() 会返回一个删除元素后的新数组,不会对原数组进行修改
s = s.drop('zs')
print(s)
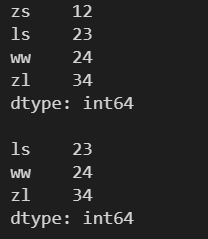
4.3 Series 对象数据元素的修改
4.3.1 通过标签索引进行修改
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s['zs'] = 22 print(s)
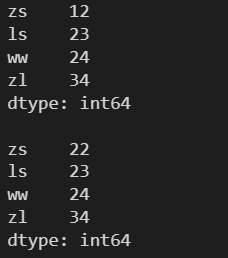
4.3.2 通过数字索引进行修改
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s[1] = 22 print(s)
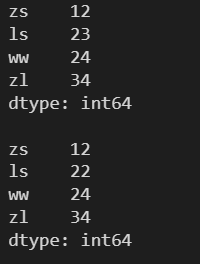
4.4 Series 对象数据元素的添加
4.4.1 通过标签索引添加
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() s['ll'] = 22 print(s)
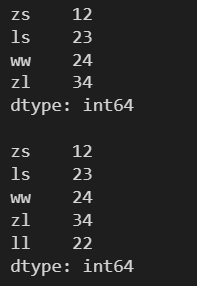
4.4.2 append()
需要传入一个要添加到原 Series 对象的 Series 对象
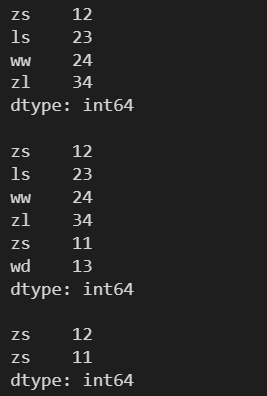
l = [12, 23, 24, 34] s = pd.Series(l, index=['zs', 'ls', 'ww', 'zl']) print(s) print() # 可以添加已经存在的索引及其值 s2 = pd.Series([11, 13], index=['zs', 'wd']) # append() 不会对原数组进行修改 s = s.append(s2) print(s) print() print(s['zs'])
到此这篇关于Pandas中Series的属性,方法,常用操作使用案例的文章就介绍到这了,更多相关Pandas中Series属性内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
pandas中的series数据类型详解
本文介绍了pandas中的series数据类型详解,分享给大家,具体如下: import pandas as pd import numpy as np import names ''' 写在前面的话: 1.series与array类型的不同之处为series有索引,而另一个没有;series中的数据必须是一维的,而array类型不一定 2.可以把series看成一个定长的有序字典,可以通过shape,index,values等得到series的属性 ''' # 1.series的创建 '''
-
浅谈Pandas Series 和 Numpy array中的相同点
相同点: 可以利用中括号获取元素 s[0] 可以的得到单个元素 或 一个元素切片 s[3,7] 可以遍历 for x in s 可以调用同样的函数获取最大最小值 s.mean() s.max() 可以用向量运算 <1 + s> 和Numpy一样, Pandas Series 也是用C语言, 因此它比Python列表的运算更快 以上这篇浅谈Pandas Series 和 Numpy array中的相同点就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们.
-

pandas的Series类型与基本操作详解
1 Series 线性的数据结构, series是一个一维数组 Pandas 会默然用0到n-1来作为series的index, 但也可以自己指定index( 可以把index理解为dict里面的key ) 1.1创造一个serise数据 import pandas as pd import numpy as np s = pd.Series([9, 'zheng', 'beijing', 128]) print(s) 打印 0 9 1 zheng 2 beijing 3 128 dtype
-
Pandas把dataframe或series转换成list的方法
把dataframe转换为list 输入多维dataframe: df = pd.DataFrame({'a':[1,3,5,7,4,5,6,4,7,8,9], 'b':[3,5,6,2,4,6,7,8,7,8,9]}) 把a列的元素转换成list: # 方法1df['a'].values.tolist() # 方法2df['a'].tolist() 把a列中不重复的元素转换成list: df['a'].drop_duplicates().values.tolist() 输入一维datafram
-
教你漂亮打印Pandas DataFrames和Series
一.前言 当我们必须处理可能有多个列和行的大型DataFrames时,能够以可读格式显示数据是很重要的.这在调试代码时非常有用. 默认情况下,当打印出DataFrame且具有相当多的列时,仅列的子集显示到标准输出. 显示的列甚至可以多行打印出来. 二.问题 假设我们有以下DataFrame: import pandas as pd import numpy as np df = pd.DataFrame( np.random.randint(0, 100, size=(100, 25)), co
-
Pandas数据结构详细说明及如何创建Series,DataFrame对象方法
目录 1. Pandas的两种数据类型 2. Series类型 通过numpy array 通过Python字典 通过标量值(Scalar) name属性 3. DataFrame类型 通过包含列表的Python List 通过包含Python 字典的Python List 通过Series 在网络上的Pandas教程中,很多都提到了如何使用Pandas将已有的数据(如csv,如hdfs等)直接加载成Pandas数据对象,然后在其基础上进行数据分析操作,但是,很多时候,我们需要自己创建Panda
-
Python数据分析 Pandas Series对象操作
目录 一.Pandas Series对象 Series数据结构 创建Series对象 二.Series对象的基本操作 Series 常用属性 Series 常用方法 Series 运算 一.Pandas Series对象 Pandas 是基于 NumPy 设计实现的 Python 数据分析库,Pandas 提供了大量的能让我们高效处理数据的函数和方法,也纳入了很多数据处理的库以及一些数据模型,可以说非常强大. 可以使用以下命令进行安装: conda install pandas # 或 pip
-
