Python爬虫scrapy框架Cookie池(微博Cookie池)的使用
下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址)
下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool
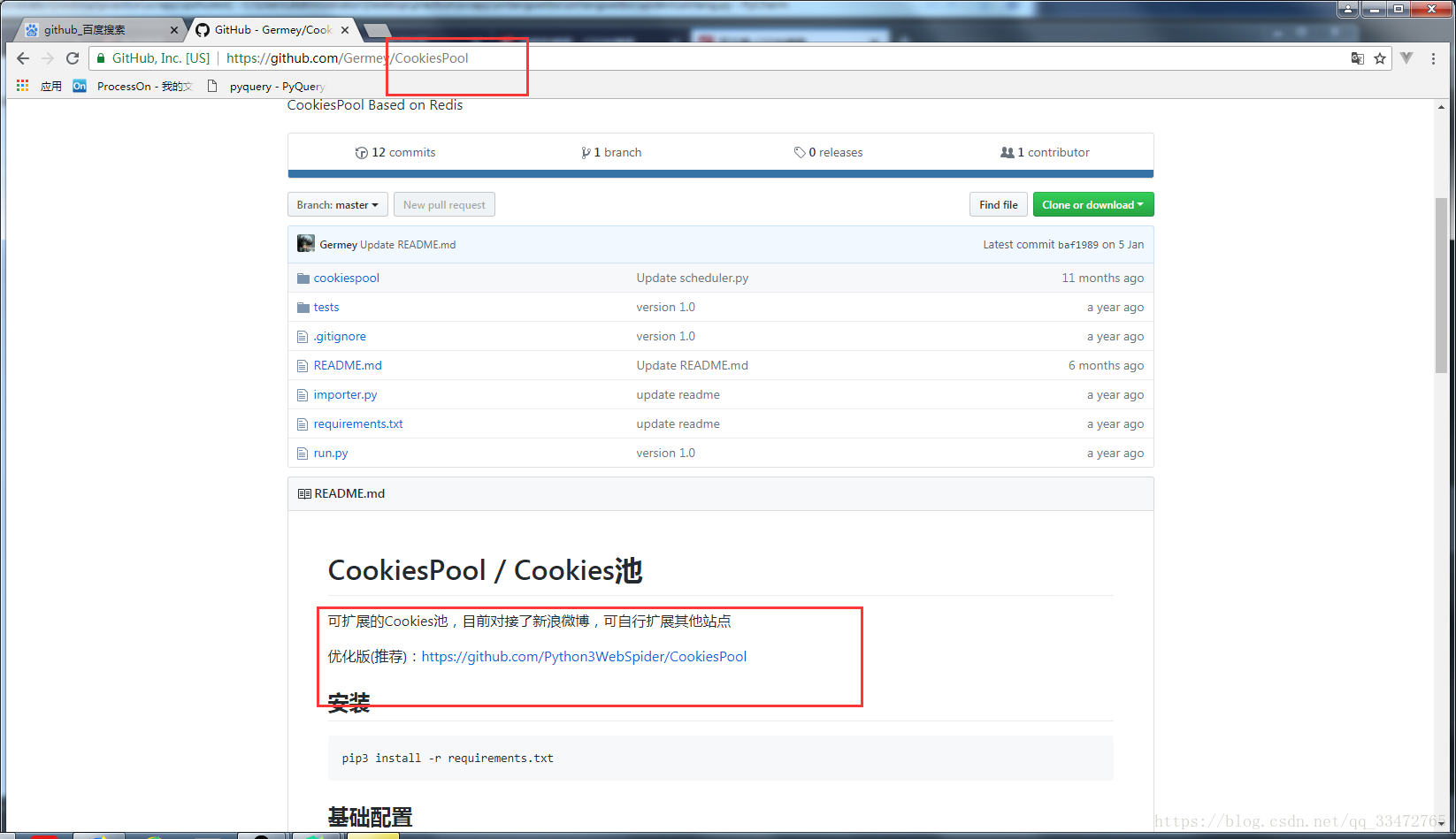
下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!!
自己的设置主要有下面几步:
1、配置其他设置
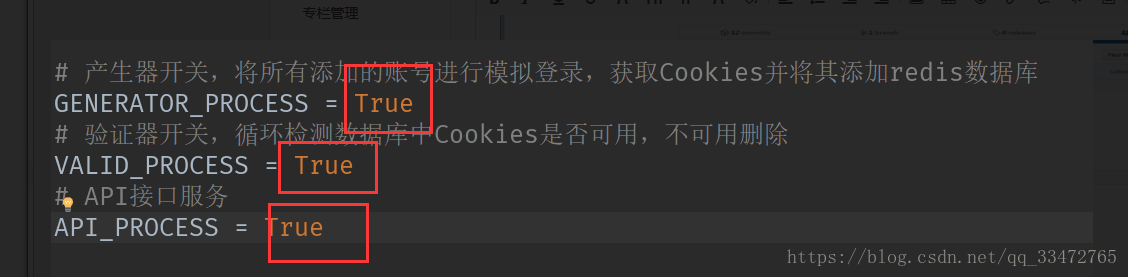
2、设置使用的浏览器


