Mysql InnoDB 的内存结构详情
目录
- 1 前言
- 2 InnoDB 存储引擎结构
- 2.1 InnoDB表存储引擎文件
- 2.2 InnoDB 预读机制
- 2.3 InnoDB 特性
- 2.3.1 插入缓存
- 2.3.2 二次写 (double write)
- 2.3.3 自适应hash索引
- 2.3.4 异步IO
- 2.3.5 刷新邻接页
- 3 sql 执行的逻辑
- 3.1 sql 执行
- 3.2 FreeList、LRU List 和 Flush List
1 前言
我们都熟悉mysql数据库服务架构,也清楚 sql 的执行顺序,mysql的数据在磁盘和内存中的存储结构是采用B+树的数据结构,但是在InnoDB引擎中,数据在内存和磁盘中的展示形式以及怎么和mysql的服务架构建立联系,sql 查询和 InnoDB 引擎之前的联系,可能就不是不清楚了。
mysql 的逻辑架构图如下所示:

2 InnoDB 存储引擎结构
InnoDB存储引擎的逻辑存储结构是什么呢,其实所有的数据都被逻辑地放在了一个空间中这个空间中的文件就是实际存在的物理文件,即表空间。默认情况下,一个数据库表占用一个表空间,表空间中存放该表对应的数据、索引、insert buffer bitmap undo信息、insert buffer 索引页、double write buffer 等是放在共享表空间中的。
# 默认一个数据库表单独占有一个表空间 show variables like '%innodb_file_per_table%' innodb_file_per_table=ON # 修改设置 SET GLOBAL innodb_file_per_table=OFF;
2.1 InnoDB表存储引擎文件
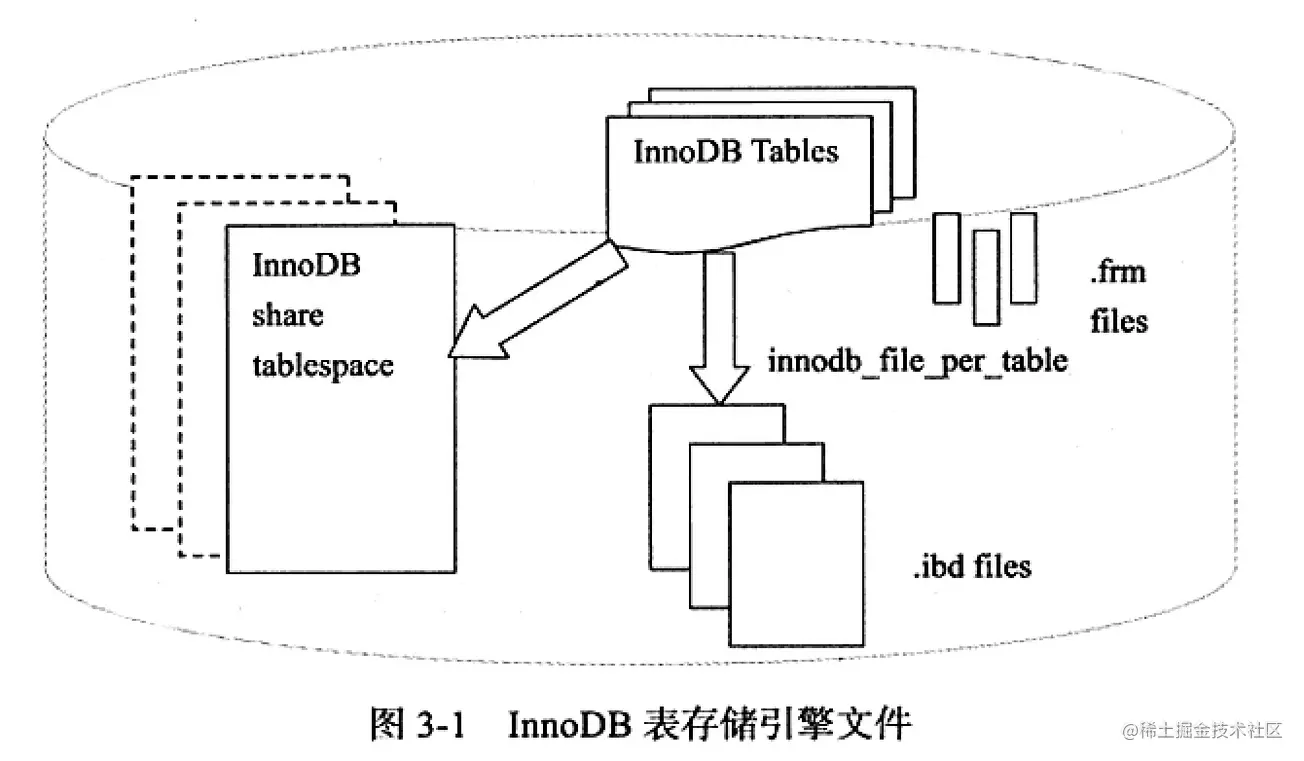
每个表空间由 段 segment 区 extent 页 page 组成。页是数据存储数据的基本单位,默认大小为 16kb。 区是由连续页组成的空间,默认大小为 1MB。多个区构成表的段。 InnoDB 逻辑存储结构

在我们执行sql时,不论是查询还是修改,myql 总会把数据从磁盘读取内内存中,而且在读取数据时,不会单独加在一条数据,而是直接加载数据所在的数据页到内存中,而读取的方式有两种,现行预读方式和随机预读方式,默认采用线性预读方式。
InnoDB 引擎架构 :

2.2 InnoDB 预读机制
线性预读和随机预读:
线性预读是以 extent 为单位,而随机预读是以 extent 中的page 为单位,线性预读着眼于将下一个extent 数据读取到 buffer pool 中,而随机预读是将当前extent中剩余的page读到 buffer pool 中。 如果一个extent 区中被顺序读取得page数量超过一定的数量( innodb_read_ahead_threshold),则直接加载 extent 中剩余的数据页。
2.3 InnoDB 特性
2.3.1 插入缓存
插入缓冲(Insert Buffer/Change Buffer)为了提升插入性能,insert buffer 是 insert buffer 的增强版,insert buffer 只对插入有效,而change buffer对 insert/update/delete 都有效。插入缓存只对非唯一索引和辅助索引有效,对每一次的插入不是写到索引页中,而是先判断插入的非聚集索引页是否在缓存中,如果在则直接插入,不存在则插入到 insert buffer 中,按照一定的频率进行合并操作,写回到磁盘。这样将多个插入操作合并进一个操作中,目的是为了减少随机IO带来的性能损耗。
