Python编程应用设计原则详解
目录
- 1、单一职责原则 SRP
- 2、开闭原则 OCP
- 3、里氏替换原则 (LSP)
- 4、接口隔离原则 (ISP)
- 5、依赖反转原则 (DIP)
- 最后的话
写出能用的代码很简单,写出好用的代码很难。
好用的代码,也都会遵循一此原则,这就是设计原则,它们分别是:
- 单一职责原则 (SRP)
- 开闭原则 (OCP)
- 里氏替换原则 (LSP)
- 接口隔离原则 (ISP)
- 依赖倒置原则 (DIP)
提取这五种原则的首字母缩写词,就是 SOLID 原则。下面分别进行介绍,并展示如何在 Python 中应用。
1、单一职责原则 SRP
单一职责原则(Single Responsibility Principle)这个原则的英文描述是这样的:A class or module should have a single responsibility。如果我们把它翻译成中文,那就是:一个类或者模块只负责完成一个职责(或者功能)。
让我们举一个更简单的例子,我们有一个数字 L = [n1, n2, …, nx] 的列表,我们计算一些数学函数。例如,计算最大值、平均值等。
一个不好的方法是让一个函数来完成所有的工作:
import numpy as np
def math_operations(list_):
# Compute Average
print(f"the mean is {np.mean(list_)}")
# Compute Max
print(f"the max is {np.max(list_)}")
math_operations(list_ = [1,2,3,4,5])
# the mean is 3.0
# the max is 5
实际开发中,你可以认为 math_operations 很庞大,揉杂了各种功能代码。
为了使这个更符合单一职责原则,我们应该做的第一件事是将函数 math_operations 拆分为更细粒度的函数,一个函数只干一件事:
def get_mean(list_):
'''Compute Max'''
print(f"the mean is {np.mean(list_)}")
def get_max(list_):
'''Compute Max'''
print(f"the max is {np.max(list_)}")
def main(list_):
# Compute Average
get_mean(list_)
# Compute Max
get_max(list_)
main([1,2,3,4,5])
# the mean is 3.0
# the max is 5
这样做的好处就是:
- 易读易调试,更容易定位错误。
- 可复用,代码的任何部分都可以在代码的其他部分中重用。
- 可测试,为代码的每个功能创建测试更容易。
但是要增加新功能,比如计算中位数,main 函数还是很难维护,因此还需要第二个原则:OCP。
2、开闭原则 OCP
开闭原则(Open Closed Principle)就是对扩展开放,对修改关闭,这可以大大提升代码的可维护性,也就是说要增加新功能时只需要添加新的代码,不修改原有的代码,这样做即简单,也不会影响之前的单元测试,不容易出错,即使出错也只需要检查新添加的代码。
上述代码,可以通过将我们编写的所有函数变成一个类的子类来解决这个问题。代码如下:
import numpy as np
from abc import ABC, abstractmethod
class Operations(ABC):
'''Operations'''
@abstractmethod
def operation():
pass
class Mean(Operations):
'''Compute Max'''
def operation(list_):
print(f"The mean is {np.mean(list_)}")
class Max(Operations):
'''Compute Max'''
def operation(list_):
print(f"The max is {np.max(list_)}")
class Main:
'''Main'''
def get_operations(list_):
# __subclasses__ will found all classes inheriting from Operations
for operation in Operations.__subclasses__():
operation.operation(list_)
if __name__ == "__main__":
Main.get_operations([1,2,3,4,5])
# The mean is 3.0
# The max is 5
如果现在我们想添加一个新的操作,例如:median,我们只需要添加一个继承自 Operations 类的 Median 类。新形成的子类将立即被 __subclasses__()接收,无需对代码的任何其他部分进行修改。
3、里氏替换原则 (LSP)
里式替换原则的英文是 Liskov Substitution Principle,缩写为 LSP。这个原则最早是在 1986 年由 Barbara Liskov 提出,他是这么描述这条原则的:
If S is a subtype of T, then objects of type T may be replaced with objects of type S, without breaking the program。
也就是说 子类对象能够替换程序中父类对象出现的任何地方,并且保证原来程序的逻辑行为不变及正确性不被破坏。
实际上,里式替换原则还有另外一个更加能落地、更有指导意义的描述,那就是按照协议来设计,子类在设计的时候,要遵守父类的行为约定(或者叫协议)。父类定义了函数的行为约定,那子类可以改变函数的内部实现逻辑,但不能改变函数原有的行为约定。这里的行为约定包括:函数声明要实现的功能;对输入、输出、异常的约定;甚至包括注释中所罗列的任何特殊说明。
