python实现八大排序算法(2)
本文接上一篇博客python实现的八大排序算法part1,将继续使用python实现八大排序算法中的剩余四个:快速排序、堆排序、归并排序、基数排序
5、快速排序
快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的。
算法思想:
已知一组无序数据a[1]、a[2]、……a[n],需将其按升序排列。首先任取数据a[x]作为基准。比较a[x]与其它数据并排序,使a[x]排在数据的第k位,并且使a[1]~a[k-1]中的每一个数据<a[x],a[k+1]~a[n]中的每一个数据>a[x],然后采用分治的策略分别对a[1]~a[k-1]和a[k+1]~a[n]两组数据进行快速排序。
优点:极快,数据移动少;
缺点:不稳定。
python代码实现:
def quick_sort(list):
little = []
pivotList = []
large = []
# 递归出口
if len(list) <= 1:
return list
else:
# 将第一个值做为基准
pivot = list[0]
for i in list:
# 将比基准小的值放到less数列
if i < pivot:
little.append(i)
# 将比基准大的值放到more数列
elif i > pivot:
large.append(i)
# 将和基准相同的值保存在基准数列
else:
pivotList.append(i)
# 对less数列和more数列继续进行快速排序
little = quick_sort(little)
large = quick_sort(large)
return little + pivotList + large
下面这段代码出自《Python cookbook 第二版的三行实现python快速排序。
#!/usr/bin/env python
#coding:utf-8
'''
file:python-8sort.py
date:9/1/17 9:03 AM
author:lockey
email:lockey@123.com
desc:python实现八大排序算法
'''
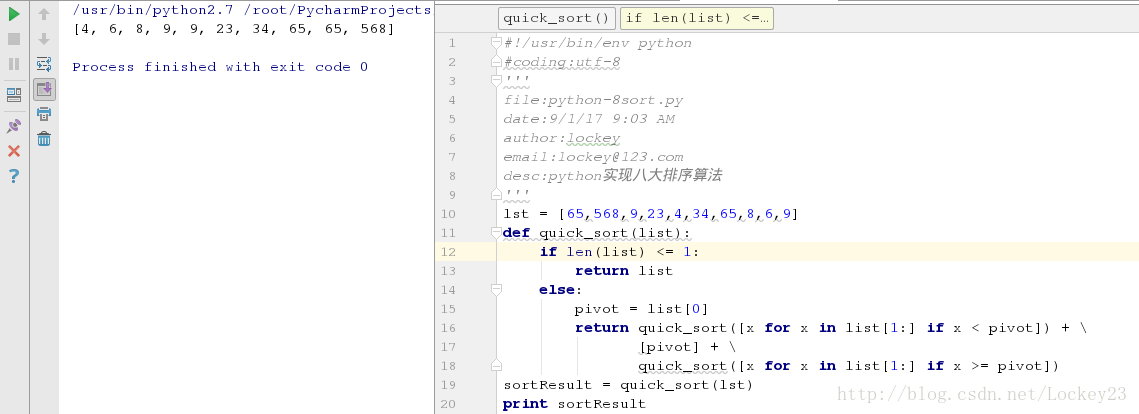
lst = [65,568,9,23,4,34,65,8,6,9]
def quick_sort(list):
if len(list) <= 1:
return list
else:
pivot = list[0]
return quick_sort([x for x in list[1:] if x < pivot]) + \
[pivot] + \
quick_sort([x for x in list[1:] if x >= pivot])
运行测试结果截图:
好吧,还有更精简的语法糖,一行完事:
quick_sort = lambda xs : ( (len(xs) <= 1 and [xs]) or [ quick_sort( [x for x in xs[1:] if x < xs[0]] ) + [xs[0]] + quick_sort( [x for x in xs[1:] if x >= xs[0]] ) ] )[0]
若初始序列按关键码有序或基本有序时,快排序反而蜕化为冒泡排序。为改进之,通常以“三者取中法”来选取基准记录,即将排序区间的两个端点与中点三个记录关键码居中的调整为支点记录。快速排序是一个不稳定的排序方法。
在改进算法中,我们将只对长度大于k的子序列递归调用快速排序,让原序列基本有序,然后再对整个基本有序序列用插入排序算法排序。实践证明,改进后的算法时间复杂度有所降低,且当k取值为 8 左右时,改进算法的性能最佳。
6、堆排序(Heap Sort)
堆排序是一种树形选择排序,是对直接选择排序的有效改进。
优点 : 效率高
缺点:不稳定
堆的定义下:具有n个元素的序列 (h1,h2,...,hn),当且仅当满足(hi>=h2i,hi>=2i+1)或(hi<=h2i,hi<=2i+1) (i=1,2,...,n/2)时称之为堆。在这里只讨论满足前者条件的堆。由堆的定义可以看出,堆顶元素(即第一个元素)必为最大项(大顶堆)。完全二 叉树可以很直观地表示堆的结构。堆顶为根,其它为左子树、右子树。