3、设置模拟登陆
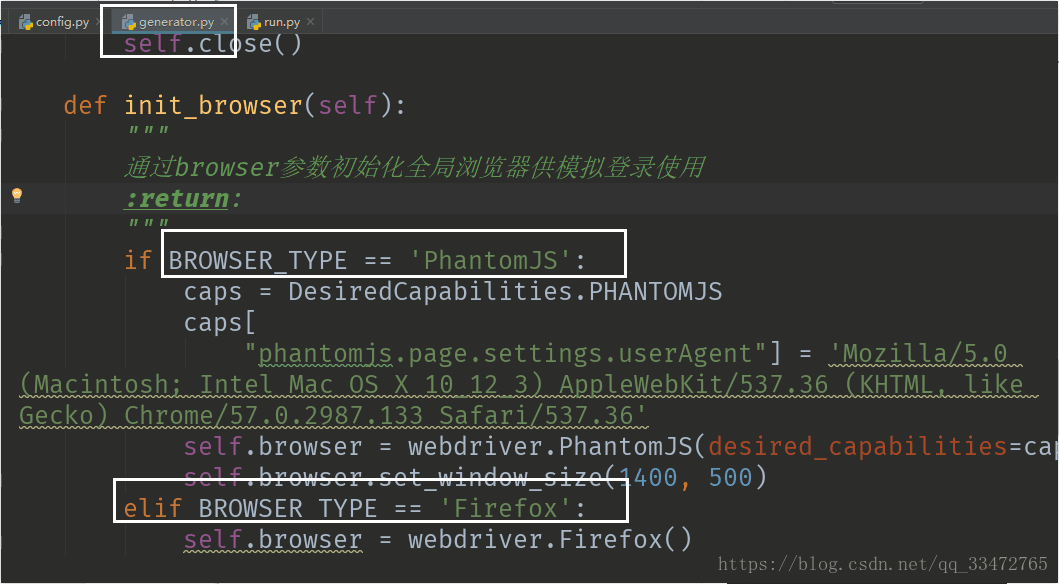
源码cookies.py的修改(以下两处不修改可能会产生bug):


4、获取cookie
随机获取Cookies: http://localhost:5000/weibo/random(注意:cookie使用时是需要后期处理的!!)

简单的处理方式,如下代码(偶尔需要对获取的cookie处理):
def get_cookie(self):
return requests.get('http://127.0.0.1:5000/weibo/random').text
def stringToDict(self,cookie):
itemDict = {}
items = cookie.replace(':', '=').split(',')
for item in items:
key = item.split('=')[0].replace(' ', '').strip(' "')
value = item.split('=')[1].strip(' "')
itemDict[key] = value
return itemDict
scrapy爬虫的使用示例(爬取微博):
middlewares.py中自定义请求中间件
def start_requests(self):
ua = UserAgent()
headers = {
'User-Agent': ua.random,
}
cookies = self.stringToDict(str(self.get_cookie().strip('{|}')))
yield scrapy.Request(url=self.start_urls[0], headers=headers,
cookies=cookies, callback=self.parse)
cookies = self.stringToDict(str(self.get_cookie().strip('{|}')))
yield scrapy.Request(url=self.start_urls[0], headers=headers,
cookies=cookies, callback=self.parse)
settings.py 中的配置:

5、录入账号和密码:

格式规定(账号----密码)

6、验证:(注意:使用cmd)

7、使用时注意保持cmd打开运行!!
使用时一定要打开cmd,并运行如第6步。
得到Cookie是判断是否处理处理Cookie(几乎都需要!!)类比第4步!!!
到此这篇关于Python爬虫scrapy框架Cookie池(微博Cookie池)的使用的文章就介绍到这了,更多相关scrapy Cookie池内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
scrapy中如何设置应用cookies的方法(3种)
本人是python3.6 总的来说,scrapy框架中设置cookie有三种方式. 第一种:setting文件中设置cookie 当COOKIES_ENABLED是注释的时候scrapy默认没有开启cookie 当COOKIES_ENABLED没有注释设置为False的时候scrapy默认使用了settings里面的cookie 当COOKIES_ENABLED设置为True的时候scrapy就会把settings的cookie关掉,使用自定义cookie 所以当我使用settings的cook
-
scrapy框架携带cookie访问淘宝购物车功能的实现代码
scrapy框架简介 Scrapy是用纯Python实现一个为了爬取网站数据.提取结构性数据而编写的应用框架,用途非常广泛 框架的力量,用户只需要定制开发几个模块就可以轻松的实现一个爬虫,用来抓取网页内容以及各种图片,非常之方便 scrapy架构图 crapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递等. Scheduler(调度器): 它负责接受引擎发送过来的Request请求,并按照一定的方式进行整
-
关于python scrapy中添加cookie踩坑记录
问题发现: 前段时间项目中,为了防止被封号(提供的可用账号太少),对于能不登录就可以抓取的内容采用不带cookie的策略,只有必要的内容才带上cookie去访问. 本来想着很简单:在每个抛出来的Request的meta中带上一个标志位,通过在CookieMiddleware中查看这个标志位,决定是否是给这个Request是否装上Cookie. 实现的代码大致如下: class CookieMiddleware(object): """ 每次请求都随机从账号池中选择一个账号去访
-

