详解JAVA中priorityqueue的具体使用
Java中PriorityQueue通过二叉小顶堆实现,可以用一棵完全二叉树表示。本文从Queue接口函数出发,结合生动的图解,深入浅出地分析PriorityQueue每个操作的具体过程和时间复杂度,将让读者建立对PriorityQueue建立清晰而深入的认识。
总体介绍
前面以JavaArrayDeque为例讲解了Stack和Queue,其实还有一种特殊的队列叫做PriorityQueue,即优先队列。优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java的优先队列每次取最小元素,C++的优先队列每次取最大元素)。这里牵涉到了大小关系,元素大小的评判可以通过元素本身的自然顺序(natural ordering),也可以通过构造时传入的比较器(Comparator,类似于C++的仿函数)。
Java中PriorityQueue实现了Queue接口,不允许放入null元素;其通过堆实现,具体说是通过完全二叉树(complete binary tree)实现的小顶堆(任意一个非叶子节点的权值,都不大于其左右子节点的权值),也就意味着可以通过数组来作为PriorityQueue的底层实现。

上图中我们给每个元素按照层序遍历的方式进行了编号,如果你足够细心,会发现父节点和子节点的编号是有联系的,更确切的说父子节点的编号之间有如下关系:
leftNo = parentNo*2+1
rightNo = parentNo*2+2
parentNo = (nodeNo-1)/2
通过上述三个公式,可以轻易计算出某个节点的父节点以及子节点的下标。这也就是为什么可以直接用数组来存储堆的原因。
PriorityQueue的peek()和element操作是常数时间,add(),offer(), 无参数的remove()以及poll()方法的时间复杂度都是log(N)。
方法剖析
add()和offer()
add(E e)和offer(E e)的语义相同,都是向优先队列中插入元素,只是Queue接口规定二者对插入失败时的处理不同,前者在插入失败时抛出异常,后则则会返回false。对于PriorityQueue这两个方法其实没什么差别。

新加入的元素可能会破坏小顶堆的性质,因此需要进行必要的调整。
//offer(E e)
public boolean offer(E e) {
if (e == null)//不允许放入null元素
throw new NullPointerException();
modCount++;
int i = size;
if (i >= queue.length)
grow(i + 1);//自动扩容
size = i + 1;
if (i == 0)//队列原来为空,这是插入的第一个元素
queue[0] = e;
else
siftUp(i, e);//调整
return true;
}
上述代码中,扩容函数grow()类似于ArrayList里的grow()函数,就是再申请一个更大的数组,并将原数组的元素复制过去,这里不再赘述。需要注意的是siftUp(int k, E x)方法,该方法用于插入元素x并维持堆的特性。
//siftUp()
private void siftUp(int k, E x) {
while (k > 0) {
int parent = (k - 1) >>> 1;//parentNo = (nodeNo-1)/2
Object e = queue[parent];
if (comparator.compare(x, (E) e) >= 0)//调用比较器的比较方法
break;
queue[k] = e;
k = parent;
}
queue[k] = x;
}
新加入的元素x可能会破坏小顶堆的性质,因此需要进行调整。调整的过程为:从k指定的位置开始,将x逐层与当前点的parent进行比较并交换,直到满足x >= queue[parent]为止。注意这里的比较可以是元素的自然顺序,也可以是依靠比较器的顺序。
element()和peek()