使用python计算方差方式——pandas.series.std()
目录 如何计算方差 Python计算方差.标准差 方差.标准差 1.方差 2.标准差 如何计算方差 简单展示一下pandas里怎么计算方差: 官方文档: def def_std(df): for ix,row in df.iterrows(): std = row.std() df.loc[ix,"std"] = std return df Python计算方差.标准差 方差.标准差 1.离散程度的测度值之一 2.最常用的测度值 3.反应了数据的分布 4.反应了
-
Pandas中Series的属性,方法,常用操作使用案例
目录 1. Series 对象的创建 1.1 创建一个空的 Series 对象 1.2 通过列表创建一个 Series 对象 1.3 通过元组创建一个 Series 对象 1.4 通过字典创建一个 Series 对象 1.5 通过 ndarray 创建一个 Series 对象 1.6 创建 Series 对象时指定索引 1.7 通过一个标量(数)创建一个 Series 对象 2. Series 的属性 2.1 values ---- 返回一个 ndarray 数组 2.2 index ----
-
javascript中对Date类型的常用操作小结
javascript中对Date类型的常用操作小结 /** 3. * 日期时间脚本库方法列表: 4. * (1)Date.isValiDate:日期合法性验证 5. * (2)Date.isValiTime:时间合法性验证 6. * (3)Date.isValiDateTime:日期和时间合法性验证 7. * (4)Date.prototype.isLeapYear:判断是否闰年 8. * (5)Date.prototype.format:日期格式化 9. * (6)Date.stringToD
-
Java中对List集合的常用操作详解
目录: 1.list中添加,获取,删除元素: 2.list中是否包含某个元素: 3.list中根据索引将元素数值改变(替换): 4.list中查看(判断)元素的索引: 5.根据元素索引位置进行的判断: 6.利用list中索引位置重新生成一个新的list(截取集合): 7.对比两个list中的所有元素: 8.判断list是否为空: 9.返回Iterator集合对象: 10.将集合转换为字符串: 11.将集合转换为数组: 12.集合类型转换: 备注:内容中代码具有关联性. 1.list中添加,获取,
-
浅谈pandas中Dataframe的查询方法([], loc, iloc, at, iat, ix)
pandas为我们提供了多种切片方法,而要是不太了解这些方法,就会经常容易混淆.下面举例对这些切片方法进行说明. 数据介绍 先随机生成一组数据: In [5]: rnd_1 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_2 = [random.randrange(1,20) for x in xrange(1000)] ...: rnd_3 = [random.randrange(1,20) for x in xrange(1
-
对pandas中Series的map函数详解
Series的map方法可以接受一个函数或含有映射关系的字典型对象. 使用map是一种实现元素级转换以及其他数据清理工作的便捷方式. (DataFrame中对应的是applymap()函数,当然DataFrame还有apply()函数) 1.字典映射 import pandas as pd from pandas import Series, DataFrame data = DataFrame({'food':['bacon','pulled pork','bacon','Pastrami',
-
pandas中apply和transform方法的性能比较及区别介绍
1. apply与transform 首先讲一下apply() 与transform()的相同点与不同点 相同点: 都能针对dataframe完成特征的计算,并且常常与groupby()方法一起使用. 不同点: apply()里面可以跟自定义的函数,包括简单的求和函数以及复杂的特征间的差值函数等(注:apply不能直接使用agg()方法 / transform()中的python内置函数,例如sum.max.min.'count'等方法) transform() 里面不能跟自定义的特征交互函数,
-
Python中静态方法,类方法,属性方法使用方法
目录 1.静态方法 2.类方法 3.静态方法与类方法总结 4.属性方法 1.静态方法 通过@staticmethod装饰器即可把其装饰的方法变为一个静态方法,什么是静态方法呢?其实不难理解,普通的方法,可以在实例化后直接调用,并且在方法里可以通过self.调用实例变量或类变量,但静态方法是不可以访问实例变量或类变量的,一个不能访问实例变量和类变量的方法,其实相当于跟类本身已经没什么关系了,它与类唯一的关联就是需要通过类名来调用这个方法 应用: 对与一个类,我们要调用它的一个方法,必须要绑定实例,
-
Pandas中Series的创建及数据类型转换
目录 一.实战场景 二.主要知识点 三.菜鸟实战 1.创建 python 文件,用Numpy创建Series 2.转换Series的数据类型 四.补充 1.创建 python 文件,数据list,变成Pandas的Series对象 2.数据dict变成Pandas的Series对象 3.把Pandas的Series对象变成数据list 一.实战场景 实战场景:Pandas中Series的创建和数据类型转换,Series的创建和数据类型转换,Series 类似于一维数组与字典(map)数据结构的结
-
jquery遍历标签中自定义的属性方法
在开发中我们有时会对html标签添加属性,如何遍历处理? <ul> <li name="li1" sortid="nav_1">aaaaaaa</li> <li name="li1" sortid="nav_2">bbbbbbb</li> <li name="li1" sortid="nav_3">cccccccc&
-
iOS开发中UIImageView控件的常用操作整理
UIImageView,顾名思义,是用来放置图片的.使用Interface Builder设计界面时,当然可以直接将控件拖进去并设置相关属性,这就不说了,这里讲的是用代码. 1.创建一个UIImageView: 创建一个UIImageView对象有五种方法: 复制代码 代码如下: UIImageView *imageView1 = [[UIImageView alloc] init]; UIImageView *imageView2 = [[UIImageView alloc] initWith