2.3.2 二次写 (double write)
插入缓存给 InnoDB 存储引擎带来了性能上的提升,而 double write 则是保障 InnoDB 存储引擎操作数据页的可靠性。double write 分为两部分组成,一部分在内存中的 double write buffer, 大小为 2MB,另一部分是物理磁盘上共享表空间中连续的128个数据页,即2个区大小(同样是2MB)。在对缓冲池的脏页进行刷新时,并不是直接写磁盘,而是通过 memcpy 函数将脏页复制到内存中的 doublewrite buffer,之后通过doublewrite buffer 在分两次,每次1MB 顺序地写入共享表空间的物理磁盘上,然后马上调用 fsync 将数据同步至磁盘。由于doublewrite 是连续的空间,这样的顺序写IO开销不大。在doublewrite页写完后,再次离散写入各个表空间。如果操作系统在将数据页写入磁盘发生崩溃,那么在恢复的过程中,InnoDB 引擎会从共享表空间中的doublewrite找到该页的一个副本,将其复制到表空间文件,再应用重做日志。

2.3.3 自适应hash索引
hash是一种等值查询,InnoDB 存储引擎会监控对表上各个索引页的查询,如果观察到建立hash索引会带来速度提升,则建立相应的索引,因此称为自适应哈希索引(Adaptive Hash Index,AHI)。AHI是通过缓冲池中的B+树页构造而来,建立速度比较快,而且不需要对整张表建立哈希索引,只是建立热点页的索引。AHI默认是开启的状态。
2.3.4 异步IO
为了提高磁盘的操作性能, 当前的数据库系统一般采用异步IO(Asynchronous IO,AIO)的方式来处理磁盘操作,InnoDB 存储引擎也是如此,AIO的优势在于减少SQL查询需要的时间,另外也可以进行IO Merge 操作,就是将多个IO合并为1个IO,这样就可以提高IOPS的性能。
# 开启本地 AIO show valiables like 'innodb_use_native_aio';
2.3.5 刷新邻接页
InnoDB 存储引擎提供了 Flush Neighbor Page(刷新邻接页)的特性,当刷新一个脏页时,InnoDB 存储引擎会检测该区内是否存在其它脏页,如果存在,则一并进行刷新,这样做得好处显而易见,可以将多个操作合并成一个操作,对于机械硬盘有着明显的优势,但对于固定硬盘,本事就有较高的IOPS,是否开启需要根据情况而定,
参数设置如下:
show varables like 'innodb_flush_neighbors'
3 sql 执行的逻辑
3.1 sql 执行
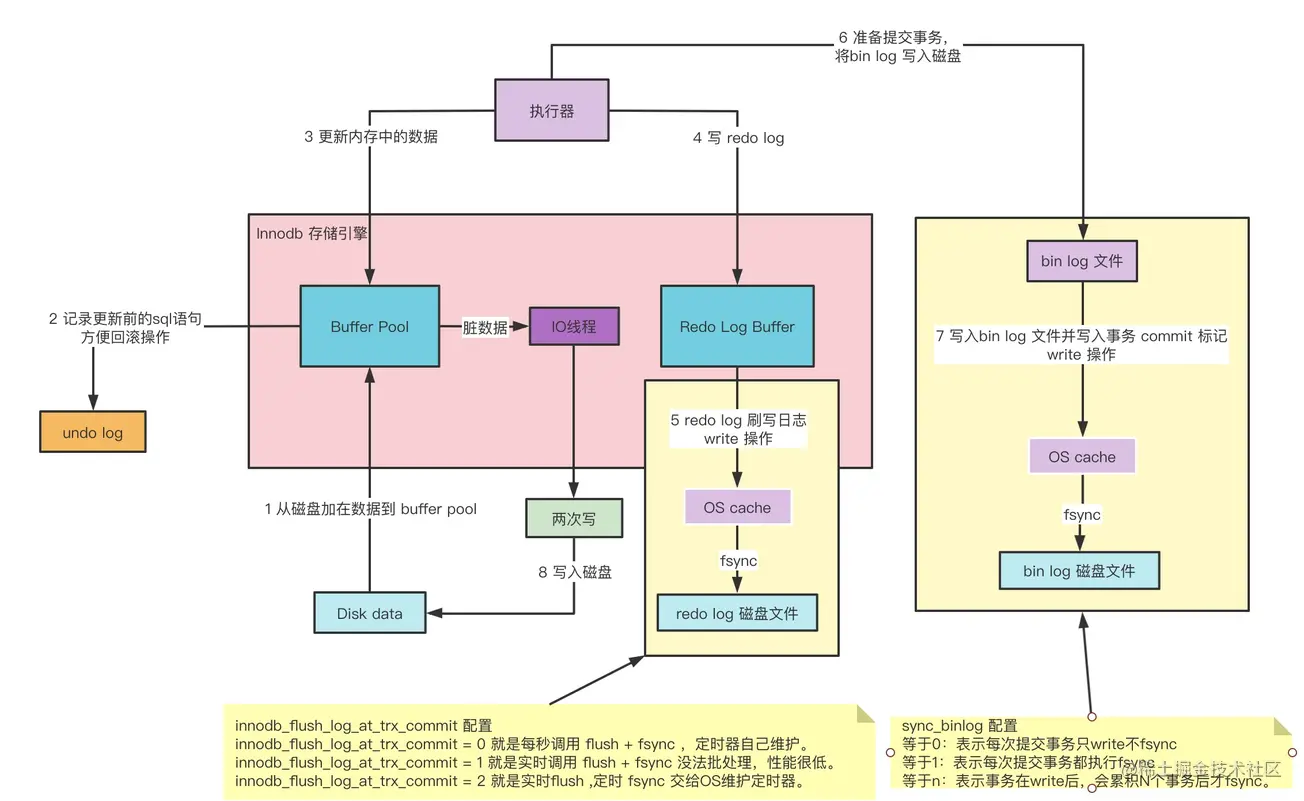
mysql写文件有2块缓存。一块是自己定义在内存的log buffer, 另一个是磁盘映射到内存的os cache。 mysql可以 调用 flush 主动将log buffer 刷新到磁盘内存映射,也可以调用 fsync 强制操作系同步磁盘映射文件到磁盘。默认情况下innodb_flush_log_at_trx_commit和sync_binlog 配置都为1。
不仅InnoDB引擎中有 buffer 的概念,这个是在用户空间中,而且在内核空间中也有 OS buffer的概念

还可以同时调用 flush + fsync, 将缓存直接落盘。innodb_flush_log_at_trx_commit = 0就是每秒调用 flush + fsync ,定时器自己维护。innodb_flush_log_at_trx_commit = 1就是实时调用 flush + fsync 没法批处理,性能很低。innodb_flush_log_at_trx_commit = 2就是实时flush ,定时 fsync 交给OS维护定时器。