element()和peek()的语义完全相同,都是获取但不删除队首元素,也就是队列中权值最小的那个元素,二者唯一的区别是当方法失败时前者抛出异常,后者返回null。根据小顶堆的性质,堆顶那个元素就是全局最小的那个;由于堆用数组表示,根据下标关系,0下标处的那个元素既是堆顶元素。所以直接返回数组0下标处的那个元素即可。

代码也就非常简洁:
//peek()
public E peek() {
if (size == 0)
return null;
return (E) queue[0];//0下标处的那个元素就是最小的那个
}
remove()和poll()
remove()和poll()方法的语义也完全相同,都是获取并删除队首元素,区别是当方法失败时前者抛出异常,后者返回null。由于删除操作会改变队列的结构,为维护小顶堆的性质,需要进行必要的调整。
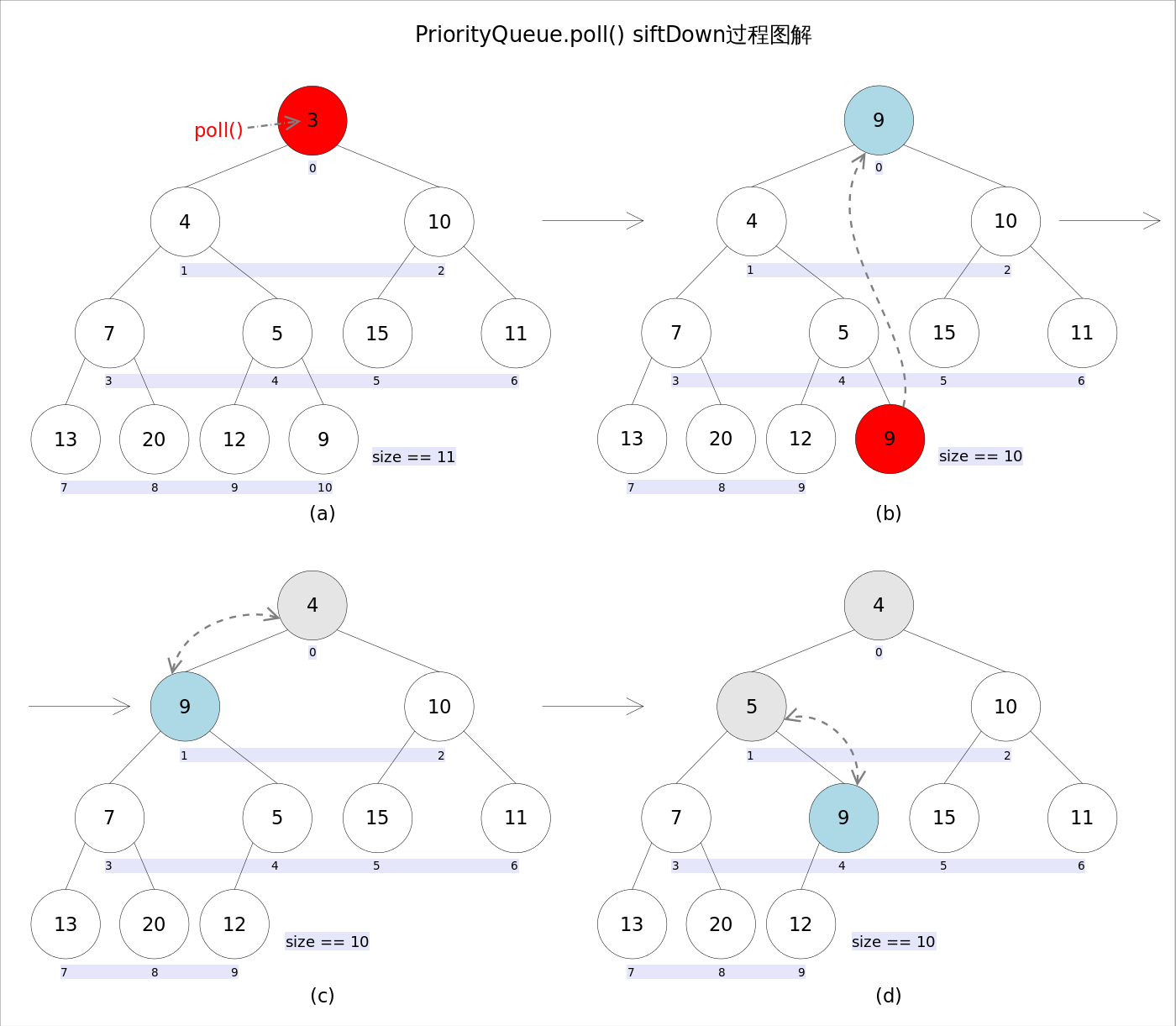
代码如下:
public E poll() {
if (size == 0)
return null;
int s = --size;
modCount++;
E result = (E) queue[0];//0下标处的那个元素就是最小的那个
E x = (E) queue[s];
queue[s] = null;
if (s != 0)
siftDown(0, x);//调整
return result;
}
上述代码首先记录0下标处的元素,并用最后一个元素替换0下标位置的元素,之后调用siftDown()方法对堆进行调整,最后返回原来0下标处的那个元素(也就是最小的那个元素)。重点是siftDown(int k, E x)方法,该方法的作用是从k指定的位置开始,将x逐层向下与当前点的左右孩子中较小的那个交换,直到x小于或等于左右孩子中的任何一个为止。
//siftDown()
private void siftDown(int k, E x) {
int half = size >>> 1;
while (k < half) {
//首先找到左右孩子中较小的那个,记录到c里,并用child记录其下标
int child = (k << 1) + 1;//leftNo = parentNo*2+1
Object c = queue[child];
int right = child + 1;
if (right < size &&
comparator.compare((E) c, (E) queue[right]) > 0)
c = queue[child = right];
if (comparator.compare(x, (E) c) <= 0)
break;
queue[k] = c;//然后用c取代原来的值
k = child;
}
queue[k] = x;
}
remove(Object o)
remove(Object o)方法用于删除队列中跟o相等的某一个元素(如果有多个相等,只删除一个),该方法不是Queue接口内的方法,而是Collection接口的方法。由于删除操作会改变队列结构,所以要进行调整;又由于删除元素的位置可能是任意的,所以调整过程比其它函数稍加繁琐。具体来说,remove(Object o)可以分为2种情况:1. 删除的是最后一个元素。直接删除即可,不需要调整。2. 删除的不是最后一个元素,从删除点开始以最后一个元素为参照调用一次siftDown()即可。此处不再赘述。

具体代码如下:
//remove(Object o)
public boolean remove(Object o) {
//通过遍历数组的方式找到第一个满足o.equals(queue[i])元素的下标
int i = indexOf(o);
if (i == -1)
return false;
int s = --size;
if (s == i) //情况1
queue[i] = null;
else {
E moved = (E) queue[s];
queue[s] = null;
siftDown(i, moved);//情况2
......
