线程崩溃不会导致 JVM 崩溃的原因解析
目录
- 线程崩溃,进程一定会崩溃吗
- 进程是如何崩溃的-信号机制简介
- 为什么线程崩溃不会导致 JVM 进程崩溃
- openJDK 源码解析
- 总结
- 参考文章
网上看到一个很有意思的据说是美团的面试题:为什么线程崩溃崩溃不会导致 JVM 崩溃,这个问题我看了不少回答,但都没答到根本原因,所以决定答一答,相信大家看完肯定会有收获,本文分以下几节来探讨
- 线程崩溃,进程一定会崩溃吗
- 进程是如何崩溃的-信号机制简介
- 为什么在 JVM 中线程崩溃不会导致 JVM 进程崩溃
openJDK 源码解析
线程崩溃,进程一定会崩溃吗
一般来说如果线程是因为非法访问内存引起的崩溃,那么进程肯定会崩溃,为什么系统要让进程崩溃呢,这主要是因为在进程中,各个线程的地址空间是共享的,既然是共享,那么某个线程对地址的非法访问就会导致内存的不确定性,进而可能会影响到其他线程,这种操作是危险的,操作系统会认为这很可能导致一系列严重的后果,于是干脆让整个进程崩溃

线程共享代码段,数据段,地址空间,文件
非法访问内存有以下几种情况,我们以 C 语言举例来看看
1.针对只读内存写入数据
#include <stdio.h>
#include <stdlib.h>
int main() {
char *s = "hello world";
s[1] = 'H'; // 向只读内存写入数据,崩溃
}
2.针对没有权限的内存非法操作
#include <stdio.h>
#include <stdlib.h>
int main() {
int *p = (int *)0xC0000fff;
*p = 10; // 针对进程没有写权限的内核空间写入数据,崩溃
}
在 32 位虚拟地址空间中,p 指向的是内核空间,显然不具有写入权限,所以上述赋值操作会导致崩溃
3.访问了不存在的内存,比如
#include <stdio.h>
#include <stdlib.h>
int main() {
int *a = NULL;
*a = 1; // 访问了不存在的内存
}
以上错误都是访问内存时的错误,所以统一会报 Segment Fault 错误(即段错误),这些都会导致进程崩溃
进程是如何崩溃的-信号机制简介
那么线程崩溃后,进程是如何崩溃的呢,这背后的机制到底是怎样的,答案是信号,大家想想要干掉一个正在运行的进程是不是经常用 kill -9 pid 这样的命令,这里的 kill 其实就是给指定 pid 发送终止信号的意思,其中的 9 就是信号,其实信号有很多类型的,在 Linux 中可以通过 kill -l查看所有可用的信号

当然了发 kill 信号必须具有一定的权限,否则任意进程都可以通过发信号来终止其他进程,那显然是不合理的,实际上 kill 执行的是系统调用,将控制权转移给了内核(操作系统),由内核来给指定的进程发送信号
那么发个信号进程怎么就崩溃了呢,这背后的原理到底是怎样的?
其背后的机制如下
- CPU 执行正常的进程指令
- 调用 kill 系统调用向进程发送信号
- 进程收到操作系统发的信号,CPU 暂停当前程序运行,并将控制权转交给操作系统
- 调用 kill 系统调用向进程发送信号(假设为 11,即 SIGSEGV,一般非法访问内存报的都是这个错误)
- 操作系统根据情况执行相应的信号处理程序(函数),一般执行完信号处理程序逻辑后会让进程退出
注意上面的第五步,如果进程没有注册自己的信号处理函数,那么操作系统会执行默认的信号处理程序(一般最后会让进程退出),但如果注册了,则会执行自己的信号处理函数,这样的话就给了进程一个垂死挣扎的机会,它收到 kill 信号后,可以调用 exit() 来退出,但也可以使用 sigsetjmp,siglongjmp 这两个函数来恢复进程的执行
// 自定义信号处理函数示例
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
// 自定义信号处理函数,处理自定义逻辑后再调用 exit 退出
void sigHandler(int sig) {
printf("Signal %d catched!\n", sig);
exit(sig);
}
int main(void) {
signal(SIGSEGV, sigHandler);
int *p = (int *)0xC0000fff;
*p = 10; // 针对不属于进程的内核空间写入数据,崩溃
}
// 以上结果输出: Signal 11 catched!
