一小时学会TensorFlow2之大幅提高模型准确率
目录
- 过拟合
- Regulation
- 公式
- 例子
- 动量
- 公式
- 例子
- 学习率递减
- 过程
- 例子
- Early Stopping
- Dropout
过拟合
当训练集的的准确率很高, 但是测试集的准确率很差的时候就, 我们就遇到了过拟合 (Overfitting) 的问题. 如图:
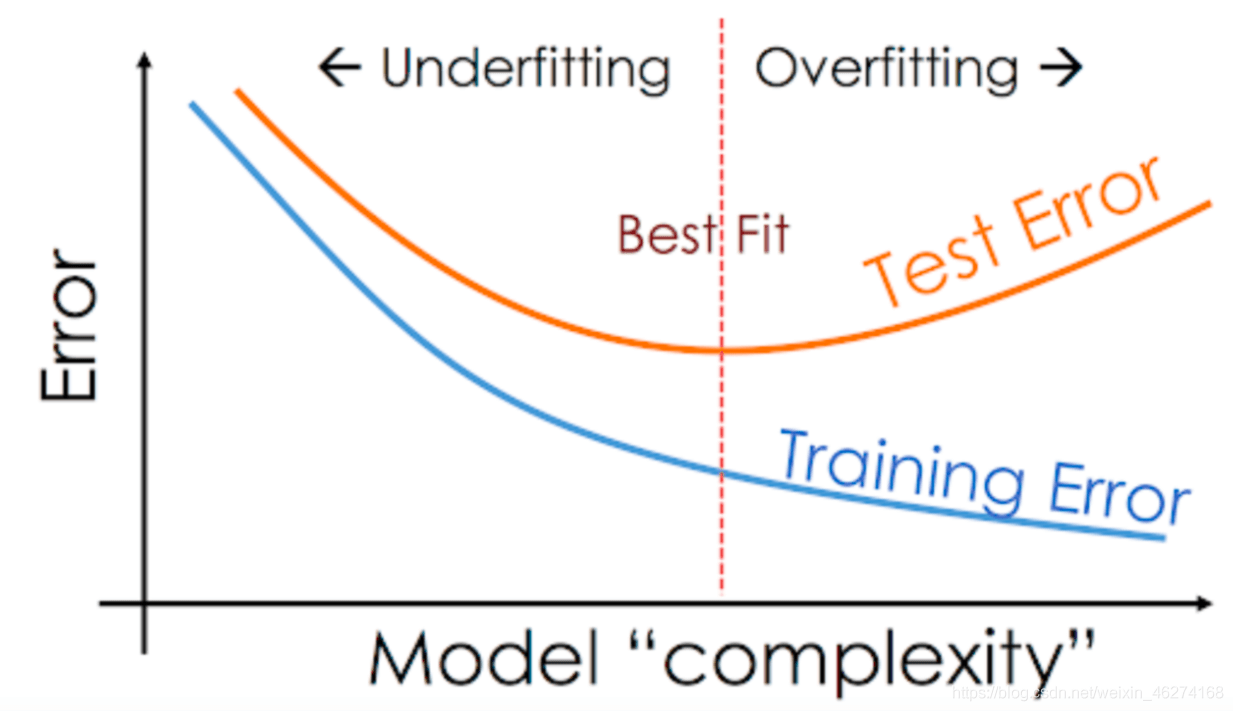
过拟合产生的一大原因是因为模型过于复杂. 下面我们将通过讲述 5 种不同的方法来解决过拟合的问题, 从而提高模型准确度.
Regulation
Regulation 可以帮助我们通过约束要优化的参数来防止过拟合.
公式
未加入 regulation 的损失:
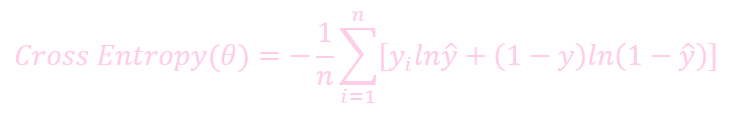
加入 regulation 的损失:

λ 和 lr (learning rate) 类似. 如果 λ 的值越大, regularion 的力度也就越强, 权重的值也就越小.