}
return true;
}
到此这篇关于详解JAVA中priorityqueue的具体使用的文章就介绍到这了,更多相关JAVA priorityqueue内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
java优先队列PriorityQueue中Comparator的用法详解
在使用java的优先队列PriorityQueue的时候,会看到这样的用法. PriorityQueue<Integer> queue = new PriorityQueue<Integer>(new Comparator<Integer>(){ @Override public int compare(Integer o1, Integer o2){ return o1.compareTo(o2); } }); 那这样到底构造的是最大优先还是最小优先队列呢? 看看源码
-
Java PriorityQueue数据结构接口原理及用法
PriorityQueue是从JDK1.5开始提供的新的数据结构接口,它是一种基于优先级堆的极大优先级队列.优先级队列是不同于先进先出队列的另一种队列.每次从队列中取出的是具有最高优先权的元素.如果不提供Comparator的话,优先队列中元素默认按自然顺序排列,也就是数字默认是小的在队列头,字符串则按字典序排列(参阅 Comparable),也可以根据 Comparator 来指定,这取决于使用哪种构造方法.优先级队列不允许 null 元素.依靠自然排序的优先级队列还不允许插入不可比较的对象(
-
Java的优先队列PriorityQueue原理及实例分析
这篇文章主要介绍了Java的优先队列PriorityQueue原理解析,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 一.优先队列概述 优先队列PriorityQueue是Queue接口的实现,可以对其中元素进行排序, 可以放基本数据类型的包装类(如:Integer,Long等)或自定义的类 对于基本数据类型的包装器类,优先队列中元素默认排列顺序是升序排列 但对于自己定义的类来说,需要自己定义比较器 二.常用方法 peek()//返回队首元素
-

解析Java中PriorityQueue优先级队列结构的源码及用法
一.PriorityQueue的数据结构 JDK7中PriorityQueue(优先级队列)的数据结构是二叉堆.准确的说是一个最小堆. 二叉堆是一个特殊的堆, 它近似完全二叉树.二叉堆满足特性:父节点的键值总是保持固定的序关系于任何一个子节点的键值,且每个节点的左子树和右子树都是一个二叉堆. 当父节点的键值总是大于或等于任何一个子节点的键值时为最大堆. 当父节点的键值总是小于或等于任何一个子节点的键值时为最小堆. 下图是一个最大堆 priorityQueue队头就是给定顺序的最小元素. prio
-
Java优先队列(PriorityQueue)重写compare操作
we can custom min heap or max heap by override the method compare. package myapp.kit.quickstart.utils; import java.util.Comparator; import java.util.Queue; /** * priority queue (heap) demo. * * @author huangdingsheng * @version 1.0, 2020/5/8 */ publi
-
详解JAVA中priorityqueue的具体使用
Java中PriorityQueue通过二叉小顶堆实现,可以用一棵完全二叉树表示.本文从Queue接口函数出发,结合生动的图解,深入浅出地分析PriorityQueue每个操作的具体过程和时间复杂度,将让读者建立对PriorityQueue建立清晰而深入的认识. 总体介绍 前面以JavaArrayDeque为例讲解了Stack和Queue,其实还有一种特殊的队列叫做PriorityQueue,即优先队列.优先队列的作用是能保证每次取出的元素都是队列中权值最小的(Java的优先队列每次取最小元素,
-
详解java中DelayQueue的使用
简介 今天给大家介绍一下DelayQueue,DelayQueue是BlockingQueue的一种,所以它是线程安全的,DelayQueue的特点就是插入Queue中的数据可以按照自定义的delay时间进行排序.只有delay时间小于0的元素才能够被取出. DelayQueue 先看一下DelayQueue的定义: public class DelayQueue<E extends Delayed> extends AbstractQueue<E> implements Bloc
-
详解Java中的延时队列 DelayQueue