如代码所示:注册信号处理函数后,当收到 SIGSEGV 信号后,先执行相关的逻辑再退出
另外当进程接收信号之后也可以不定义自己的信号处理函数,而是选择忽略信号,如下
#include <stdio.h>
#include <signal.h>
#include <stdlib.h>
int main(void) {
// 忽略信号
signal(SIGSEGV, SIG_IGN);
// 产生一个 SIGSEGV 信号
raise(SIGSEGV);
printf("正常结束");
}
也就是说虽然给进程发送了 kill 信号,但如果进程自己定义了信号处理函数或者无视信号就有机会逃出生天,当然了 kill -9 命令例外,不管进程是否定义了信号处理函数,都会马上被干掉
说到这大家是否想起了一道经典面试题:如何让正在运行的 Java 工程的优雅停机,通过上面的介绍大家不难发现,其实是 JVM 自己定义了信号处理函数,这样当发送 kill pid 命令(默认会传 15 也就是 SIGTERM)后,JVM 就可以在信号处理函数中执行一些资源清理之后再调用 exit 退出。这种场景显然不能用 kill -9,不然一下把进程干掉了资源就来不及清除了
为什么线程崩溃不会导致 JVM 进程崩溃
现在我们再来看看开头这个问题,相信你多少会心中有数,想想看在 Java 中有哪些是觉见的由于非法访问内存而产生的 Exception 或 error 呢,常见的是大家熟悉的 StackoverflowError 或者 NPE(NullPointerException),NPE 我们都了解,属于是访问了不存在的内存
但为什么栈溢出(Stackoverflow)也属于非法访问内存呢,这得简单聊一下进程的虚拟空间,也就是前面提到的共享地址空间
现代操作系统为了保护进程之间不受影响,所以使用了虚拟地址空间来隔离进程,进程的寻址都是针对虚拟地址,每个进程的虚拟空间都是一样的,而线程会共用进程的地址空间,以 32 位虚拟空间,进程的虚拟空间分布如下

那么 stackoverflow 是怎么发生的呢,进程每调用一个函数,都会分配一个栈桢,然后在栈桢里会分配函数里定义的各种局部变量,假设现在调用了一个无限递归的函数,那就会持续分配栈帧,但 stack 的大小是有限的(Linux 中默认为 8 M,可以通过 ulimit -a 查看),如果无限递归显然很快栈就会分配完了,此时再调用函数试图分配超出栈的大小内存,就会发生段错误,也就是 stackoverflowError
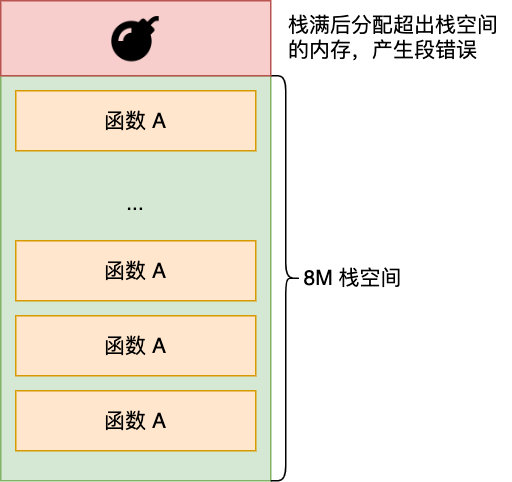
好了,现在我们知道了 StackoverflowError 怎么产生的,那问题来了,既然 StackoverflowError 或者 NPE 都属于非法访问内存, JVM 为什么不会崩溃呢,有了上一节的铺垫,相信你不难回答,其实就是因为 JVM 自定义了自己的信号处理函数,拦截了 SIGSEGV 信号,针对这两者不让它们崩溃,怎么证明这个推测呢,我们来看下 JVM 的源码来一探究竟
openJDK 源码解析
HotSpot 虚拟机目前使用范围最广的 Java 虚拟机,据 R 大所述, Oracle JDK 与 OpenJDK 里的 JVM 都是 HotSpot VM,从源码层面说,两者基本上是同一个东西,OpenJDK 是开源的,所以我们主要研究下 Java 8 的 OpenJDK 即可,地址如下:https://github.com/AdoptOpenJDK/openjdk-jdk8u,有兴趣的可以下载来看看
我们就是研究 Linux 下的 JVM,为了便于说明,也方便大家查阅,我把其中关于信号处理的关键流程整理了下(忽略其中的次要代码)

可以看到,在启动 JVM 的时候,也设置了信号处理函数,收到 SIGSEGV,SIGPIPE 等信号后最终会调用 JVM_handle_linux_signal 这个自定义信号处理函数,再来看下这个函数的主要逻辑
JVM_handle_linux_signal(int sig,
siginfo_t* info,
void* ucVoid,
int abort_if_unrecognized) {
// Must do this before SignalHandlerMark, if crash protection installed we will longjmp away
// 这段代码里会调用 siglongjmp,主要做线程恢复之用