例子
添加了 l2 regulation 的网络:
network = tf.keras.Sequential([
tf.keras.layers.Dense(256, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(128, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(64, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(32, kernel_regularizer=tf.keras.regularizers.l2(0.001), activation=tf.nn.relu),
tf.keras.layers.Dense(10)
])
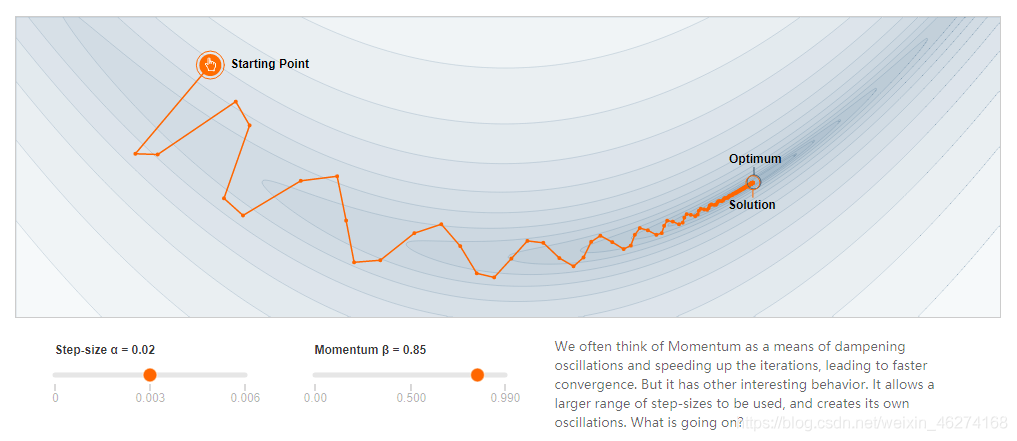
动量
动量 (Momentum) 是指运动物体的租用效果. 在梯度下降的过程中, 通过在优化器中加入动量, 我们可以减少摆动从而达到更优的效果.
未添加动量:
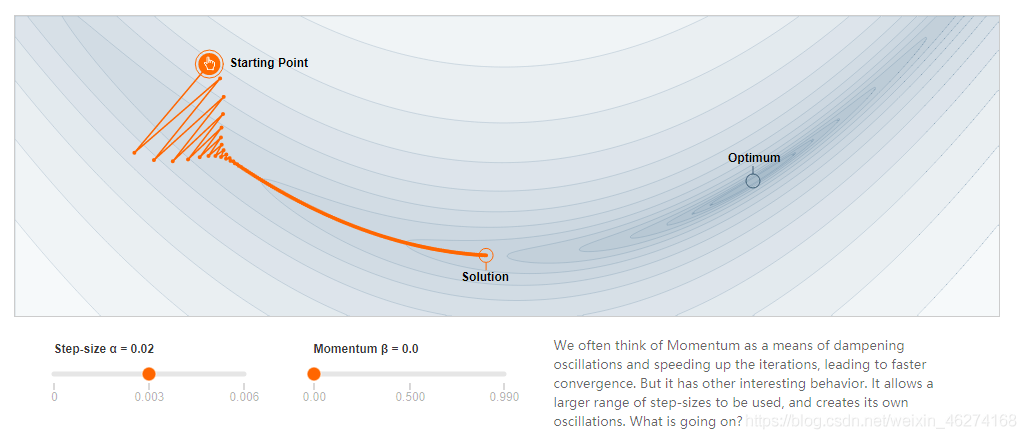
添加动量:
公式
未加动量的权重更新:
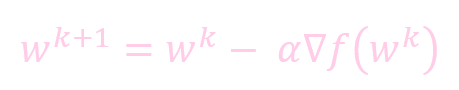
- w: 权重 (weight)
- k: 迭代的次数
- α: 学习率 (learning rate)
- ∇f(): 微分
添加动量的权重更新:

- β: 动量权重
- z: 历史微分
例子
添加了动量的优化器:
optimizer = tf.keras.optimizers.SGD(learning_rate=0.02, momentum=0.9) optimizer = tf.keras.optimizers.RMSprop(learning_rate=0.02, momentum=0.9)
注: Adam 优化器默认已经添加动量, 所以无需自行添加.