sync_binlog 配置
等于0:表示每次提交事务只write不fsync
等于1:表示每次提交事务都执行fsync
等于n:表示事务在write后,会累积N个事务后才fsync。
show variables like 'sync_binlog'; show variables like 'innodb_flush_log_at_trx_commit'; # 查看 mysql 正在执行的进程 show processlist
InnoDB引擎BufferPool、LogBuffer、OS Buffer、Log files 之间的关系。

mysql 在执行增删改sql时,InnoDB 引擎的执行步骤如下:
- 1 执行器拿到需要执行的sql,需要根据更新条件从磁盘中加载需要修改的数据到内存中,也就是存放在 buffer pool 中。
- 2 在修改对应的数据之前,需要将其数据进行备份,也就是将数据放进 undo log 中,方便在事务回滚时进行操作。
- 3 直接在内存中按照sql语句修改对应的值。
- 4 修改完后将按照修改后的数据写 redo log buffer。
- 5 将 redo log 的内容进行写盘操作,这一步的操作参见 innodb_flush_at_trx_commit 的配置,一般是先写入系统的缓存中,然后由操作系统DMA异步操作写入系统文件中。 flush 操作只是把系统内存中的数据写入操作系统的缓冲中,数据读写一般是由内核线程完成的,这一步是数据从用户线程转变成内核线程进行操作,在读写文件时,在磁盘文件和内存之间会有多级缓存,用于提高数据交换效率,这里的 os cache 起到的就是这个作用。
- 6 在写完redo log 后,然后进行 bin log 写入操作。
- 7 和 redo log 的操作类似,也是先写入 os cache 再有操作系统刷到磁盘文件中。sync_log 的配置如图所示。一般情况下,数据库innodb_flush_at_trx_commit 和 sync_log 配置都为 1。
- 8 在 redo log 和 bin log 写完后,就可以进行事务提交。在数据进行写盘操作时, InnoDB 采用两次写的方式进行写数据。
先写redo log 再写 bin log的原因: 由于mysql 是通过 bin log 进行复制传输的,如果先提交了 redo log,还没有写bin log时出现了宕机,mysql 实例恢复时根据 redo log进行恢复,就会造成 从库和主库之间的数据不一致。
二进制日志文件的记录格式为 statement、row 和 mixed,statement 模式就是直接执行sql,如果其中有函数操作(比如数据库时间设置为 now() )那就会造成数据不准确。row 模式就是同步所有行的数据,如果全表操作修改状态,那这种模式就不合适了,因此在数据同步时需要根据情况采用 mixed 的混合模式。
3.2 FreeList、LRU List 和 Flush List
Free List 空闲列表:
记录所有未被占用的数据页,按照顺序将加载到内存的数据放入buffer pool 中,并删除对应 Free List 中的节点
LRU List LRU 数据访问列表:
将冷热数据块连接起来,根据 LRU 算法进行维护。如果加载进内存的数据一次性放入列表头部,再不确定这批数据的热度情况下,会造成一部分数据的淘汰,mysql InnoDB 的做法是将数据放置在靠后的位置,如果数据在1s内被访问了,才能进入链表头部,即数据热区。