算法思想:
初始时把要排序的数的序列看作是一棵顺序存储的二叉树,调整它们的存储序,使之成为一个 堆,这时堆的根节点的数最大。然后将根节点与堆的最后一个节点交换。然后对前面(n-1)个数重新调整使之成为堆。依此类推,直到只有两个节点的堆,并对 它们作交换,最后得到有n个节点的有序序列。从算法描述来看,堆排序需要两个过程,一是建立堆,二是堆顶与堆的最后一个元素交换位置。所以堆排序有两个函数组成。一是建堆的渗透函数,二是反复调用渗透函数实现排序的函数。
python代码实现:
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def adjust_heap(lists, i, size):# 调整堆
lchild = 2 * i + 1;rchild = 2 * i + 2
max = i
if i < size / 2:
if lchild < size and lists[lchild] > lists[max]:
max = lchild
if rchild < size and lists[rchild] > lists[max]:
max = rchild
if max != i:
lists[max], lists[i] = lists[i], lists[max]
adjust_heap(lists, max, size)
def build_heap(lists, size):# 创建堆
halfsize = int(size/2)
for i in range(0, halfsize)[::-1]:
adjust_heap(lists, i, size)
def heap_sort(lists):# 堆排序
size = len(lists)
build_heap(lists, size)
for i in range(0, size)[::-1]:
lists[0], lists[i] = lists[i], lists[0]
adjust_heap(lists, 0, i)
print(lists)
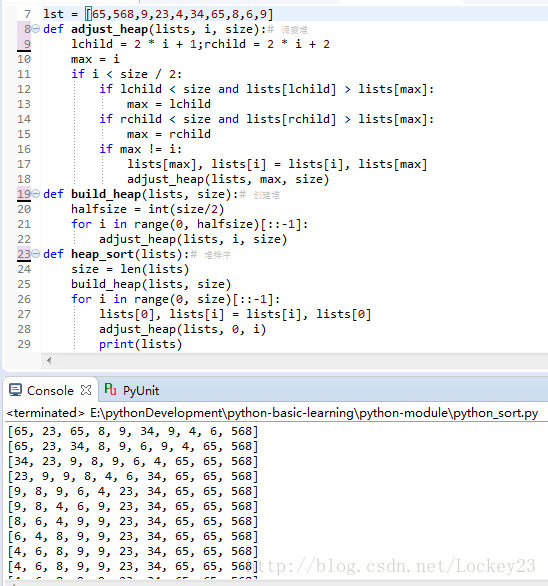
结果示例:
7、归并排序
算法思想:
归并(Merge)排序是建立在归并操作上的一种有效的排序算法,该算法是采用分治法的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。若将两个有序表合并成一个有序表,称为二路归并。
归并过程为:比较a[i]和a[j]的大小,若a[i]≤a[j],则将第一个有序表中的元素a[i]复制到r[k]中,并令i和k分别加上1;否则将第二个有序表中的元素a[j]复制到r[k]中,并令j和k分别加上1,如此循环下去,直到其中一个有序表取完,然后再将另一个有序表中剩余的元素复制到r中从下标k到下标t的单元。归并排序的算法我们通常用递归实现,先把待排序区间[s,t]以中点二分,接着把左边子区间排序,再把右边子区间排序,最后把左区间和右区间用一次归并操作合并成有序的区间[s,t]。
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
lst = [65,568,9,23,4,34,65,8,6,9]
def merge(left, right):
i, j = 0, 0
result = []
while i < len(left) and j < len(right):
if left[i] <= right[j]:
result.append(left[i])
i += 1
else:
result.append(right[j])
j += 1
result += left[i:]
result += right[j:]
print(result)
return result
def merge_sort(lists):# 归并排序
if len(lists) <= 1:
return lists
num = int(len(lists) / 2)
left = merge_sort(lists[:num])
right = merge_sort(lists[num:])
return merge(left, right)
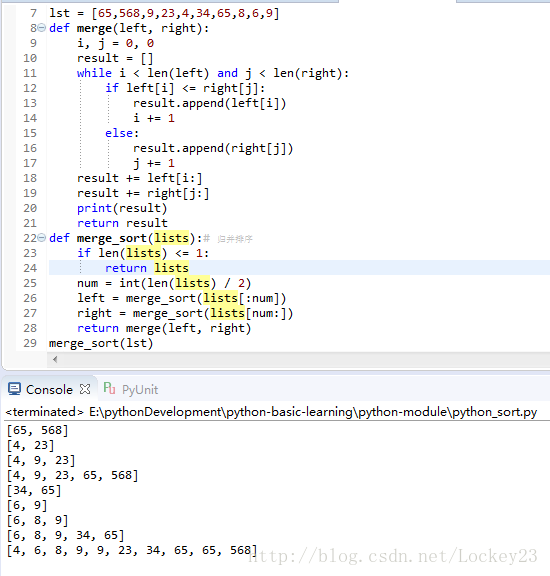