学习率递减
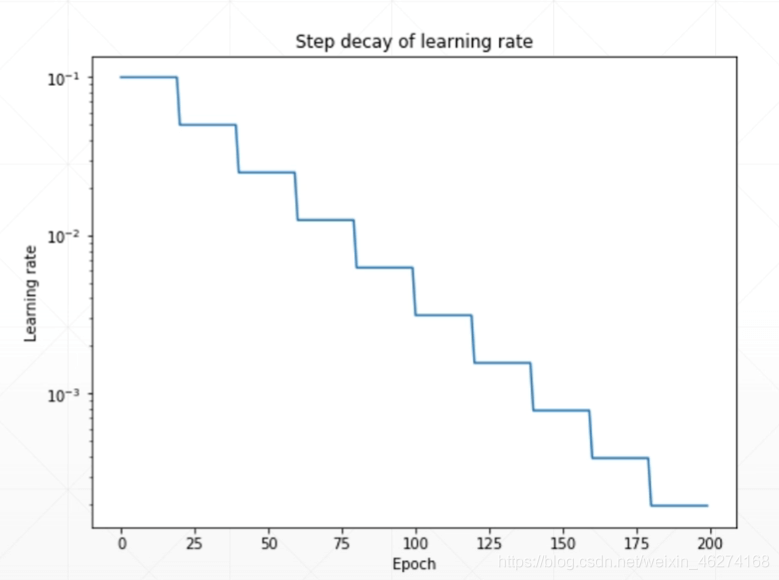
简单的来说, 如果学习率越大, 我们训练的速度就越大, 但找到最优解的概率也就越小. 反之, 学习率越小, 训练的速度就越慢, 但找到最优解的概率就越大.

过程
我们可以在训练初期把学习率调的稍大一些, 使得网络迅速收敛. 在训练后期学习率小一些, 使得我们能得到更好的收敛以获得最优解. 如图:
例子
learning_rate = 0.2 # 学习率
optimizer = tf.keras.optimizers.SGD(learning_rate=learning_rate, momentum=0.9) # 优化器
# 迭代
for epoch in range(iteration_num):
optimizer.learninig_rate = learning_rate * (100 - epoch) / 100 # 学习率递减
Early Stopping
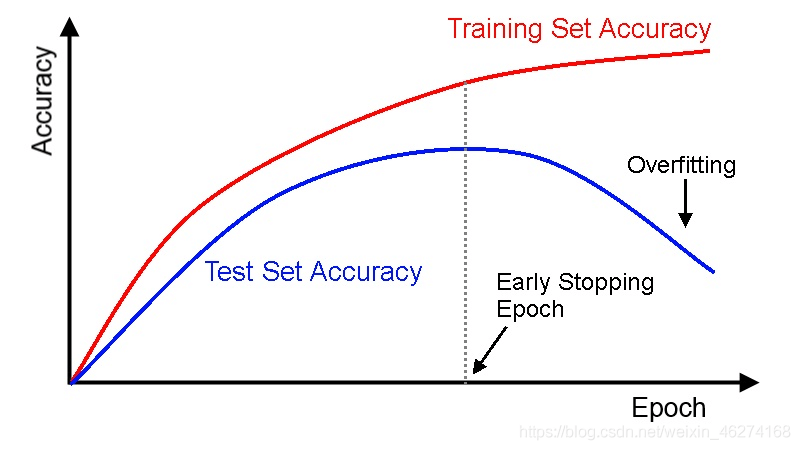
之前我们提到过, 当训练集的准确率仍在提升, 但是测试集的准确率反而下降的时候, 我们就遇到了过拟合 (overfitting) 的问题.
Early Stopping 可以帮助我们在测试集的准确率下降的时候停止训练, 从而避免继续训练导致的过拟合问题.
Dropout
Learning less to learn better
Dropout 会在每个训练批次中忽略掉一部分的特征, 从而减少过拟合的现象.
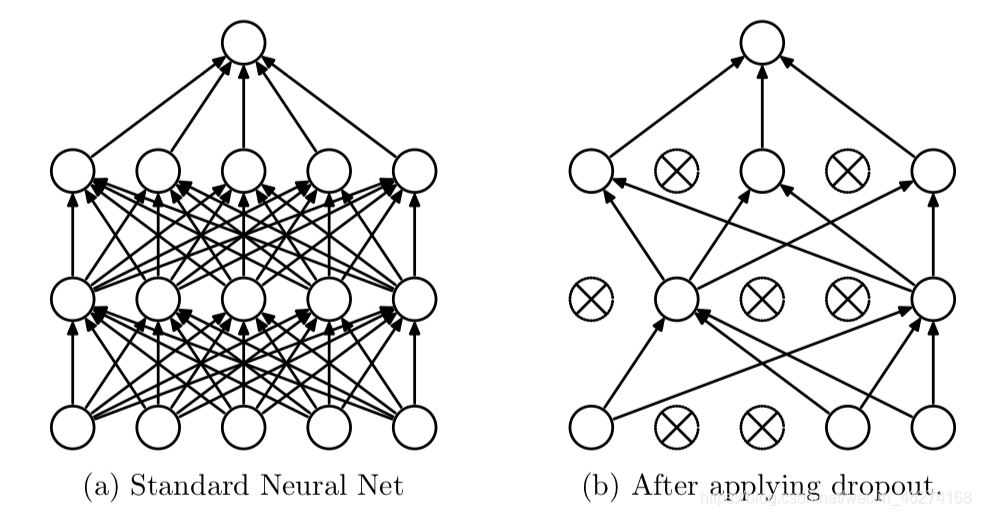
dropout, 通过强迫神经元, 和随机跳出来的其他神经元共同工作, 达到好的效果. 消除减弱神经元节点间的联合适应性, 增强了泛化能力.
