卡尔曼滤波数据处理技巧通俗理解及python实现
目录
- 学习前言
- 什么是卡尔曼滤波
- 卡尔曼滤波是怎么滤波的
- 卡尔曼滤波实例
- 卡尔曼滤波的python代码实现
学习前言
好久没用过arduino了,接下去要用arduino和超声波做个小实验,对于读取的模拟量肯定要进行滤波呀,不然这模拟量咋咋呼呼的怎么用
什么是卡尔曼滤波
先看看百度百科解释哈:卡尔曼滤波(Kalman filtering)是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法。由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程。
重要的事说三遍:
还不如不看!
还不如不看!!
还不如不看!!!
其实大家并不需要把卡尔曼滤波当作一种很复杂的东西,用通俗的话来讲,卡尔曼滤波算法只是一种 滤波算法,它的功能就是 滤波,滤波的作用就是减少噪声与干扰对数据测量的影响。
卡尔曼滤波是怎么滤波的
接下来我会用一句话概括卡尔曼滤波的操作过程:
卡尔曼滤波是一种通过 历史数据、历史积累误差、当前测量数据与当前误差 联合计算出的当前被测量的最优预测值。
首先大家要先理解什么是当前被测量的最优预测值:
里面有两个重要的概念,分别是 最优 和 预测值 :
这意味着:
1、卡尔曼滤波的结果不是确确实实被测量出来的,而是利用公式计算出来的预测结果(并不是说预测结果就不好,测量还存在误差呢!);
2、最优是因为卡尔曼滤波考虑的非常多,它结合了四个参数对当前的被测量进行预测,所以效果比较好。
接下里大家要理解 历史数据、历史积累误差、当前测量数据与当前误差 的概念。
我会通过实例给大家讲讲这四个东西的概念。
卡尔曼滤波实例
假设我们现在在用超声波测距离!现在是t时间,我们需要用t-1时间的距离来估计t时间的距离。
设在t-1时刻,超声波的被测量的最优预测值为50cm,而到t-1时刻的积累误差3cm,你自己对预测的不确定误差为4cm,那么在t-1时刻,其总误差为(32+42)1/2=5cm。
在t时刻,超声波测得的实际值53cm,测量误差为2cm,那我们要怎么去相信上一时刻的预测值和这一时刻的实际值呢?因为二者都不是准的,我们可以利用误差来计算。
因此,我们结合 历史数据、历史积累误差、当前测量数据与当前误差 来计算:
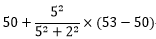
所以当前的最优预测值为52.59。
卡尔曼滤波的python代码实现
import numpy as np
import matplotlib.pyplot as plt
# Q为这一轮的心里的预估误差
Q = 0.00001
# R为下一轮的测量误差
R = 0.1
# Accumulated_Error为上一轮的估计误差,具体呈现为所有误差的累计
Accumulated_Error = 1
# 初始旧值
kalman_adc_old = 0
SCOPE = 50
def kalman(ADC_Value):
global kalman_adc_old
global Accumulated_Error
# 新的值相比旧的值差太大时进行跟踪
if (abs(ADC_Value-kalman_adc_old)/SCOPE > 0.25):
Old_Input = ADC_Value*0.382 + kalman_adc_old*0.618
else:
Old_Input = kalman_adc_old
# 上一轮的 总误差=累计误差^2+预估误差^2
Old_Error_All = (Accumulated_Error**2 + Q**2)**(1/2)
# R为这一轮的预估误差
# H为利用均方差计算出来的双方的相信度
H = Old_Error_All**2/(Old_Error_All**2 + R**2)
# 旧值 + 1.00001/(1.00001+0.1) * (新值-旧值)
kalman_adc = Old_Input + H * (ADC_Value - Old_Input)
# 计算新的累计误差
Accumulated_Error = ((1 - H)*Old_Error_All**2)**(1/2)
# 新值变为旧值
kalman_adc_old = kalman_adc
return kalman_adc
array = np.array([50]*200)
s = np.random.normal(0, 5, 200)
test_array = array + s
plt.plot(test_array)
adc=[]
for i in range(200):
adc.append(kalman(test_array[i]))
plt.plot(adc)
plt.plot(array)
plt.show()
实验结果为:
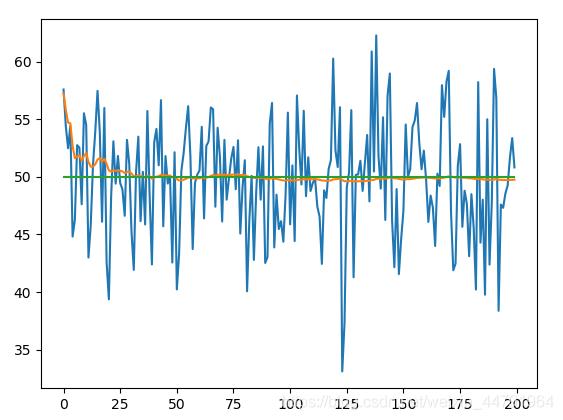
以上就是卡尔曼滤波数据处理技巧通俗理解及python实现的详细内容,更多关于python卡尔曼滤波数据处理的资料请关注我们其它相关文章!