程序结果示例:
8、桶排序/基数排序(Radix Sort)
优点:快,效率最好能达到O(1)
缺点:
1.首先是空间复杂度比较高,需要的额外开销大。排序有两个数组的空间开销,一个存放待排序数组,一个就是所谓的桶,比如待排序值是从0到m-1,那就需要m个桶,这个桶数组就要至少m个空间。
2.其次待排序的元素都要在一定的范围内等等。
算法思想:
是将阵列分到有限数量的桶子里。每个桶子再个别排序(有可能再使用别的排序算法或是以递回方式继续使用桶排序进行排序)。桶排序是鸽巢排序的一种归纳结果。当要被排序的阵列内的数值是均匀分配的时候,桶排序使用线性时间(Θ(n))。但桶排序并不是 比较排序,他不受到 O(n log n) 下限的影响。
简单来说,就是把数据分组,放在一个个的桶中,然后对每个桶里面的在进行排序。
例如要对大小为[1..1000]范围内的n个整数A[1..n]排序
首先,可以把桶大小设为10,这样就有100个桶了,具体而言,设集合B[1]存储[1..10]的整数,集合B[2]存储 (10..20]的整数,……集合B[i]存储( (i-1)*10, i*10]的整数,i = 1,2,..100。总共有 100个桶。
然后,对A[1..n]从头到尾扫描一遍,把每个A[i]放入对应的桶B[j]中。 再对这100个桶中每个桶里的数字排序,这时可用冒泡,选择,乃至快排,一般来说任 何排序法都可以。
最后,依次输出每个桶里面的数字,且每个桶中的数字从小到大输出,这 样就得到所有数字排好序的一个序列了。
假设有n个数字,有m个桶,如果数字是平均分布的,则每个桶里面平均有n/m个数字。如果
对每个桶中的数字采用快速排序,那么整个算法的复杂度是
O(n + m * n/m*log(n/m)) = O(n + nlogn - nlogm)
从上式看出,当m接近n的时候,桶排序复杂度接近O(n)
当然,以上复杂度的计算是基于输入的n个数字是平均分布这个假设的。这个假设是很强的 ,实际应用中效果并没有这么好。如果所有的数字都落在同一个桶中,那就退化成一般的排序了。
python代码实现:
# -*- coding: UTF-8 -*-
'''
Created on 2017年9月2日
Running environment:win7.x86_64 eclipse python3
@author: Lockey
'''
import math
lst = [65,56,9,23,84,34,8,6,9,54,11]
#因为列表数据范围在100以内,所以将使用十个桶来进行排序
def radix_sort(lists, radix=10):
k = int(math.ceil(math.log(max(lists), radix)))
bucket = [[] for i in range(radix)]
for i in range(1, k+1):
for j in lists:
gg = int(j/(radix**(i-1))) % (radix**i)
bucket[gg].append(j)
del lists[:]
for z in bucket:
lists += z
del z[:]
print(lists)
return lists
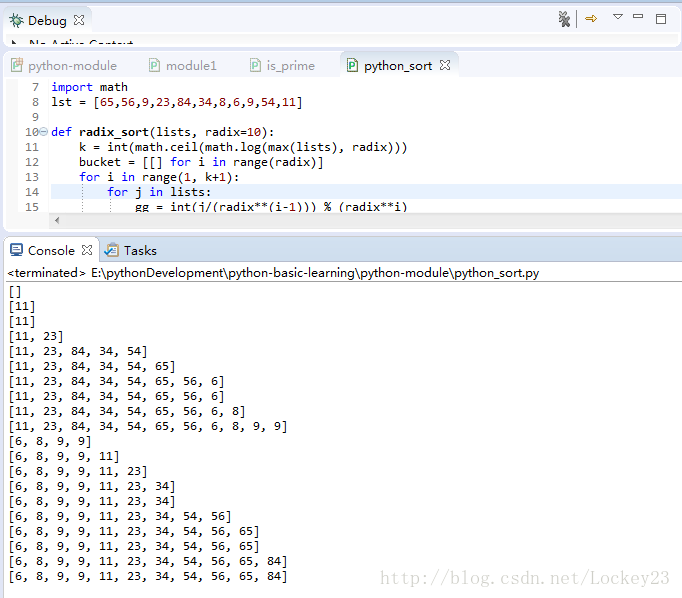
程序运行测试结果:
以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-
python编程羊车门问题代码示例
问题: 有3扇关闭的门,一扇门后面停着汽车,其余门后是山羊,只有主持人知道每扇门后面是什么.参赛者可以选择一扇门,在开启它之前,主持人会开启另外一扇门,露出门后的山羊,然后允许参赛者更换自己的选择. 请问: 1.按照你的第一感觉回答,你觉得不换选择能有更高的几率获得汽车,还是换选择能有更高的几率获得汽车?或几率没有发生变化? 答:第一感觉换与不换获奖几率没有发生变化. 2.请自己认真分析一下"不换选择能有更高的几率获得汽车,还是换选择能有更高的几率获得汽车?或几率没有发生变化?" 写出
-
Python实现的中国剩余定理算法示例