例子:
network = tf.keras.Sequential([
tf.keras.layers.Dense(256, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(128, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(64, activation=tf.nn.relu),
tf.keras.layers.Dropout(0.5), # 忽略一半
tf.keras.layers.Dense(32, activation=tf.nn.relu),
tf.keras.layers.Dense(10)
])
到此这篇关于一小时学会TensorFlow2之大幅提高模型准确率的文章就介绍到这了,更多相关TensorFlow2模型准确率内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
如何将tensorflow训练好的模型移植到Android (MNIST手写数字识别)
[尊重原创,转载请注明出处]https://blog.csdn.net/guyuealian/article/details/79672257 项目Github下载地址:https://github.com/PanJinquan/Mnist-tensorFlow-AndroidDemo 本博客将以最简单的方式,利用TensorFlow实现了MNIST手写数字识别,并将Python TensoFlow训练好的模型移植到Android手机上运行.网上也有很多移植教程,大部分是在Ubuntu(Linu
-
TensorFlow2.X使用图片制作简单的数据集训练模型
Tensorflow内置了许多数据集,但是实际自己应用的时候还是需要使用自己的数据集,这里TensorFlow 官网也给介绍文档,官方文档.这里对整个流程做一个总结(以手势识别的数据集为例). 1. 收集手势图片 数据集下载 方法多种多样了.我通过摄像头自己采集了一些手势图片.保存成如下形式, 以同样的形式在建立一个测试集,当然也可以不弄,在程序里处理. 2.构建数据集 导入相关的包 import tensorflow as tf from tensorflow import keras fro
-

入门tensorflow教程之TensorBoard可视化模型训练
TensorBoard是用于可视化图形 和其他工具以理解.调试和优化模型的界面. 它是一种为机器学习工作流提供测量和可视化的工具. 它有助于跟踪损失和准确性.模型图可视化.低维空间中的项目嵌入等指标. 下面,我们使用MNIST 数据的图像分类模型 ,将首先导入所需的库并加载数据集. 模型的建立使用最简单的顺序模型 import tensorflow as tf (X_train, y_train), (X_test, y_test) = tf.keras.datasets.mnist.load_
-
TensorFlow2.0使用keras训练模型的实现
1.一般的模型构造.训练.测试流程 # 模型构造 inputs = keras.Input(shape=(784,), name='mnist_input') h1 = layers.Dense(64, activation='relu')(inputs) h1 = layers.Dense(64, activation='relu')(h1) outputs = layers.Dense(10, activation='softmax')(h1) model = keras.Model(inp
-
一小时学会TensorFlow2之大幅提高模型准确率
目录 过拟合 Regulation 公式 例子 动量 公式 例子 学习率递减 过程 例子 Early Stopping Dropout 过拟合 当训练集的的准确率很高, 但是测试集的准确率很差的时候就, 我们就遇到了过拟合 (Overfitting) 的问题. 如图: 过拟合产生的一大原因是因为模型过于复杂. 下面我们将通过讲述 5 种不同的方法来解决过拟合的问题, 从而提高模型准确度. Regulation Regulation 可以帮助我们通过约束要优化的参数来防止过拟合. 公式 未加入 r
-
一小时学会TensorFlow2之Fashion Mnist
目录 描述 Tensorboard 创建 summary 存入数据 metrics metrics.Mean() metrics.Accuracy() 变量更新 &重置 案例 pre_process 函数 get_data 函数 train 函数 test 函数 main 函数 完整代码 可视化 描述 Fashion Mnist 是一个类似于 Mnist 的图像数据集. 涵盖 10 种类别的 7 万 (6 万训练集 + 1 万测试集) 个不同商品的图片. Tensorboard Tensorbo
-
一小时学会TensorFlow2之全连接层