4、接口隔离原则 (ISP)
接口隔离原则的英文翻译是 Interface Segregation Principle,缩写为 ISP。Robert Martin 在 SOLID 原则中是这样定义它的:Clients should not be forced to depend upon interfaces that they do not use。
直译成中文的话就是:客户端不应该被强迫依赖它不需要的接口。其中的 客户端 ,可以理解为接口的调用者或者使用者。
举个例子:
from abc import ABC, abstractmethod
class Mammals(ABC):
@abstractmethod
def swim(self) -> bool:
pass
@abstractmethod
def walk(self) -> bool:
pass
class Human(Mammals):
def swim(self)-> bool:
print("Humans can swim")
return True
def walk(self)-> bool:
print("Humans can walk")
return True
class Whale(Mammals):
def walk(self) -> bool:
print("Whales can't walk")
return False
def swim(self):
print("Whales can swim")
return True
human = Human()
human.swim()
human.walk()
whale = Whale()
whale.swim()
whale.walk()
执行结果:
Humans can swim
Humans can walk
Whales can swim
Whales can't walk
事实上,子类鲸鱼不应该依赖它不需要的接口 walk,针对这种情况,就需要对接口进行拆分,代码如下:
from abc import ABC, abstractmethod
class Swimer(ABC):
@abstractmethod
def swim(self) -> bool:
pass
class Walker(ABC):
@abstractmethod
def walk(self) -> bool:
pass
class Human(Swimer,Walker):
def swim(self)-> bool:
print("Humans can swim")
return True
def walk(self)-> bool:
print("Humans can walk")
return True
class Whale(Swimer):
def swim(self):
print("Whales can swim")
return True
human = Human()
human.swim()
human.walk()
whale = Whale()
whale.swim()
5、依赖反转原则 (DIP)
依赖反转原则的英文翻译是 Dependency Inversion Principle,缩写为 DIP。英文描述:High-level modules shouldn't depend on low-level modules. Both modules should depend on abstractions. In addition, abstractions shouldn't depend on details. Details depend on abstractions。
我们将它翻译成中文,大概意思就是:高层模块不要依赖低层模块。高层模块和低层模块应该通过抽象(abstractions)来互相依赖。除此之外,抽象不要依赖具体实现细节,具体实现细节依赖抽象。
在调用链上,调用者属于高层,被调用者属于低层,我们写的代码都属于低层,由框架来调用。在平时的业务代码开发中,高层模块依赖低层模块是没有任何问题的,但是在框架层面设计的时候,就要考虑通用性,高层应该依赖抽象的接口,低层应该实现对应的接口。如下图所示:
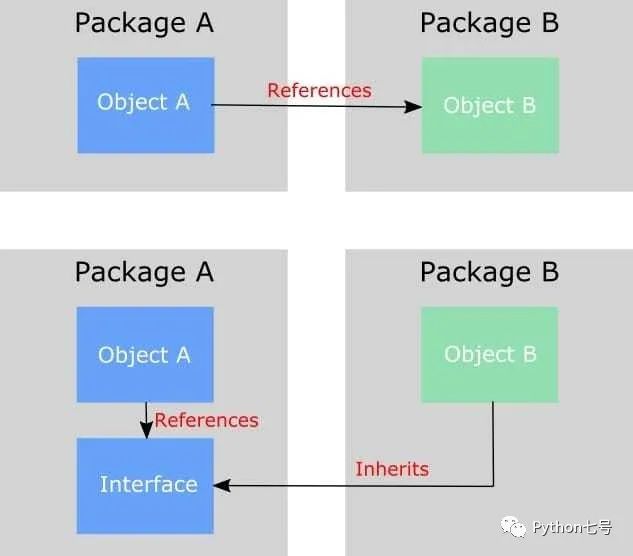
也就是说本来 ObjectA 依赖 ObjectB,但为了扩展后面可能会有 ObjectC,ObjectD,经常变化,因此为了频繁改动,让高层模块依赖抽象的接口 interface,然后让 ObjectB 也反过来依赖 interface,这就是依赖反转原则。
举个例子,wsgi 协议就是一种抽象接口,高层模块有 uWSGI,gunicorn等,低层模块有 Django,Flask 等,uWSGI,gunicorn 并不直接依赖 Django,Flask,而是通过 wsgi 协议进行互相依赖。
依赖倒置原则概念是高层次模块不依赖于低层次模块。看似在要求高层次模块,实际上是在规范低层次模块的设计。低层次模块提供的接口要足够的抽象、通用,在设计时需要考虑高层次模块的使用种类和场景。明明是高层次模块要使用低层次模块,对低层次模块有依赖性。现在反而低层次模块需要根据高层次模块来设计,出现了「倒置」的显现。
这样设计好处有两点:
- 低层次模块更加通用,适用性更广
- 高层次模块没有依赖低层次模块的具体实现,方便低层次模块的替换
最后的话
我去年(2020)年 2 月 3 号购买的《设计模式之美》专栏,将近一年半才把它学习完,再回看之前的代码,真是一堆垃圾。之前一天写完的代码,重构差不多花了一个星期,重构之后,感觉还可以再重构的更好,似乎无止境,正如小争哥说的那样,项目无论大小,都可以有技术含量,所谓代码细节是魔鬼,细节到处都存在在取舍,应该怎么样,不应该怎么样,都大有学问。
以上就是Python编程应用设计原则详解的详细内容,更多关于Python编程应用设计原则的资料请关注我们其它相关文章!
