Python爬取YY评级分数并保存数据实现过程解析
前言
当需要进行大规模查询时(比如目前遇到的情形:查询某个省所有发债企业的YY评级分数),人工查询显然太过费时,那就写个爬虫吧。
由于该爬虫实在过于简单,就只简单概述下。
一、请求端
通过观察YY评级的网页信息,如下图(F12或右击进入检查,点击network—>XHR—>headers)。
红色框表明是个get请求(其实这种网页基本都是Ajax get,需要总结实际url的规律的)。
绿色框即为实际URL,通过分析该URL,其由两部分组成。前半部分为“
https://web.ratingdog.cn/v1/search?”,后半部分为黄色框内内容用“&”符号连接后的结果。黄色框内的内容,只有企业名称为变量,且为已知变量,那URL即可据此确定了。

另外需注意,YY评级需要登录才可查询数据,在构建头部信息进行访问时,一定要提前登录,并在头部信息中放入登录信息和登录状态。
二、响应端
通过观察网页的响应信息(F12或右击进入检查,点击network—>XHR—>response),如下图。响应信息及其简单,我们所需要的YY评级分数安详地躺在那里,简单到一个正则表达式就可以提取出该数据。正则如下:
"msg".*?"IssuerName":"(.*?)","YYRating":"(.*?)/10","IntrinsicRating".*?"

三、代码
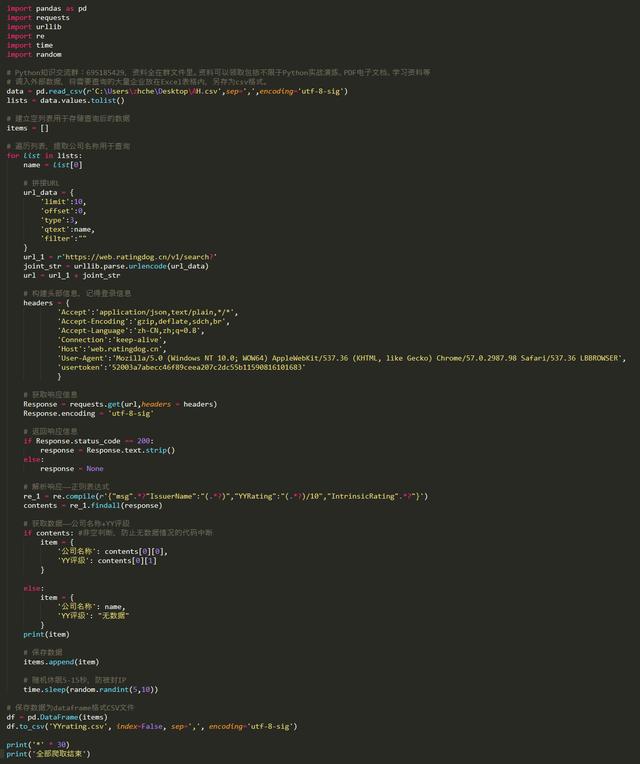
所需数据较少,代码相对简单,就不建立函数了,直接一路到底吧。如下:
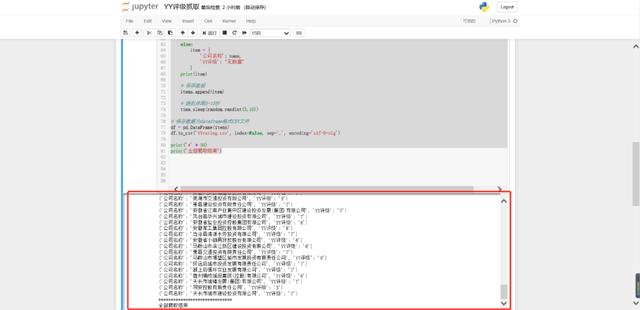
运行代码后,得到结果如下。安徽省的100多条数据,就到了本地了

以上就是本文的全部内容,希望对大家的学习有所帮助,也希望大家多多支持我们。
相关推荐
-

Python3爬虫学习之将爬取的信息保存到本地的方法详解
本文实例讲述了Python3爬虫学习之将爬取的信息保存到本地的方法.分享给大家供大家参考,具体如下: 将爬取的信息存储到本地 之前我们都是将爬取的数据直接打印到了控制台上,这样显然不利于我们对数据的分析利用,也不利于保存,所以现在就来看一下如何将爬取的数据存储到本地硬盘. 1 对.txt文件的操作 读写文件是最常见的操作之一,python3 内置了读写文件的函数:open open(file, mode='r', buffering=-1, encoding=None, errors=None,
-
Python爬取数据保存为Json格式的代码示例
python爬取数据保存为Json格式 代码如下: #encoding:'utf-8' import urllib.request from bs4 import BeautifulSoup import os import time import codecs import json #找到网址 def getDatas(): # 伪装 header={'User-Agent':"Mozilla/5.0 (X11; CrOS i686 2268.111.0) AppleWebKit/536.1
-
python requests库爬取豆瓣电视剧数据并保存到本地详解
首先要做的就是去豆瓣网找对应的接口,这里就不赘述了,谷歌浏览器抓包即可,然后要做的就是分析返回的json数据的结构: https://movie.douban.com/j/search_subjects?type=tv&tag=%E5%9B%BD%E4%BA%A7%E5%89%A7&sort=recommend&page_limit=20&page_start=0 这是接口地址,可以大概的分析一下各个参数的规则: type=tv,表示的是电视剧的分类 tag=国产剧,表示是
-
Python3直接爬取图片URL并保存示例
