mysql如何取分组之后最新的数据
目录
- 一、数据表设计
- 二、查询场景
- 1、统计没门课的考试次数
- 2、最新一次考试的时间
- 3、分组统计最新的录入成绩的老师
- 总结
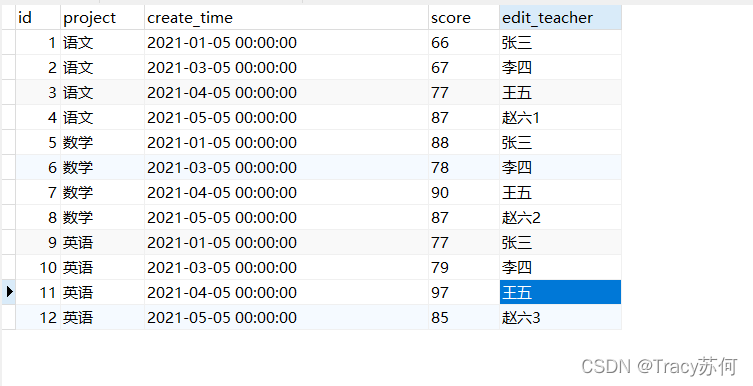
一、数据表设计
二、查询场景
统计每门课的考试次数、最新一次考试的时间、最新一次考试的录入成绩的老师
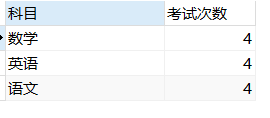
1、统计没门课的考试次数
#考试次数统计 select project '科目',count(project) '考试次数' from score a group by project
查询结果:
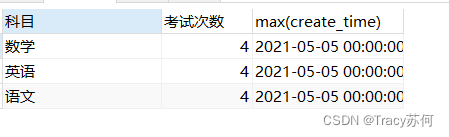
2、最新一次考试的时间
#考试次数统计 最新一次考试的时间 select project '科目',count(project) '考试次数' ,max(create_time) from score a group by project
查询结果:
3、分组统计最新的录入成绩的老师
当我们分组去查询最新的录入成绩的老师或者分组查询最新一次各科的成绩时确发现数据不是最新的。
SELECT a.id, a.edit_teacher, a.project, a.create_time, a.score, count(project) '考试次数', max(create_time) '最新数据时间' FROM score a GROUP BY a.project
查询结果:

但是很显然我们需要查询的数据id应该是4、8、12

可以看出分组聚合的时候默认查询的是分组之后的第一条数据,那么我们想要查询最新的数据需要新对我们的数据进行排序
SELECT *, count( project ) '考试次数', max(create_time) '最新数据时间' FROM ( SELECT a.id, a.edit_teacher, a.project, a.create_time, a.score FROM score a ORDER BY a.id DESC ) b GROUP BY b.project
查询结果:

我们发现数据并不是我们想要的结果,子查询里面的排序失效了
网上查找各种资料发现
子查询生成的临时表(派生表derived table)中使用order by且使其生效,必须满足三个条件:
1、外部查询禁止分组或者聚合
2、外部查询未指定having,HAVING, order by
3、外部查询将派生表或者视图作为from句中唯一指定源
显然我们没有满足,那么如何解决order by失效呢?
我们外部表使用了group by,那么临时表将不会执行filesort操作(即order by会被忽略),所以我们可以在临时表中加上(distinct(a.id))。
SELECT *, count( project ) '考试次数' , max(create_time) '最新数据时间' FROM ( SELECT DISTINCT a.id, a.edit_teacher, a.project, a.create_time, a.score FROM score a ORDER BY a.id DESC ) b GROUP BY b.project
执行结果:

结果正确。
总结
到此这篇关于mysql如何取分组之后最新的数据的文章就介绍到这了,更多相关mysql取分组最新数据内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL数据库分组查询group by语句详解
一:分组函数的语句顺序 1 SELECT ... 2 FROM ... 3 WHERE ... 4 GROUP BY ... 5 HAVING ... 6 ORDER BY ... 二:WHERE和HAVING筛选条件的区别 数据源 位置 关键字 WHERE 原始表 ORDER BY语句之前 WHERE HAVING 分组后的结果集 ORDER BY语句之后 HAVING 三:举例说明 #1.查询每个班学生的最大年龄 SELECT MAX(age),class FROM STU_CLASS GR
-
基于mysql实现group by取各分组最新一条数据
前言: group by函数后取到的是分组中的第一条数据,但是我们有时候需要取出各分组的最新一条,该怎么实现呢? 本文提供两种实现方式. 一.准备数据 http://note.youdao.com/noteshare?id=dba748092a619be0a8f160ccf6e25a5f&sub=FD4C1C7823CA440DB360FEA3B4A905CD 二.三种实现方式 1)先order by之后再分组: SELECT * FROM (SELECT * from tb_dept ORDE
-
MySql分组后随机获取每组一条数据的操作
思路:先随机排序然后再分组就好了. 1.创建表: CREATE TABLE `xdx_test` ( `id` int(11) NOT NULL, `name` varchar(255) DEFAULT NULL, `class` varchar(255) DEFAULT NULL, PRIMARY KEY (`id`) ) ENGINE=InnoDB DEFAULT CHARSET=utf8mb4; 2.插入数据 INSERT INTO xdx_test VALUES (1, '张三-1','
-