相关推荐
-
对Python函数设计规范详解
Python函数的设计规范 1.Python函数设计时具备耦合性和聚合性 1).耦合性: (1).尽可能通过参数接受输入,以及通过return产生输出以保证函数的独立性: (2).尽量减少使用全局变量进行函数间通信: (3).不要在函数中直接修改可变类型的参数: (4).避免直接改变定义在另外一个模块中的变量: 2).聚合性: (1).每个函数都应该有一个单一的.目的统一的目标: (2).每个函数的功能都应该相对简单: 2.Python函数在脚本中应用示例 例1:将/etc/passwd文件中的
-

Python的设计模式编程入门指南
有没有想过设计模式到底是什么?通过本文可以看到设计模式为什么这么重要,通过几个Python的示例展示为什么需要设计模式,以及如何使用. 设计模式是什么? 设计模式是经过总结.优化的,对我们经常会碰到的一些编程问题的可重用解决方案.一个设计模式并不像一个类或一个库那样能够直接作用于我们的代码.反之,设计模式更为高级,它是一种必须在特定情形下实现的一种方法模板.设计模式不会绑定具体的编程语言.一个好的设计模式应该能够用大部分编程语言实现(如果做不到全部的话,具体取决于语言特性).最为重要的是,设计模
-
详解设计模式中的工厂方法模式在Python程序中的运用
工厂方法(Factory Method)模式又称为虚拟构造器(Virtual Constructor)模式或者多态工厂(Polymorphic Factory)模式,属于类的创建型模式.在工厂方法模式中,父类负责定义创建对象的公共接口,而子类则负责生成具体的对象,这样做的目的是将类的实例化操作延迟到子类中完成,即由子类来决定究竟应该实体化哪一个类. 在简单工厂模式中,一个工厂类处于对产品类进行实例化的中心位置上,它知道每一个产品类的细节,并决定何时哪一个产品类应当被实例化.简单工厂模式的优点是能
-
Python PO设计模式的具体使用
无规矩不成方圆.编写代码也是,如果没有大概的框架,管理代码将会是一件很头疼的事. 先看看笔者以前写的python脚本: 如果只有一个用例,这样看着好像挺整洁的.但是当用例越来越多后,如果元素定位发生了改变,那你将要在多个类.多个方法中,去寻找那个元素,然后一个一个修改,这将耗费很多时间. 引入PO设计模式后,管理代码将会很轻松. 什么是PO设计模式? PO设计模式是一种业务流程与页面元素操作分离的模式:这意味着,当UI发生变化,元素定位发生变化时,只需要在一个地方修改即可. 下面是代码目录: 页
-
Python编程应用设计原则详解
目录 1.单一职责原则 SRP 2.开闭原则 OCP 3.里氏替换原则 (LSP) 4.接口隔离原则 (ISP) 5.依赖反转原则 (DIP) 最后的话 写出能用的代码很简单,写出好用的代码很难. 好用的代码,也都会遵循一此原则,这就是设计原则,它们分别是: 单一职责原则 (SRP) 开闭原则 (OCP) 里氏替换原则 (LSP) 接口隔离原则 (ISP) 依赖倒置原则 (DIP) 提取这五种原则的首字母缩写词,就是 SOLID 原则.下面分别进行介绍,并展示如何在 Python 中应用. 1.