相关推荐
-
基于Python的身份证验证识别和数据处理详解
根据GB11643-1999公民身份证号码是特征组合码,由十七位数字本体码和一位数字校验码组成,排列顺序从左至右依次为: 六位数字地址码八位数字出生日期码三位数字顺序码一位数字校验码(数字10用罗马X表示) 校验系统: 校验码采用ISO7064:1983,MOD11-2校验码系统(图为校验规则样例) 用身份证号的前17位的每一位号码字符值分别乘上对应的加权因子值,得到的结果求和后对11进行取余,最后的结果放到表2检验码字符值..换算关系表中得出最后的一位身份证号码 代码: # coding=ut
-
python数据处理 根据颜色对图片进行分类的方法
前面一篇文章有说过,利用scrapy来爬取图片,是为了对图片数据进行分类而收集数据. 本篇文章就是利用上次爬取的图片数据,根据图片的颜色特征来做一个简单的分类处理. 实现步骤如下: 1:图片路径添加 2:对比度处理 3:滤波处理 4:数据提取以及特征向量化 5:图片分类处理 6:根据处理结果将图片分类保存 代码量中等,还可以更少,只是我为了练习类的使用,而将每个步骤都封装成了一个独立的类,当然里面也有类继承的问题,遇到的问题前面一篇文章有讲解.内容可能有点繁琐,尤其是文件和路径的使用(可以自己修
-
Python使用Pandas对csv文件进行数据处理的方法
今天接到一个新的任务,要对一个140多M的csv文件进行数据处理,总共有170多万行,尝试了导入本地的MySQL数据库进行查询,结果用Navicat导入直接卡死....估计是XAMPP套装里面全默认配置的MySQL性能不给力,又尝试用R搞一下吧结果发现光加载csv文件就要3分钟左右的时间,相当不给力啊,翻了翻万能的知乎发现了Python下的一个神器包:Pandas(熊猫们?),加载这个140多M的csv文件两秒钟就搞定,后面的分类汇总等操作也都是秒开,太牛逼了!记录一下这次数据处理的过程: 使用
-
Python xpath表达式如何实现数据处理
xpath表达式 1. xpath语法 <bookstore> <book> <title lang="eng">Harry Potter</title> <price>999</price> </book> <book> <title lang="eng">Learning XML</title> <price>888</pri
-

C#实现一阶卡尔曼滤波算法的示例代码
//FilterKalman.cs namespace FusionFiltering { public class FilterKalman { private double A = 1; private double B = 0; private double H = 1; private double R; private double Q; private double cov = double.NaN; private double x = double.NaN; public Fil
-
卡尔曼滤波数据处理技巧通俗理解及python实现
目录 学习前言 什么是卡尔曼滤波 卡尔曼滤波是怎么滤波的 卡尔曼滤波实例 卡尔曼滤波的python代码实现 学习前言 好久没用过arduino了,接下去要用arduino和超声波做个小实验,对于读取的模拟量肯定要进行滤波呀,不然这模拟量咋咋呼呼的怎么用 什么是卡尔曼滤波 先看看百度百科解释哈:卡尔曼滤波(Kalman filtering)是一种利用线性系统状态方程,通过系统输入输出观测数据,对系统状态进行最优估计的算法.由于观测数据中包括系统中的噪声和干扰的影响,所以最优估计也可看作是滤波过程.