有时候我们会需要从网络上爬取一些图片,来满足我们形形色色直至不可描述的需求. 一个典型的简单爬虫项目步骤包括两步:获取网页地址和提取保存数据. 这里是一个简单的从图片url收集图片的例子,可以成为一个小小的开始. 获取地址 这些图片的URL可能是连续变化的,如从001递增到099,这种情况可以在程序中将共同的前面部分截取,再在最后递增并字符串化后循环即可. 抑或是它们的URL都保存在某个文件中,这时可以读取到列表中: def getUrls(path): urls = [] with open(
-
Python使用Scrapy爬虫框架全站爬取图片并保存本地的实现代码
大家可以在Github上clone全部源码. Github:https://github.com/williamzxl/Scrapy_CrawlMeiziTu Scrapy官方文档:http://scrapy-chs.readthedocs.io/zh_CN/latest/index.html 基本上按照文档的流程走一遍就基本会用了. Step1: 在开始爬取之前,必须创建一个新的Scrapy项目. 进入打算存储代码的目录中,运行下列命令: scrapy startproject CrawlMe
-
Python3爬虫爬取百姓网列表并保存为json功能示例【基于request、lxml和json模块】
本文实例讲述了Python3爬虫爬取百姓网列表并保存为json功能.分享给大家供大家参考,具体如下: python3爬虫之爬取百姓网列表并保存为json文件.这几天一直在学习使用python3爬取数据,今天记录一下,代码很简单很容易上手. 首先需要安装python3.如果还没有安装,可参考本站python3安装与配置相关文章. 首先需要安装requests和lxml和json三个模块 需要手动创建d.json文件 代码 import requests from lxml import etree
-
python爬取网站数据保存使用的方法
编码问题因为涉及到中文,所以必然地涉及到了编码的问题,这一次借这个机会算是彻底搞清楚了.问题要从文字的编码讲起.原本的英文编码只有0~255,刚好是8位1个字节.为了表示各种不同的语言,自然要进行扩充.中文的话有GB系列.可能还听说过Unicode和UTF-8,那么,它们之间是什么关系呢?Unicode是一种编码方案,又称万国码,可见其包含之广.但是具体存储到计算机上,并不用这种编码,可以说它起着一个中间人的作用.你可以再把Unicode编码(encode)为UTF-8,或者GB,再存储到计算机
-
Python3实现爬取指定百度贴吧页面并保存页面数据生成本地文档的方法
分享给大家供大家参考,具体如下:Python3实现爬取指定百度贴吧页面并保存页面数据生成本地文档的方法.分享给大家供大家参考,具体如下: 首先我们创建一个python文件, tieba.py,我们要完成的是,输入指定百度贴吧名字与指定页面范围之后爬取页面html代码,我们首先观察贴吧url的规律,比如: 百度贴吧LOL吧第一页:http://tieba.baidu.com/f?kw=lol&ie=utf-8&pn=0 第二页: http://tieba.baidu.com/f?kw=lol
-
Python爬取YY评级分数并保存数据实现过程解析
前言 当需要进行大规模查询时(比如目前遇到的情形:查询某个省所有发债企业的YY评级分数),人工查询显然太过费时,那就写个爬虫吧. 由于该爬虫实在过于简单,就只简单概述下. 一.请求端 通过观察YY评级的网页信息,如下图(F12或右击进入检查,点击network->XHR->headers). 红色框表明是个get请求(其实这种网页基本都是Ajax get,需要总结实际url的规律的). 绿色框即为实际URL,通过分析该URL,其由两部分组成.前半部分为" https://web.ra
-
如何使用python爬取知乎热榜Top50数据
目录 1.导入第三方库 2.程序的主函数 3.正则表达式匹配数据 4.程序运行结果 5.程序源代码 1.导入第三方库 import urllib.request,urllib.error #请求网页 from bs4 import BeautifulSoup # 解析数据 import sqlite3 # 导入数据库 import re # 正则表达式 import time # 获取当前时间 2.程序的主函数 def main(): # 声明爬取网页 baseurl = "https://ww