-
ChatGPT编程秀之最小元素的设计示例详解
目录 膨胀的野心与现实的窘境 新时代,新思路 总结一下 膨胀的野心与现实的窘境 上一节随着我能抓openai的列表之后,我的野心开始膨胀,既然我们写了一个框架,可以开始写面向各网站的爬虫了,为什么只面向ChatGPT呢?几乎所有的平台都是这么个模式,一个列表,然后逐个抓取.那我能不能把这个能力泛化呢?可不可以设计一套机制,让所有的抓取功能都变得很简单呢?我抽取一系列的基础能力,而不管抓哪个网站只需要复用这些能力就可以快速的开发出爬虫.公司内的各种平台都是这么想的对吧? 那么我们就需要进行设计建模
-
Python面向对象编程repr方法示例详解
目录 为什么要讲 __repr__ 重写 __repr__ 方法 str() 和 repr() 的区别 为什么要讲 __repr__ 在 Python 中,直接 print 一个实例对象,默认是输出这个对象由哪个类创建的对象,以及在内存中的地址(十六进制表示) 假设在开发调试过程中,希望使用 print 实例对象时,输出自定义内容,就可以用 __repr__ 方法了 或者通过 repr() 调用对象也会返回 __repr__ 方法返回的值 是不是似曾相识....没错..和 __str__ 一样的
-
java面向对象设计原则之单一职责与依赖倒置原则详解
目录 单一职责概念 实现 拓展 依赖倒置原则概念 示例 拓展 单一职责概念 不要存在多于一个导致类变更的原因,也就是说每个类应该实现单一的职责,否则就应该把类拆分.交杂不清的职责将使得代码牵一发而动全身,导致代码混涩难懂,不易修改.难以扩展和复用.如:以前开发C/S程序中的胖客户端程序,就是将人机交互逻辑.业务加工处理逻辑和数据库操作逻辑混合在一起. 实现 单一职责原则是进行类的划分和封装的基本原则,进行类的具体抽象.尽量做到,类的功能单一和清晰化. 1.根据机能划分,使用封装来创建对象之间的分
-
总结的几个Python函数方法设计原则
在任何编程语言中,函数的应用主要出于以下两种情况: 1.代码块重复,这时候必须考虑用到函数,降低程序的冗余度 2.代码块复杂,这时候可以考虑用到函数,增强程序的可读性 当流程足够繁杂时,就要考虑函数,及如何将函数组合在一起.在Python中做函数设计,主要考虑到函数大小.聚合性.耦合性三个方面,这三者应该归结于规划与设计的范畴.高内聚.低耦合则是任何语言函数设计的总体原则. 1.如何将任务分解成更有针对性的函数从而导致了聚合性 2.如何设计函数间的通信则又涉及到耦合性 3.如何设计函数的大小用以
-
对Python中的@classmethod用法详解
在Python面向对象编程中的类构建中,有时候会遇到@classmethod的用法. 总感觉有这种特殊性说明的用法都是高级用法,在我这个层级的水平中一般是用不到的. 不过还是好奇去查了一下. 大致可以理解为:使用了@classmethod修饰的方法是类专属的,而且是可以通过类名进行调用的.为了能够展示其与一般方法的差异,写一段简单的代码如下: class DemoClass: @classmethod def classPrint(self): print("class method"
-
python 多进程和多线程使用详解
进程和线程 进程是系统进行资源分配的最小单位,线程是系统进行调度执行的最小单位: 一个应用程序至少包含一个进程,一个进程至少包含一个线程: 每个进程在执行过程中拥有独立的内存空间,而一个进程中的线程之间是共享该进程的内存空间的: 计算机的核心是CPU,它承担了所有的计算任务.它就像一座工厂,时刻在运行. 假定工厂的电力有限,一次只能供给一个车间使用.也就是说,一个车间开工的时候,其他车间都必须停工.背后的含义就是,单个CPU一次只能运行一个任务.编者注: 多核的CPU就像有了多个发电厂,使多工厂
-
Python入门之基础语法详解
一.我的经历及目标 在学习python之前:我学习过C/C++,在学校期间做过很多的项目,已经有两年多了,算是对C/C++非常的熟悉了,精通不敢说,但是对于面向过程和面向对象有很深刻的认识,做过很多的开发,学习数据库,MFC, QT, linux下利用C/C++进行服务器的开发,QT环境下进行模拟QQ的开发- 听说python挺火的,我也来尝试一门新的语言,python和c有80%的相似性,毕竟是用C来开发的语言,但是是面向过程的一门语言,有C++的继承等相似的特性,感觉更有信心学会它了,毕竟可
-
python面向对象之类的继承详解
一.概述 面向对象编程 (OOP) 语言的一个主要功能就是"继承".继承是指这样一种能力:它可以使用现有类的所有功能,并在无需重新编写原来的类的情况下对这些功能进行扩展. 通过继承创建的新类称为"子类"或"派生类",被继承的类称为"基类"."父类"或"超类",继承的过程,就是从一般到特殊的过程.在某些 OOP 语言中,一个子类可以继承多个基类.但是一般情况下,一个子类只能有一个基类,要实
-
关系型数据库的设计规则详解
目录 表关系设计 1.一对一关联(one-to-one) 2.一对多关系(one-to-many) 3.多对多(many-to-many) 4.自我引用(Self reference) E-R(Entity-relationship,实体-联系)模型中有三个主要概念是:实体集.属性.联系集. 一个实体集(class)对应于数据库中的一个表,一个实体(instance)则对应数据库表中的一行,也称一条记录.一个属性对应于数据库表中的一列(column),也称一个字段. ORM思想(Object R