# 将新加载的数据放置在链表的位置 默认为 37 即5/8处, show variables like 'innodb_old_blocks_pct'; # 冷区数据间隔多久访问才放入链表的热端,默认为1000ms show variables like 'innodb_old_blocks_time';
Flush List 刷新脏页列表:
记录内存中修改的数据页,使用双向链表进行连接,在方便的时候做落盘操作。

InnoDB 中的 redo log 大小是固定的,在MYSQL数据库Innodb 引擎mvcc锁实现原理 中提到过 redo log 是保证事务持久性的,其文件个数也是可以根据需要进行配置,通过循环写文件的方式来实现的,当 write pos 追赶上 checkpoint 后,这个时候就不能再继续执行新的命令,需要把check point 往前推进,也就是把redo log 里的内容持久化,腾出空间继续写日志。
数据操作:

redo log buffer 循环写入 :

这里先写日志再写磁盘的关键点也是一个技术,Write-Ahead Logging(WAL技术)。
关于 redo log 的配置可以参见如下命令执行查看。
show variables like '%innodb_log%' ------- 执行结果 ------ innodb_log_buffer_size 16777216 innodb_log_checksums ON innodb_log_compressed_pages ON innodb_log_file_size 50331648 innodb_log_files_in_group 2 innodb_log_group_home_dir ./ innodb_log_write_ahead_size 8192 innodb_log_buffer_size 为内存中 redo log buffer 的大小,16777216/1024/1024=16MB innodb_log_file_size 为每个redo log 的大小,50331648/1024/1024=48MB innodb_log_files_in_group 为 redo log 文件组中文件的个数,默认为2个 查看数据库表状态 show table status like 'my_table';
到此这篇关于Mysql InnoDB 的内存结构详情的文章就介绍到这了,更多相关Mysql InnoDB 内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
MySQL两种表存储结构MyISAM和InnoDB的性能比较测试
MySQL支持的两种主要表存储格式MyISAM,InnoDB,上个月做个项目时,先使用了InnoDB,结果速度特别慢,1秒钟只能插入10几条.后来换成MyISAM格式,一秒钟插入上万条.当时决定这两个表的性能也差别太大了吧.后来自己推测,不应该差别这么慢,估计是写的插入语句有问题,决定做个测试:测试环境:Redhat Linux9,4CPU,内存2G,MySQL版本为4.1.6-gamma-standard测试程序:Python+Python-MySQL模块.测试方案:1.MyISAM格式分别测
-
InnoDB 类型MySql恢复表结构与数据
前提:保存了需要恢复数据库的文件 .frm 和 .ibd 文件 条件:InnoDB 类型的 恢复表结构 1.新建一个数据库--新建一个表,表名和列数和需要恢复数据库相同 2.停止mysql服务器 service mysql stop , 3.在/usr/local/mysql/my.cnf 里面添加innodb_force_recovery = 6 4.将需要恢复的表.frm格式文件 覆盖/usr/local/mysql/data/数据库 下的.frm格式文件 5.启动mysql服务器 serv