-
史上最通俗理解的Java死锁代码演示
死锁的概念 知识储备 对象锁:Java一切皆对象,每个类都有一个class文件.由class文件可以new出对象,我们简单认识 下java对象,对象有个对象头信息,也就是这个对象概述,其中一条信息就是对象锁,也就是我们当前对象有没有被锁定,被哪个引用锁定. synchronized:synchronized是java关键词,如果运用到方法上代表我们锁的是这个方法,如果我们锁的代码块,代表再这个代码块内我们持有这个锁,Java Effective也是提倡减小锁的范围.我们进入同步代码块会加锁,执行
-
深入理解最新Python中的Match Case
有些人仍然认为 Python 不需要"switch-case"语法. 甚至 Guido 本人也不支持在 Python 中添加这种语法.但是,为什么它仍然在这个新版本中发布? 在我看来,原因可以从名称中找到,它被称为"match case"而不是像大多数编程语言那样的"switch case". 在本文中,我将使用 7 个示例来演示新语法的灵活性和"pythonic",希望它能帮助你更容易理解它.如果你对 Python 3.10
-
Spring MVC中基于自定义Editor的表单数据处理技巧分享
面向对象的编程方式极大地方便了程序员在管理数据上所花费的精力.在基于Spring MVC的Web开发过程当中,可以通过对象映射的方式来管理表单提交上来的数据,而不用去一个一个地从request中提取出来.另外,这一功能还支持基本数据类型的映射.例如in.long.float等等.这样我们就能从传统单一的String类型中解脱出来.然而,应用是灵活的.我们对数据的需求是千变万化的.有些时候我们需要对表单的数据进行兼容处理. 例如日期格式的兼容: 中国的日期标注习惯采用yyyy-MM-dd格式,欧美
-
json数据处理技巧(字段带空格、增加字段、排序等等)
1.json数据的正常取值:json[i].fieldName 2.json数据的字段带空格:eval('json[' + i + ']["' + field + '"]') 3.json数据的赋值:eval('json[' + i + ']["' + field + '"]=' + jsonFilter.length); 4.json数据增加字段:循环所有数据,直接json[i].newField=defaultValue就可以了 5.json数据的排序:相当于数
-
Python数据处理的三个实用技巧分享
目录 1 Pandas 移除某列 2 统计标题单词数 3 Genre 频次统计 我使用的 Pandas 版本如下,顺便也导入 Pandas 库. >>> import pandas as pd >>> pd.__version__ '0.25.1' 在开始前先确保解释器和数据集在同一目录下: >>> import os >>> os.chdir('D://source/dataset') # 这是我的数据集所在目录 >>&
-
深入理解python多线程编程
进程 进程的概念: 进程是资源分配的最小单位,他是操作系统进行资源分配和调度运行的基本单位.通俗理解:一个正在运行的一个程序就是一个进程.例如:正在运行的qq.wechat等,它们都是一个进程. 进程的创建步骤 1.导入进程包 import multiprocessing 2.通过进程类创建进程对象 进程对象 = multiprocessing.Process() 3.启动进程执行任务 进程对象.start() import multiprocessing import time def
-
深入理解Python中变量赋值的问题
前言 在Python中变量名规则与其他大多数高级语言一样,都是受C语言影响的,另外变量名是大小写敏感的. Python是动态类型语言,也就是说不需要预先声明变量类型,变量的类型和值在赋值那一刻被初始化,下面详细介绍了Python的变量赋值问题,一起来学习学习吧. 我们先看一下如下代码: c = {} def foo(): f = dict(zip(list("abcd"), [1, 2 ,3 ,4])) c.update(f) if __name__ == "__main__
-
浅析Python数据处理
Numpy.Pandas是Python数据处理中经常用到的两个框架,都是采用C语言编写,所以运算速度快.Matplotlib是Python的的画图工具,可以把之前处理后的数据通过图像绘制出来.之前只是看过语法,没有系统学习总结过,本博文总结了这三个框架的API. 以下是这三个框架的的简单介绍和区别: Numpy:经常用于数据生成和一些运算 Pandas:基于Numpy构建的,是Numpy的升级版本 Matplotlib:Python中强大的绘图工具 Numpy Numpy快速入门教程可参考:Nu
-
彻彻底底地理解Python中的编码问题
Python处理文本的功能非常强大,但是如果是初学者,没有搞清楚python中的编码机制,也经常会遇到乱码或者decode error.本文的目的是简明扼要地说明python的编码机制,并给出一些建议. 问题1:问题在哪里? 问题是我们的靶子,心中没有问题去学习就会抓不住重点. 本文使用的编程环境是centos6.7,python2.7.我们在shell中键入python以打开python命令行,并键入如下两句话: s = "中国zg" e = s.encode("utf-8