Python爬虫scrapy框架Cookie池(微博Cookie池)的使用
下载代码Cookie池(这里主要是微博登录,也可以自己配置置其他的站点网址) 下载代码GitHub:https://github.com/Python3WebSpider/CookiesPool 下载安装过后注意看网页下面的相关基础配置和操作!!!!!!!!!!!!! 自己的设置主要有下面几步: 1.配置其他设置 2.设置使用的浏览器 3.设置模拟登陆 源码cookies.py的修改(以下两处不修改可能会产生bug): 4.获取cookie 随机获取Cookies: http://localho
-
python爬虫Scrapy框架:媒体管道原理学习分析
目录 一.媒体管道 1.1.媒体管道的特性 媒体管道实现了以下特性: 图像管道具有一些额外的图像处理功能: 1.2.媒体管道的设置 二.ImagesPipeline类简介 三.小案例:使用图片管道爬取百度图片 3.1.spider文件 3.2.items文件 3.3.settings文件 3.4.pipelines文件 一.媒体管道 1.1.媒体管道的特性 媒体管道实现了以下特性: 避免重新下载最近下载的媒体 指定存储位置(文件系统目录,Amazon S3 bucket,谷歌云存储bucket)
-
python爬虫scrapy框架的梨视频案例解析
之前我们使用lxml对梨视频网站中的视频进行了下载,感兴趣的朋友点击查看吧. 下面我用scrapy框架对梨视频网站中的视频标题和视频页中对视频的描述进行爬取 分析:我们要爬取的内容并不在同一个页面,视频描述内容需要我们点开视频,跳转到新的url中才能获取,我们就不能在一个方法中去解析我们需要的不同内容 1.爬虫文件 这里我们可以仿照爬虫文件中的parse方法,写一个新的parse方法,可以将新的url的响应对象传给这个新的parse方法 如果需要在不同的parse方法中使用同一个item对象,可
-
Python爬虫Scrapy框架IP代理的配置与调试
目录 代理ip的逻辑在哪里 如何配置动态的代理ip 在调试爬虫的时候,新手都会遇到关于ip的错误,好好的程序突然报错了,怎么解决,关于ip访问的错误其实很好解决,但是怎么知道解决好了呢?怎么确定是代理ip的问题呢?由于笔者主修语言是Java,所以有些解释可能和Python大佬们的解释不一样,因为我是从Java 的角度看Python.这样也便于Java开发人员阅读理解. 代理ip的逻辑在哪里 一个scrapy 的项目结构是这样的 scrapydownloadertest # 项目文件夹 │ ite
-
python爬虫scrapy框架之增量式爬虫的示例代码
scrapy框架之增量式爬虫 一 .增量式爬虫 什么时候使用增量式爬虫: 增量式爬虫:需求 当我们浏览一些网站会发现,某些网站定时的会在原有的基础上更新一些新的数据.如一些电影网站会实时更新最近热门的电影.那么,当我们在爬虫的过程中遇到这些情况时,我们是不是应该定期的更新程序以爬取到更新的新数据?那么,增量式爬虫就可以帮助我们来实现 二 .增量式爬虫 概念: 通过爬虫程序检测某网站数据更新的情况,这样就能爬取到该网站更新出来的数据 如何进行增量式爬取工作: 在发送请求之前判断这个URL之前是不是
-
Python爬虫Scrapy框架CrawlSpider原理及使用案例
提问:如果想要通过爬虫程序去爬取"糗百"全站数据新闻数据的话,有几种实现方法? 方法一:基于Scrapy框架中的Spider的递归爬去进行实现的(Request模块回调) 方法二:基于CrawlSpider的自动爬去进行实现(更加简洁和高效) 一.简单介绍CrawlSpider CrawlSpider其实是Spider的一个子类,除了继承到Spider的特性和功能外,还派生除了其自己独有的更加强大的特性和功能.其中最显著的功能就是"LinkExtractors链接提取器&qu
-
Python爬虫 scrapy框架爬取某招聘网存入mongodb解析
创建项目 scrapy startproject zhaoping 创建爬虫 cd zhaoping scrapy genspider hr zhaopingwang.com 目录结构 items.py title = scrapy.Field() position = scrapy.Field() publish_date = scrapy.Field() pipelines.py from pymongo import MongoClient mongoclient = MongoClien
-
Python爬虫如何破解JS加密的Cookie
通过Fiddler抓包比较,基本可以确定是JavaScript生成加密Cookie导致原来的请求返回521. 发现问题: 打开Fiddler软件,用浏览器打开目标站点(http://www.kuaidaili.com/proxylist/2/) .可以发现浏览器对这个页面加载了两次,第一次返回521,第二次才正常返回数据.很多没有写过网站或是爬虫经验不足的童鞋,可能就会觉得奇怪为什么会这样?为什么浏览器可能正常返回数据而代码却不行? 仔细观察两次返回的结果可以发现: 1.第二次请求比第一次请求的
-
Python:Scrapy框架中Item Pipeline组件使用详解
Item Pipeline简介 Item管道的主要责任是负责处理有蜘蛛从网页中抽取的Item,他的主要任务是清晰.验证和存储数据. 当页面被蜘蛛解析后,将被发送到Item管道,并经过几个特定的次序处理数据. 每个Item管道的组件都是有一个简单的方法组成的Python类. 他们获取了Item并执行他们的方法,同时他们还需要确定的是是否需要在Item管道中继续执行下一步或是直接丢弃掉不处理. Item管道通常执行的过程有 清理HTML数据 验证解析到的数据(检查Item是否包含必要的字段) 检查是
-
Python利用Scrapy框架爬取豆瓣电影示例
本文实例讲述了Python利用Scrapy框架爬取豆瓣电影.分享给大家供大家参考,具体如下: 1.概念 Scrapy是一个为了爬取网站数据,提取结构性数据而编写的应用框架. 可以应用在包括数据挖掘,信息处理或存储历史数据等一系列的程序中. 通过Python包管理工具可以很便捷地对scrapy进行安装,如果在安装中报错提示缺少依赖的包,那就通过pip安装所缺的包 pip install scrapy scrapy的组成结构如下图所示 引擎Scrapy Engine,用于中转调度其他部分的信号和数据