os::ThreadCrashProtection::check_crash_protection(sig, t);
if (info != NULL && uc != NULL && thread != NULL) {
pc = (address) os::Linux::ucontext_get_pc(uc);
// Handle ALL stack overflow variations here
if (sig == SIGSEGV) {
// Si_addr may not be valid due to a bug in the linux-ppc64 kernel (see
// comment below). Use get_stack_bang_address instead of si_addr.
address addr = ((NativeInstruction*)pc)->get_stack_bang_address(uc);
// 判断是否栈溢出了
if (addr < thread->stack_base() &&
addr >= thread->stack_base() - thread->stack_size()) {
if (thread->thread_state() == _thread_in_Java) {
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::STACK_OVERFLOW);
}
}
}
}
if (sig == SIGSEGV &&
!MacroAssembler::needs_explicit_null_check((intptr_t)info->si_addr)) {
// 此处会做空指针检查
stub = SharedRuntime::continuation_for_implicit_exception(thread, pc, SharedRuntime::IMPLICIT_NULL);
}
// 如果是栈溢出或者空指针最终会返回 true,不会走最后的 report_and_die,所以 JVM 不会退出
if (stub != NULL) {
// save all thread context in case we need to restore it
if (thread != NULL) thread->set_saved_exception_pc(pc);
uc->uc_mcontext.gregs[REG_PC] = (greg_t)stub;
// 返回 true 代表 JVM 进程不会退出
return true;
}
VMError err(t, sig, pc, info, ucVoid);
// 生成 hs_err_pid_xxx.log 文件并退出
err.report_and_die();
ShouldNotReachHere();
return true; // Mute compiler
}
从以上代码我们可以知道以下信息
- 发生 stackoverflow 还有空指针错误,确实都发送了 SIGSEGV,只是虚拟机不选择退出,而是自己内部作了额外的处理,其实是恢复了线程的执行,并抛出 StackoverflowError 和 NPE,这就是为什么 JVM 不会崩溃且我们能捕获这两个错误/异常的原因
- 如果针对 SIGSEGV 等信号,在以上的函数中 JVM 没有做额外的处理,那么最终会走到 report_and_die 这个方法,这个方法主要做的事情是生成 hs_err_pid_xxx.log crash 文件(记录了一些堆栈信息或错误),然后退出
自此我相信大家已经明白了为什么发生了 StackoverflowError 和 NPE 这两个非法访问内存的错误,JVM 却没有崩溃的原因,原因其实就是虚拟机内部定义了信号处理函数,而在信号处理函数中对这两者做了额外的处理以让 JVM 不崩溃,另一方面也可以看出如果 JVM 不对信号做额外的处理,最后会自己退出并产生 crash 文件 hs_err_pid_xxx.log(可以通过 -XX:ErrorFile=/var/log/hs_err.log 这样的方式指定),这个文件记录了虚拟机崩溃的重要原因,所以也可以说,虚拟机是否崩溃只要看它是否会产生此崩溃日志文件
总结