详解MySQL 数据分组
创建分组 分组是在SELECT语句中的GROUP BY 子句中建立的. 例: SELECT vend_id, COUNT(*) AS num_prods FROM products GROUP BY vend_id; GROUP BY GROUP BY子句可以包含任意数目的列,这使得能对分组进行嵌套,为数据分组提供更细致的控制. 如果在GROUP BY子句中嵌套了分组,数据将在最后规定的分组商家进行汇总.换句话说,在建立分组时,指定的所有列都一起计算.(所有不能从个别的列取回数据). GROUP
-
mysql 数据汇总与分组
我们经常需要汇总数据而不用把它们实际检索出来,为此MySQL提供了专门的函数.使用这些函数,MySQL查询可用于检索数据,以便分析和报表生成. 这种类型的检索例子有以下几种: 确定表中行数(或者满足某个条件或包含某个特定值的行数). 获得表中行组的和. 找出表列(或所有行或某些特定的行)的最大值.最小值和平均值 如: AVG() 返回某列的平均值 COUNT() 返回某列的行数 MAX() 返回某列的最大值 MIN() 返回某列的最小值 SUM() 返回某列值之和 举个例子: select AV
-
mysql如何取分组之后最新的数据
目录 一.数据表设计 二.查询场景 1.统计没门课的考试次数 2.最新一次考试的时间 3.分组统计最新的录入成绩的老师 总结 一.数据表设计 二.查询场景 统计每门课的考试次数.最新一次考试的时间.最新一次考试的录入成绩的老师 1.统计没门课的考试次数 #考试次数统计 select project '科目',count(project) '考试次数' from score a group by project 查询结果: 2.最新一次考试的时间 #考试次数统计 最新一次考试的时间 select
-
pyodps中的apply用法及groupby取分组排序第一条数据
目录 1.apply用法 2.取分组排序后的第一条数据 1.apply用法 apply在pandas里非常好用的,那在pyodps里如何去使用,还是有一些区别的,在pyodps中要对一行数据使用自定义函数,可以使用 apply 方法,axis 参数必须为 1,表示在行上操作. apply 的自定义函数接收一个参数,为上一步 Collection 的一行数据,用户可以通过属性.或者偏移取得一个字段的数据. iris.apply(lambda row: row.sepallength + row.s
-
MySql 查询符合条件的最新数据行
目录 平时做业务,经常是需要查什么什么什么的最新的一条数据. 那至于最新这个概念, 对于产品来说,经常会说的是 时间顺序,最新也就是 最近的意思. 结合示例: 这是一张记录人员来访的记录表.数据表里的数据准确记录了每个人来访时带的帽子颜色.时间.人员编码(每个人唯一). 数据样例: 需要做到的是 : 拿出符合条件的最新的来访记录. 你会最怎么做? 先实现一点的, 取出 A101 这个人员编码的 最新来访记录 . 首先先展示错误的sql示例: 想当然地使用max() 函数. SELECT MAX(
-
Python爬取腾讯疫情实时数据并存储到mysql数据库的示例代码
思路: 在腾讯疫情数据网站F12解析网站结构,使用Python爬取当日疫情数据和历史疫情数据,分别存储到details和history两个mysql表. ①此方法用于爬取每日详细疫情数据 import requests import json import time def get_details(): url = 'https://view.inews.qq.com/g2/getOnsInfo?name=disease_h5&callback=jQuery3410284820553141302
-
oracle取数据库中最新的一条数据可能会遇到的bug(两种情况)
记一次 开发中遇到的坑: 第一种情况 rowid select * from table where rowid=(select max(rowid) from table ) 这种方式是取最大的rowid作为最新的数据,但是有一个隐患 :数据库一旦有删除操作,rowid不能保证每次都是递增的!即max(rowid)并不一定就是最新的数据,尽管可能不会每次复现 但这个问题是绝对存在的! 第二种情况 使用rownum (或相同思路) select t.* from (select ti.sysno
-
Oracle结合Mybatis实现取表TOP 10条数据
之前一直使用mysql和informix数据库,查表中前10条数据十分简单: 最原始版本: select top * from student 当然,我们还可以写的复杂一点,比如外加一些查询条件? 比如查询前10条成绩大于80分的学生信息 添加了where查询条件的版本: select top * from table where score > 80 但是!!oracle中没有top啊!!!!那么该如何实现呢? 嗯,可以用rownum! oracle中原始版本 select * from st
-
python爬取安居客二手房网站数据(实例讲解)
是小打小闹 哈哈,现在开始正式进行爬虫书写首先,需要分析一下要爬取的网站的结构:作为一名河南的学生,那就看看郑州的二手房信息吧! 在上面这个页面中,我们可以看到一条条的房源信息,从中我们发现了什么,发现了连郑州的二手房都是这么的贵,作为即将毕业的学生狗惹不起啊惹不起 还是正文吧!!!由上可以看到网页一条条的房源信息,点击进去后就会发现: 房源的详细信息.OK!那么我们要干嘛呢,就是把郑州这个地区的二手房房源信息都能拿到手,可以保存到数据库中,用来干嘛呢,作为一个地理人,还是有点用处的,这次就不说
-
mysql 5.7.17的最新安装教程图文详解
mysql-5.7.17-winx64是现在最新版本的Mysql,这是免安装的,所以要进行些配置 下载地址:https://cdn.mysql.com//Downloads/MySQL-5.7/mysql-5.7.17-winx64.zip 1:下载安装包,将其解压到一个文件夹下 2:复制my-default.ini,并重命名为my.ini,然后用记事本打开输入mysql的基本配置: [mysql] ; 设置mysql客户端默认字符集 default-character-set=utf8 [my
-
mysql按照天统计报表当天没有数据填0的实现代码
1.问题复现: 按照天数统计每天的总数,如果其中有几天没有数据,那么group by 返回会忽略那几天,如何填充0?如下图,统计的10-3~10-10 7天的数据,其中只有8号和10号有数据,这样返回,数据只有2个,不符合报表统计的需求.期望没有值填0 2.换个思维: 我们用一组连续的天数作为左表然后left join 要查询的数据 最后group by.:连续天数表 t1 left join 业务数据 t2 group by t1.day ,如下图: SELECT t1.`day`, COU
-
PHP+MySQL实现对一段时间内每天数据统计优化操作实例
本文实例讲述了PHP+MySQL实现对一段时间内每天数据统计优化操作.分享给大家供大家参考,具体如下: 在互联网项目中,对项目的数据分析必不可少.通常会统计某一段时间内每天数据总计变化趋势调整营销策略.下面来看以下案例. 案例 在电商平台中通常会有订单表,记录所有订单信息.现在我们需要统计某个月份每天订单数及销售金额数据从而绘制出如下统计图,进行数据分析. 订单表数据结构如下: order_id order_sn total_price enterdate 25396 A4E610E250C2D