目录 概述 keras.layers.Dense keras.Squential 概述 全链接层 (Fully Connected Layer) 会把一个特质空间线性变换到另一个特质空间, 在整个网络中起到分类器的作用. keras.layers.Dense keras.layers.Dense可以帮助我们实现全连接. 格式: tf.keras.layers.Dense( units, activation=None, use_bias=True, kernel_initializer='glo
-
一小时学会TensorFlow2之自定义层
目录 概述 Sequential Model & Layer 案例 数据集介绍 完整代码 概述 通过自定义网络, 我们可以自己创建网络并和现有的网络串联起来, 从而实现各种各样的网络结构. Sequential Sequential 是 Keras 的一个网络容器. 可以帮助我们将多层网络封装在一起. 通过 Sequential 我们可以把现有的层已经我们自己的层实现结合, 一次前向传播就可以实现数据从第一层到最后一层的计算. 格式: tf.keras.Sequential( layers=No
-
一小时学会TensorFlow2之基本操作1实例代码
目录 概述 创建数据 创建常量 创建数据序列 创建图变量 tf.zeros tf.ones tf.zeros_like tf.ones_like tf.fill tf.gather tf.random 正态分布 均匀分布 打乱顺序 获取数据信息 获取数据维度 数据是否为张量 数据转换 转换成张量 转换数据类型 转换成 numpy 概述 TensorFlow2 的基本操作和 Numpy 的操作很像. 今天带大家来看一看 TensorFlow 的基本数据操作. 创建数据 详细讲解一下 TensorF
-
一小时学会TensorFlow2之基本操作2实例代码
目录 索引操作 简单索引 Numpy 式索引 使用 : 进行索引 tf.gather tf.gather_nd tf.boolean_mask 切片操作 简单切片 step 切片 维度变换 tf.reshape tf.transpose tf.expand_dims tf.squeeze Boardcasting tf.boardcast_to tf.tile 数学运算 加减乘除 log & exp pow & sqrt 矩阵相乘 @ 索引操作 简单索引 索引 (index) 可以帮助我们
-
Python入门教程 超详细1小时学会Python
为什么使用Python 假设我们有这么一项任务:简单测试局域网中的电脑是否连通.这些电脑的ip范围从192.168.0.101到192.168.0.200. 思路:用shell编程.(Linux通常是bash而Windows是批处理脚本).例如,在Windows上用ping ip 的命令依次测试各个机器并得到控制台输出.由于ping通的时候控制台文本通常是"Reply from ... " 而不通的时候文本是"time out ... " ,所以,在结果中进行
-
python 详解如何使用GPU大幅提高效率
cupy我觉得可以理解为cuda for numpy,安装方式pip install cupy,假设 import numpy as np import cupy as cp 那么对于np.XXX一般可以直接替代为cp.XXX. 其实numpy已经够快了,毕竟是C写的,每次运行的时候都会尽其所能地调用系统资源.为了验证这一点,我们可以用矩阵乘法来测试一下:在形式上通过多线程并发.多进程并行以及单线程的方式,来比较一下numpy的速度和对资源的调度情况,代码为 # th_pr_array.py f
-
mysql入门之1小时学会MySQL基础
MySQL入门 mySQL (关系型数据库管理系统) MySQL是一个关系型数据库管理系统,由瑞典MySQL AB 公司开发,目前属于 Oracle 旗下产品.MySQL 是最流行的关系型数据库管理系统之一,在 WEB 应用方面,MySQL是最好的 RDBMS (Relational Database Management System,关系数据库管理系统) 应用软件. MySQL是一种关系数据库管理系统,关系数据库将数据保存在不同的表中,而不是将所有数据放在一个大仓库内,这样就增加了速度并提高
-
一个小时学会MySQL数据库(张果)
随着移动互联网的结束与人工智能的到来大数据变成越来越重要,下一个成功者应该是拥有海量数据的,数据与数据库你应该知道. 一.数据库概要 数据库(Database)是存储与管理数据的软件系统,就像一个存入数据的物流仓库. 在商业领域,信息就意味着商机,取得信息的一个非常重要的途径就是对数据进行分析处理,这就催生了各种专业的数据管理软件,数据库就是其中的一种.当然,数据库管理系统也不是一下子就建立起来,它也是经过了不断的丰富和发展,才有了今天的模样. 1.1.发展历史 1.1.1.人工处理阶段 在20