正常情况下,操作系统为了保证系统安全,所以针对非法内存访问会发送一个 SIGSEGV 信号,而操作系统一般会调用默认的信号处理函数(一般会让相关的进程崩溃),但如果进程觉得"罪不致死",那么它也可以选择自定义一个信号处理函数,这样的话它就可以做一些自定义的逻辑,比如记录 crash 信息等有意义的事,回过头来看为什么虚拟机会针对 StackoverflowError 和 NullPointerException 做额外处理让线程恢复呢,针对 stackoverflow 其实它采用了一种栈回溯的方法保证线程可以一直执行下去,而捕获空指针错误主要是这个错误实在太普遍了,为了这一个很常见的错误而让 JVM 崩溃那线上的 JVM 要宕机多少次,所以与其这次倒不如让线程起死回生,并且将这两个错误/异常抛给用户来处理
参考文章
Segmentation Fault in Linux: https://www.cnblogs.com/kaixin/archive/2010/06/07/1753133.html
linux SIGSEGV 信号捕捉,保证发生段错误后程序不崩溃: https://blog.csdn.net/work_msh/article/details/8470277
到此这篇关于线程崩溃为什么不会导致 JVM 崩溃的文章就介绍到这了,更多相关线程JVM 崩溃内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
jvm crash的崩溃日志详细分析及注意点
生成 1. 生成error 文件的路径:你可以通过参数设置-XX:ErrorFile=/path/hs_error%p.log, 默认是在Java运行的当前目录 [default: ./hs_err_pid%p.log] 2. 参数-XX:OnError 可以在crash退出的时候执行命令,格式是-XX:OnError="string", <string> 可以是命令的集合,用分号做分隔符, 可以用"%p"来取到当前进程的ID. 例如: // -XX
-
浅谈linux模拟多线程崩溃和多进程崩溃
结论是: 多线程下如果其中一个线程崩溃了会导致其他线程(整个进程)都崩溃: 多进程下如果其中一个进程崩溃了对其余进程没有影响: 多线程 #include <stdio.h> #include <string.h> #include <stdlib.h> #include <pthread.h> #include <assert.h> void *fun1(void *arg) { printf("fun1 enter\n");
-

线程崩溃不会导致 JVM 崩溃的原因解析
目录 线程崩溃,进程一定会崩溃吗 进程是如何崩溃的-信号机制简介 为什么线程崩溃不会导致 JVM 进程崩溃 openJDK 源码解析 总结 参考文章 网上看到一个很有意思的据说是美团的面试题:为什么线程崩溃崩溃不会导致 JVM 崩溃,这个问题我看了不少回答,但都没答到根本原因,所以决定答一答,相信大家看完肯定会有收获,本文分以下几节来探讨 线程崩溃,进程一定会崩溃吗 进程是如何崩溃的-信号机制简介 为什么在 JVM 中线程崩溃不会导致 JVM 进程崩溃 openJDK 源码解析 线程崩溃,进程一
-
ThreadLocal导致JVM内存泄漏原因探究
目录 为什么要使用ThreadLocal 使用ThreadLocal 具体实现 引发内存泄漏的原因 为什么要使用ThreadLocal 在一整个业务逻辑流程中,为了在不同的地方或者不同的方法中使用同一个对象,但是又不想在方法形参中加这个对象,那么就可以使用ThreadLocal来保存 ThreadLocal最大的应用场景就是跨方法进行参数传递 ThreadLocal可以给每一个线程绑定一个变量的副本 使用ThreadLocal ThreadLocal常用的方法其实也就下面几个 // 返回当前线程
-
springcloud项目占用内存好几个G导致服务器崩溃的问题
问题描述 springcloud项目部署或调试时,占用的内存特别多.当部署到服务器上去后,有可能导致服务器内存占用过多而崩溃. 解决方案 1.本地调试时,IDEA中添加参数以减少本地内存使用 按照下图点击,添加参数 -Xms64m -Xmx128m 2.远程上线时,命令行添加参数 2.1单个服务直接部署 例如使用nohup执行时,在java与-jar之间添加参数-Xms64m -Xmx128m nohup java -Xms64m -Xmx128m -jar x.xx-xx.jar & 2.2对
-