本文实例讲述了Python实现的中国剩余定理算法.分享给大家供大家参考,具体如下: 中国剩余定理(Chinese Remainder Theorem-CRT):又称孙子定理,是数论中的一个定理.即如果一个人知道了一个数n被多个整数相除得到的余数,当这些除数两两互质的情况下,这个人就可以唯一的确定被这些个整数乘积除n所得的余数. 维基百科上wiki:The Chinese remainder theorem is a theorem of number theory, which states t
-
Python基于分水岭算法解决走迷宫游戏示例
本文实例讲述了Python基于分水岭算法解决走迷宫游戏.分享给大家供大家参考,具体如下: #Solving maze with morphological transformation """ usage:Solving maze with morphological transformation needed module:cv2/numpy/sys ref: 1.http://www.mazegenerator.net/ 2.http://blog.leanote.com
-
用Python实现随机森林算法的示例
拥有高方差使得决策树(secision tress)在处理特定训练数据集时其结果显得相对脆弱.bagging(bootstrap aggregating 的缩写)算法从训练数据的样本中建立复合模型,可以有效降低决策树的方差,但树与树之间有高度关联(并不是理想的树的状态). 随机森林算法(Random forest algorithm)是对 bagging 算法的扩展.除了仍然根据从训练数据样本建立复合模型之外,随机森林对用做构建树(tree)的数据特征做了一定限制,使得生成的决策树之间没有关联,
-
Python计算斗牛游戏概率算法实例分析
本文实例讲述了Python计算斗牛游戏概率算法.分享给大家供大家参考,具体如下: 过年回家,都会约上亲朋好友聚聚会,会上经常会打麻将,斗地主,斗牛.在这些游戏中,斗牛是最受欢迎的,因为可以很多人一起玩,而且没有技术含量,都是看运气(专业术语是概率). 斗牛的玩法是: 1. 把牌中的JQK都拿出来 2. 每个人发5张牌 3. 如果5张牌中任意三张加在一起是10的 倍数,就是有牛.剩下两张牌的和的10的余数就是牛数. 牌的大小: 4条 > 3条 > 牛十 > 牛九 > -- >
-

python实现八大排序算法(2)
本文接上一篇博客python实现的八大排序算法part1,将继续使用python实现八大排序算法中的剩余四个:快速排序.堆排序.归并排序.基数排序 5.快速排序 快速排序是通常被认为在同数量级(O(nlog2n))的排序方法中平均性能最好的. 算法思想: 已知一组无序数据a[1].a[2].--a[n],需将其按升序排列.首先任取数据a[x]作为基准.比较a[x]与其它数据并排序,使a[x]排在数据的第k位,并且使a[1]~a[k-1]中的每一个数据<a[x],a[k+1]~a[n]中的每一个数
-
python实现八大排序算法(1)
排序 排序是计算机内经常进行的一种操作,其目的是将一组"无序"的记录序列调整为"有序"的记录序列.分内部排序和外部排序.若整个排序过程不需要访问外存便能完成,则称此类排序问题为内部排序.反之,若参加排序的记录数量很大,整个序列的排序过程不可能完全在内存中完成,需要访问外存,则称此类排序问题为外部排序.内部排序的过程是一个逐步扩大记录的有序序列长度的过程. 看图使理解更清晰深刻: 假定在待排序的记录序列中,存在多个具有相同的关键字的记录,若经过排序,这些记录的相对次序
-
Python实现八大排序算法
如何用Python实现八大排序算法 1.插入排序 描述 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的.个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为 O(n^2).是稳定的排序方法.插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插 入的位置),而第二部分就只包含这一个元素(即待插入元素).在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中. 代码实现 def insert_
-
八大排序算法的Python实现