-

Mysql InnoDB引擎的索引与存储结构详解
前言 在Oracle 和SQL Server等数据库中只有一种存储引擎,所有数据存储管理机制都是一样的. 而MySql数据库提供了多种存储引擎.用户可以根据不同的需求为数据表选择不同的存储引擎,用户也可以根据自己的需要编写自己的存储引擎. MySQL主要存储引擎的区别 MySQL默认的存储引擎是MyISAM,其他常用的就是InnoDB,另外还有MERGE.MEMORY(HEAP)等. 主要的几个存储引擎 MyISAM管理非事务表,提供高速存储和检索,以及全文搜索能力. MyISAM是Mysql的
-
MySQL Innodb 存储结构 和 存储Null值 用法详解
背景: 表空间:INNODB 所有数据都存在表空间当中(共享表空间),要是开启innodb_file_per_table,则每张表的数据会存到单独的一个表空间内(独享表空间). 独享表空间包括:数据,索引,插入缓存,数据字典.共享表空间包括:Undo信息(不会回收<物理空间上>),双写缓存信息,事务信息等. 段(segment):组成表空间,有区组成. 区(extent):有64个连续的页组成.每个页16K,总共1M.对于大的数据段,每次最后可申请4个区. 页(page):是INNODB 磁盘
-
MySQL的InnoDB存储引擎的数据页结构详解
目录 1InnoDB页的概念 2数据页的结构 3记录在页中的存储 4PageDirectory页目录 5FileHeader文件头部 6InnoDB页和记录的关系 7没有索引时查找记录 总结 1 InnoDB页的概念 InnoDB是一个将表中的数据存储在磁盘上的存储引擎,即使我们关闭并重启服务器,数据还是存在.而真正处理数据的过程发生在内存中,所以需要把磁盘中的数据加载到内存中,所以需要把磁盘中的数据加载到内存中.如果处理写入和修改请求,还需要将内存中的内容刷新到磁盘上.而我们知道读写磁盘的速度
-
Mysql InnoDB 的内存结构详情
目录 1 前言 2 InnoDB 存储引擎结构 2.1 InnoDB表存储引擎文件 2.2 InnoDB 预读机制 2.3 InnoDB 特性 2.3.1 插入缓存 2.3.2 二次写 (double write) 2.3.3 自适应hash索引 2.3.4 异步IO 2.3.5 刷新邻接页 3 sql 执行的逻辑 3.1 sql 执行 3.2 FreeList.LRU List 和 Flush List 1 前言 我们都熟悉mysql数据库服务架构,也清楚 sql 的执行顺序,mysql的数据
-
MySQL中Buffer Pool内存结构详情
目录 1.回顾一下Buffer Pool是个什么东西? 1.1 增删改直接操作的是内存还是磁盘? 1.2 数据库崩溃了,内存中数据丢了怎么办? 1.3 Buffer Pool的一句话总结 2.Buffer Pool这个内存数据结构到底长个什么样子? 2.1 如何配置MySQL的Buffer Pool的大小? 2.2 数据页 2.3 磁盘上的数据页和Buffer Pool中的数据页是如何对应起来的? 2.4 缓存页描述信息 1.回顾一下Buffer Pool是个什么东西? 1.1 增删改直接操作的
-
详解MySQL InnoDB存储引擎的内存管理