-
Python爬取商家联系电话以及各种数据的方法
上次学会了爬取图片,这次就想着试试爬取商家的联系电话,当然,这里纯属个人技术学习,爬取过后及时删除,不得用于其它违法用途,一切后果自负. 首先我学习时用的是114黄页数据. 下面四个是用到的模块,前面2个需要安装一下,后面2个是python自带的. import requests from bs4 import BeautifulSoup import csv import time 然后,写个函数获取到页面种想要的数据,记得最后的return返回一下,因为下面的函数要到把数据写到csv里面.
-
python爬取分析超级大乐透历史开奖数据第1/2页
博主作为爬虫初学者,本次使用了requests和beautifulsoup库进行数据的爬取 爬取网站:http://datachart.500.com/dlt/history/history.shtml -500彩票网 (分析后发现网站源代码并非是通过页面跳转来查找不同的数据,故可通过F12查找network栏找到真正储存所有历史开奖结果的网页) 如图: 爬虫部分: from bs4 import BeautifulSoup #引用BeautifulSoup库 import requests #
-
python爬取淘宝商品详情页数据
在讲爬取淘宝详情页数据之前,先来介绍一款 Chrome 插件:Toggle JavaScript (它可以选择让网页是否显示 js 动态加载的内容),如下图所示: 当这个插件处于关闭状态时,待爬取的页面显示的数据如下: 当这个插件处于打开状态时,待爬取的页面显示的数据如下: 可以看到,页面上很多数据都不显示了,比如商品价格变成了划线价格,而且累计评论也变成了0,说明这些数据都是动态加载的,以下演示真实价格的找法(评论内容找法类似),首先检查页面元素,然后点击Network选项卡,刷新页面,可
-
python爬取m3u8连接的视频
本文为大家分享了python爬取m3u8连接的视频方法,供大家参考,具体内容如下 要求:输入m3u8所在url,且ts视频与其在同一路径下 #!/usr/bin/env/python #_*_coding:utf-8_*_ #Data:17-10-08 #Auther:苏莫 #Link:http://blog.csdn.net/lingluofengzang #PythonVersion:python2.7 #filename:download_movie.py import os import
-
python爬取股票最新数据并用excel绘制树状图的示例
大家好,最近大A的白马股们简直 跌妈不认,作为重仓了抱团白马股基金的养鸡少年,每日那是一个以泪洗面啊. 不过从金融界最近一个交易日的大盘云图来看,其实很多中小股还是红色滴,绿的都是白马股们. 以下截图来自金融界网站-大盘云图: 那么,今天我们试着用python爬取最近交易日的股票数据,并试着用excel简单绘制以下上面这个树状图.本文旨在抛砖引玉,吼吼. 1. python爬取网易财经不同板块股票数据 目标网址: http://quotes.money.163.com/old/#query=hy
-
如何用python爬取微博热搜数据并保存
主要用到requests和bf4两个库 将获得的信息保存在d://hotsearch.txt下 import requests; import bs4 mylist=[] r = requests.get(url='https://s.weibo.com/top/summary?Refer=top_hot&topnav=1&wvr=6',timeout=10) print(r.status_code) # 获取返回状态 r.encoding=r.apparent_encoding demo