Python实现八大排序算法,具体内容如下 1.插入排序 描述 插入排序的基本操作就是将一个数据插入到已经排好序的有序数据中,从而得到一个新的.个数加一的有序数据,算法适用于少量数据的排序,时间复杂度为O(n^2).是稳定的排序方法.插入算法把要排序的数组分成两部分:第一部分包含了这个数组的所有元素,但将最后一个元素除外(让数组多一个空间才有插入的位置),而第二部分就只包含这一个元素(即待插入元素).在第一部分排序完成后,再将这个最后元素插入到已排好序的第一部分中. 代码实现 def inser
-
python八大排序算法速度实例对比
这篇文章并不是介绍排序算法原理的,纯粹是想比较一下各种排序算法在真实场景下的运行速度. 算法由 Python 实现,可能会和其他语言有些区别,仅当参考就好. 测试的数据是自动生成的,以数组形式保存到文件中,保证数据源的一致性. 排序算法 直接插入排序 时间复杂度:O(n²) 空间复杂度:O(1) 稳定性:稳定 def insert_sort(array): for i in range(len(array)): for j in range(i): if array[i] < array[j]:
-
必须知道的C语言八大排序算法(收藏)
概述 排序有内部排序和外部排序,内部排序是数据记录在内存中进行排序,而外部排序是因排序的数据很大,一次不能容纳全部的排序记录,在排序过程中需要访问外存. 我们这里说说八大排序就是内部排序. 当n较大,则应采用时间复杂度为O(nlog2n)的排序方法:快速排序.堆排序或归并排序序. 快速排序:是目前基于比较的内部排序中被认为是最好的方法,当待排序的关键字是随机分布时,快速排序的平均时间最短: 1.插入排序-直接插入排序(Straight Insertion Sort) 基本思想: 将一个记录插入到
-
python实现bucket排序算法实例分析
本文实例讲述了python实现bucket排序算法.分享给大家供大家参考.具体实现方法如下: def bucketSort(a, n, buckets, m): for j in range(m): buckets[j] = 0 for i in range(n): buckets[a[i]] += 1 i = 0 for j in range(m): for k in range(buckets[j]): a[i] = j i += 1 希望本文所述对大家的Python程序设计有所帮助.
-
Python实现希尔排序算法的原理与用法实例分析
本文实例讲述了Python实现希尔排序算法的原理与用法.分享给大家供大家参考,具体如下: 希尔排序(Shell Sort)是插入排序的一种.也称缩小增量排序,是直接插入排序算法的一种更高效的改进版本. 希尔排序的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个"增量"的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序.因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高
-
python 常见的排序算法实现汇总
排序分为两类,比较类排序和非比较类排序,比较类排序通过比较来决定元素间的相对次序,其时间复杂度不能突破O(nlogn):非比较类排序可以突破基于比较排序的时间下界,缺点就是一般只能用于整型相关的数据类型,需要辅助的额外空间. 要求能够手写时间复杂度位O(nlogn)的排序算法:快速排序.归并排序.堆排序 1.冒泡排序 思想:相邻的两个数字进行比较,大的向下沉,最后一个元素是最大的.列表右边先有序. 时间复杂度$O(n^2)$,原地排序,稳定的 def bubble_sort(li:list):
-
python实现经典排序算法的示例代码
以下排序算法最终结果都默认为升序排列,实现简单,没有考虑特殊情况,实现仅表达了算法的基本思想. 冒泡排序 内层循环中相邻的元素被依次比较,内层循环第一次结束后会将最大的元素移到序列最右边,第二次结束后会将次大的元素移到最大元素的左边,每次内层循环结束都会将一个元素排好序. def bubble_sort(arr): length = len(arr) for i in range(length): for j in range(length - i - 1): if arr[j] > arr[j