网站导致浏览器崩溃的原因总结(多款浏览器) 推荐
面试某公司的时候,面试官问到,导致浏览器崩溃的原因有哪些?愚辈不才,仅回答出了内存泄漏.其实在网页在装载的过程中,常常由于种种原因使浏览器的反映变的很慢,或造成浏览器失去响应,甚至会导致机器无法进行其他的操作. 对于访客,如果登录您网站,浏览器就立刻崩溃,我想这对谁都是无法容忍的,对此总结了网站导致浏览器崩溃的原因: 1. 内存泄漏 还是先谈下内存泄漏,网站由于内存泄漏的而照成崩溃有两种情况,服务器的崩溃和浏览器的崩溃.内存泄漏所造成的问题是显而易见的,它使得已分配的内存的引用就会丢失,只要系统
-
win2003下PHP使用preg_match_all导致apache崩溃问题的解决方法
小编的平台是windows server 2003(32位系统) + Apache/2.2.9 (Win32) + PHP/5.2.17,在使用正则表达式 preg_match_all (如 preg_match_all("/ni(.*?)wo/", $html, $matches);)进行分析匹配比较长的字符串 $html 时(大于10万字节,一般用于分析采集回来的网页源码),Apache服务器会崩溃自动重启. 在Apache错误日志里有这样的提示: 复制代码 代码如下: [
-
关于9行代码导致系统崩溃的分析整理
目前很多地方都转载着利用9行代码史windows崩溃的文章,不过我发现没有关于为什么会使windows崩溃的分析.我先把原文给大家看看.然后把具体的细节说一下. 微软一直声称Windows XP多么多么稳定可靠,但日前一位名为Masaru Tsuchiyama的外国编程爱好者刊出了一小段C语言代码.这一只有9行的小程序如果在Windows XP/2000下运行,则可导致系统完全崩溃,并重新启动.但此程序对其他版本的Windows没有任何影响.这一产生无限循环输出的小程序的代码如下: #inclu
-
Go语言使用defer+recover解决panic导致程序崩溃的问题
案例:如果我们起了一个协程,但这个协程出现了panic,但我们没有捕获这个协程,就会造成程序的崩溃,这时可以在goroutine中使用recover来捕获panic,进行处理,这样主线程不会受到影响. 代码如下: package main import ( "fmt" "time" ) func sayHello() { for i := 0; i < 10; i++ { time.Sleep(time.Second) fmt.Println("he
-
vue关于接口请求数据过大导致浏览器崩溃的问题
目录 关于接口请求数据过大导致浏览器崩溃 解决的方法也很简单 一行代码解决vue数据量大卡顿问题 关于接口请求数据过大导致浏览器崩溃 做vue后台的时候,有一个导出所有用户数据的需求,我这里是前端导出,用的是iview的exportCsv方法,在这里说说遇到的问题吧. 首先看这里,查询的时候,Size有155MB,最开始在谷歌.火狐之类的上面测试,一切正常,后来被提出在360浏览器里页面直接崩溃. 解决的方法也很简单 因为拿到后端传过来的数组后,赋值给了data里面的一个数组,即this.xxx
-
java线程池参数位置导致的夺命故障宿主机打不开
目录 1. 出故障了 2. 找原因 3. 线程池的参数 4. 问题在哪里? 5. 结尾 1. 出故障了 没办法,干it这一行,就得天天面对故障,大家就是传说中的消防员,到处救火.不过,这次的故障范围有点大,宿主机都打不开了. 好在监控系统留下了一些证据. 证据发现,机器的CPU.内存.文件句柄,随着业务的增长,持续的上升...上升....,直到监控也无法将信息收集上来. 要命的是,这些宿主机上,部署了非常多的Java进程.没别的原因,就是为了节省成本,混部了应用.当宿主机表现出整体性的异常时,就
-
Python 程序报错崩溃后如何倒回到崩溃的位置(推荐)
假设我们有一段程序,从 Redis 中读取数据,解析以后提取出里面的 name 字段: import json import redis client = redis.Redis() def read(): while True: data = client.lpop('info') if data: yield json.loads(data) else: break def parse(): for data in self.read(): print(data['name']) if __