当用户超时未支付时,给用户发提醒消息.另一种场景是,超时未付款,订单自动取消.通常,订单创建的时候可以向延迟队列种插入一条消息,到时间自动执行.其实,也可以用临时表,把这些未支付的订单放到一个临时表中,或者Redis,然后定时任务去扫描.这里我们用延时队列来做.RocketMQ有延时队列,RibbitMQ也可以实现,Java自带的也有延时队列,接下来就回顾一下各种队列. Queue 队列是一种集合.除了基本的集合操作以外,队列还提供了额外的插入.提取和检查操作.队列的每个方法都以两种形式存在:一
-
详解Java中Dijkstra(迪杰斯特拉)算法的图解与实现
目录 简介 工作过程 总体思路 实现 小根堆 Dijsktra 测试 简介 Dijkstra(迪杰斯特拉)算法是典型的单源最短路径算法,用于计算一个节点到其他所有节点的最短路径.主要特点是以起始点为中心向外层层扩展,直到扩展到终点为止.Dijkstra算法是很有代表性的最短路径算法,在很多专业课程中都作为基本内容有详细的介绍,如数据结构,图论,运筹学等等.注意该算法要求图中不存在负权边.对应问题:在无向图G=(V,E)中,假设每条边E(i)的长度W(i),求由顶点V0到各节点的最短路径. 工作过
-
详解Java中@Override的作用
详解Java中@Override的作用 @Override是伪代码,表示重写(当然不写也可以),不过写上有如下好处: 1.可以当注释用,方便阅读: 2.编译器可以给你验证@Override下面的方法名是否是你父类中所有的,如果没有则报错.例如,你如果没写@Override,而你下面的方法名又写错了,这时你的编译器是可以编译通过的,因为编译器以为这个方法是你的子类中自己增加的方法. 举例:在重写父类的onCreate时,在方法前面加上@Override 系统可以帮你检查方法的正确性. @Overr
-
详解Java中多线程异常捕获Runnable的实现
详解Java中多线程异常捕获Runnable的实现 1.背景: Java 多线程异常不向主线程抛,自己处理,外部捕获不了异常.所以要实现主线程对子线程异常的捕获. 2.工具: 实现Runnable接口的LayerInitTask类,ThreadException类,线程安全的Vector 3.思路: 向LayerInitTask中传入Vector,记录异常情况,外部遍历,判断,抛出异常. 4.代码: package step5.exception; import java.util.Vector
-
详解java 中Spring jsonp 跨域请求的实例
详解java 中Spring jsonp 跨域请求的实例 jsonp介绍 JSONP(JSON with Padding)是JSON的一种"使用模式",可用于解决主流浏览器的跨域数据访问的问题.由于同源策略,一般来说位于 server1.example.com 的网页无法与不是 server1.example.com的服务器沟通,而 HTML 的<script> 元素是一个例外.利用 <script> 元素的这个开放策略,网页可以得到从其他来源动态产生的 JSO
-
详解Java 中的嵌套类与内部类
详解Java 中的嵌套类与内部类 在Java中,可以在一个类内部定义另一个类,这种类称为嵌套类(nested class).嵌套类有两种类型:静态嵌套类和非静态嵌套类.静态嵌套类较少使用,非静态嵌套类使用较多,也就是常说的内部类.其中内部类又分为三种类型: 1.在外部类中直接定义的内部类. 2.在函数中定义的内部类. 3.匿名内部类. 对于这几种类型的访问规则, 示例程序如下: package lxg; //定义外部类 public class OuterClass { //外部类静态成员变量
-
详解Java中Collections.sort排序
Comparator是个接口,可重写compare()及equals()这两个方法,用于比价功能:如果是null的话,就是使用元素的默认顺序,如a,b,c,d,e,f,g,就是a,b,c,d,e,f,g这样,当然数字也是这样的. compare(a,b)方法:根据第一个参数小于.等于或大于第二个参数分别返回负整数.零或正整数. equals(obj)方法:仅当指定的对象也是一个 Comparator,并且强行实施与此 Comparator 相同的排序时才返回 true. Collections.
-
详解Java中HashSet和TreeSet的区别
详解Java中HashSet和TreeSet的区别 1. HashSet HashSet有以下特点: 不能保证元素的排列顺序,顺序有可能发生变化 不是同步的 集合元素可以是null,但只能放入一个null 当向HashSet集合中存入一个元素时,HashSet会调用该对象的hashCode()方法来得到该对象的hashCode值,然后根据 hashCode值来决定该对象在HashSet中存储位置. 简单的说,HashSet集合判断两个元素相等的标准是两个对象通过equals方法比较相等,并且两个