存储引擎之内存管理 在InnoDB存储引擎中,数据库中的缓冲池是通过LRU(Latest Recent Used,最近最少使用)算法来进行管理的,即最频繁使用的页在LRU列表的最前段,而最少使用的页在LRU列表的尾端,当缓冲池不能存放新读取到的页时,首先释放LRU列表尾端的页. 上面的图中,我使用8个数据页来表示队列,具体作用,先卖个关子.在InnoDB存储引擎中,缓冲池中页的默认大小是16KB,LRU列表中有一个midpoint的位置,新读取到的数据页并不是直接放入到LRU列表的首部,而是放入
-
Mysql InnoDB引擎中的数据页结构详解
目录 Mysql InnoDB引擎数据页结构 一.页的简介 二.数据页的结构 三.记录在页中的存储结构 四.记录头信息 1. deleted_flag 2. min_rec_flag 3. n_owned 4. heap_no 5. record_type 6. next_record Mysql InnoDB引擎数据页结构 InnoDB 是 mysql 的默认引擎,也是我们最常用的,所以基于 InnoDB,学习页结构.而学习页结构,是为了更好的学习索引. 一.页的简介 页是 InnoDB 管理
-
Mysql Innodb存储引擎之索引与算法
目录 一.概述 二.数据结构与算法 1.二分查找 2.二叉查找树和平衡二叉树 1)二叉查找树 2)平衡二叉树 三.B+树 1.B+树完整定义 2.关于 M 和 L的选定案例 四.B+树索引 1.聚集索引 2.辅助索引 五.关于 Cardinality 值 1.Cardinality定义 2.Cardinality的更新 六.B+树索引的使用 1.联合索引 2.覆盖索引 3.优化器选择不使用索引的情况 4.索引提示 5.Multi-Range Read 优化 (MRR) 6.Index Condi
-
MySQL InnoDB存储引擎的深入探秘
前言 在MySQL中InnoDB属于存储引擎层,并以插件的形式集成在数据库中.从MySQL5.5.8开始,InnoDB成为其默认的存储引擎.InnoDB存储引擎支持事务.其设计目标主要是面向OLTP的应用,主要特点有:支持事务.行锁设计支持高并发.外键支持.自动崩溃恢复.聚簇索引的方式组织表结构等. 体系架构 InnoDB存储引擎是由内存池.后台线程.磁盘存储三大部分组成. 线程 InnoDB 使用的是多线程模型, 其后台有多个不同的线程负责处理不同的任务 Master Thread Maste
-
MySQL Innodb关键特性之插入缓冲(insert buffer)
什么是insert buffer? 插入缓冲,也称之为insert buffer,它是innodb存储引擎的关键特性之一,我们经常会理解插入缓冲时缓冲池的一个部分,这样的理解是片面的,insert buffer的信息一部分在内存中,另外一部分像数据页一样,存在于物理页中. 在innodb中,我们知道,如果一个表有自增主键,那么对于这个表的默认插入是非常快的,注意,这里的主键是自增的,如果不是自增的,那么这个插入将会变成随机的,就可能带来数据页分裂的开销,这样,插入就不是顺序的,就会变慢.还有一种
-
MySQL InnoDB架构的相关总结
引言 作为一个后端程序员,我们几乎每天都要和数据库打交道,市面上的数据库有很多,比如:Mysql,Oracle,SqlServer等等,那么我们的写的程序是怎么和数据库连接起来的呢?那就是数据库驱动,不同的数据库对应了不同的数据库驱动.在我们连接数据库的时候,首先将数据库驱动进行注册,然后基于数据库地址,用户名,密码等信息与数据库建立连接.如果用maven来管理项目的话,一般会看到如下配置: <dependency> <groupId>mysql</groupId> &