教你如何让spark sql写mysql的时候支持update操作
目录
- 1、首先了解背景
- 2、如何让sparkSQL支持update
- 3、改造源码前,需要了解整体的代码设计和执行流程
- 4、改造源码

如何让sparkSQL在对接mysql的时候,除了支持:Append、Overwrite、ErrorIfExists、Ignore;还要在支持update操作
1、首先了解背景
spark提供了一个枚举类,用来支撑对接数据源的操作模式
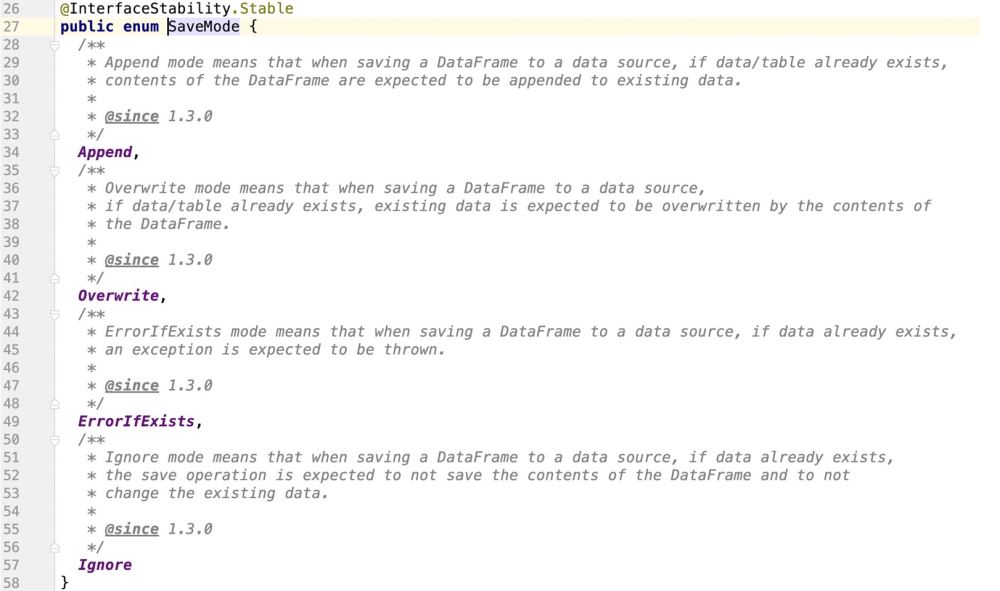
通过源码查看,很明显,spark是不支持update操作的
2、如何让sparkSQL支持update
关键的知识点就是:
我们正常在sparkSQL写数据到mysql的时候:
大概的api是:
dataframe.write
.format("sql.execution.customDatasource.jdbc")
.option("jdbc.driver", "com.mysql.jdbc.Driver")
.option("jdbc.url", "jdbc:mysql://localhost:3306/test?user=root&password=&useUnicode=true&characterEncoding=gbk&autoReconnect=true&failOverReadOnly=false")
.option("jdbc.db", "test")
.save()
那么在底层中,spark会通过JDBC方言JdbcDialect , 将我们要插入的数据翻译成:
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
那么通过方言解析出的sql语句就通过PrepareStatement的executeBatch(),将sql语句提交给mysql,然后数据插入;
那么上面的sql语句很明显,完全就是插入代码,并没有我们期望的 update操作,类似:
UPDATE table_name SET field1=new-value1, field2=new-value2
但是mysql独家支持这样的sql语句:
INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
大概的意思就是,如果数据不存在则插入,如果数据存在,则 执行update操作;
因此,我们的切入点就是,让sparkSQL内部对接JdbcDialect的时候,能够生成这种sql:
INSERT INTO 表名称 (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
3、改造源码前,需要了解整体的代码设计和执行流程
首先是:
dataframe.write
调用write方法就是为了返回一个类:DataFrameWriter
主要是因为DataFrameWriter是sparksql对接外部数据源写入的入口携带类,下面这些内容是给DataFrameWriter注册的携带信息

然后在出发save()操作后,就开始将数据写入;
接下来看save()源码:

在上面的源码里面主要是注册DataSource实例,然后使用DataSource的write方法进行数据写入
实例化DataSource的时候:
def save(): Unit = {
assertNotBucketed("save")
val dataSource = DataSource(
df.sparkSession,
className = source,//自定义数据源的包路径
partitionColumns = partitioningColumns.getOrElse(Nil),//分区字段
bucketSpec = getBucketSpec,//分桶(用于hive)
options = extraOptions.toMap)//传入的注册信息
//mode:插入数据方式SaveMode , df:要插入的数据
dataSource.write(mode, df)
}
然后就是dataSource.write(mode, df)的细节,整段的逻辑就是:
根据providingClass.newInstance()去做模式匹配,然后匹配到哪里,就执行哪里的代码;

然后看下providingClass是什么:


拿到包路径.DefaultSource之后,程序进入:

那么如果是数据库作为写入目标的话,就会走:dataSource.createRelation,直接跟进源码:

很明显是个特质,因此哪里实现了特质,程序就会走到哪里了;
实现这个特质的地方就是:包路径.DefaultSource , 然后就在这里面去实现数据的插入和update的支持操作;
4、改造源码
根据代码的流程,最终sparkSQL 将数据写入mysql的操作,会进入:包路径.DefaultSource这个类里面;
也就是说,在这个类里面既要支持spark的正常插入操作(SaveMode),还要在支持update;
如果让sparksql支持update操作,最关键的就是做一个判断,比如:
if(isUpdate){
sql语句:INSERT INTO student (columns_1,columns_2)VALUES ('第一个字段值','第二个字段值') ON DUPLICATE KEY UPDATE columns_1 = '呵呵哒',columns_2 = '哈哈哒';
}else{
insert into student (columns_1 , columns_2 , ...) values (? , ? , ....)
}
但是,在spark生产sql语句的源码中,是这样写的:

没有任何的判断逻辑,就是最后生成一个:
INSERT INTO TABLE (字段1 , 字段2....) VALUES (? , ? ...)
所以首要的任务就是 ,怎么能让当前代码支持:ON DUPLICATE KEY UPDATE
可以做个大胆的设计,就是在insertStatement这个方法中做个如下的判断
def insertStatement(conn: Connection, savemode:CustomSaveMode , table: String, rddSchema: StructType, dialect: JdbcDialect)
: PreparedStatement = {
val columns = rddSchema.fields.map(x => dialect.quoteIdentifier(x.name)).mkString(",")
val placeholders = rddSchema.fields.map(_ => "?").mkString(",")
if(savemode == CustomSaveMode.update){
//TODO 如果是update,就组装成ON DUPLICATE KEY UPDATE的模式处理
s"INSERT INTO $table ($columns) VALUES ($placeholders) ON DUPLICATE KEY UPDATE $duplicateSetting"
}esle{
val sql = s"INSERT INTO $table ($columns) VALUES ($placeholders)"
conn.prepareStatement(sql)
}
}
这样,在用户传递进来的savemode模式,我们进行校验,如果是update操作,就返回对应的sql语句!
所以按照上面的逻辑,我们代码这样写:

这样我们就拿到了对应的sql语句;
但是只有这个sql语句还是不行的,因为在spark中会执行jdbc的prepareStatement操作,这里面会涉及到游标。
即jdbc在遍历这个sql的时候,源码会这样做:
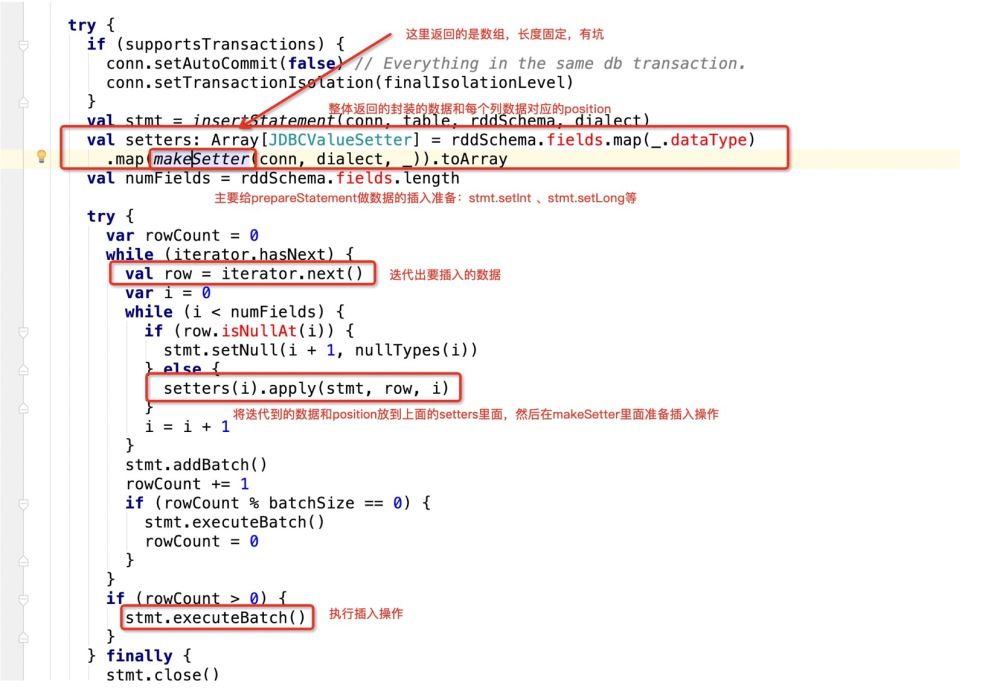
看下makeSetter:

所谓有坑就是:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?)
那么当前在源码中返回的数组长度应该是3:
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
但是如果我们此时支持了update操作,既:
insert into table (字段1 , 字段2, 字段3) values (? , ? , ?) ON DUPLICATE KEY UPDATE 字段1 = ?,字段2 = ?,字段3=?;
那么很明显,上面的sql语句提供了6个? , 但在规定字段长度的时候只有3
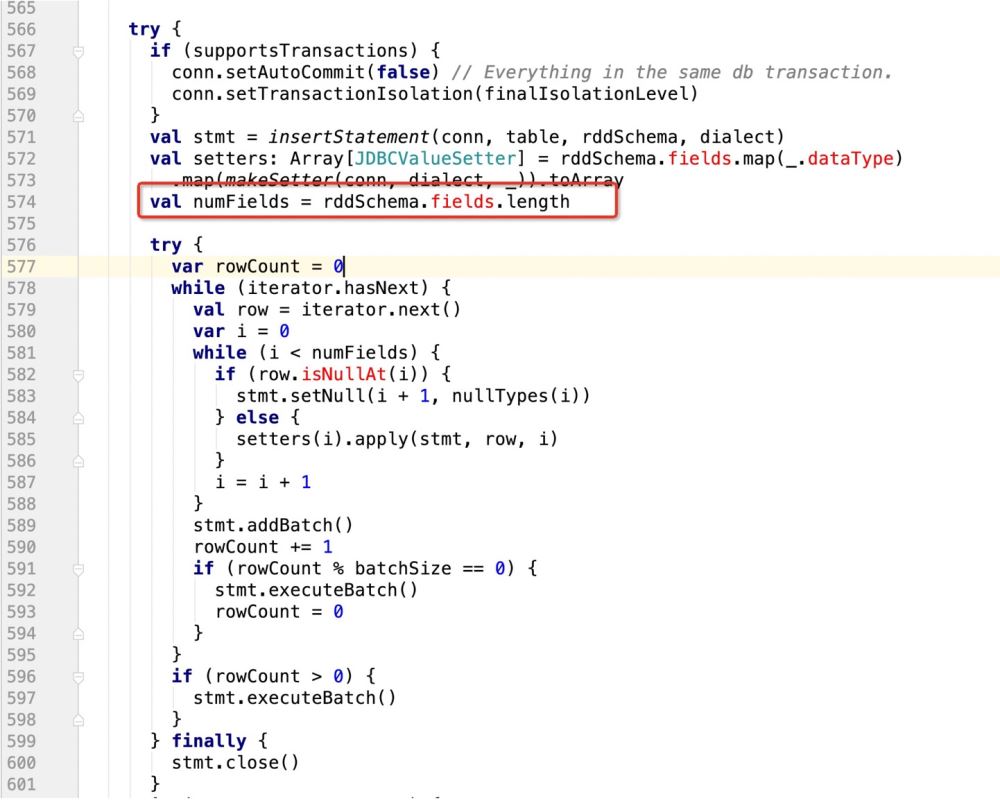
这样的话,后面的update操作就无法执行,程序报错!
所以我们需要有一个 识别机制,既:
if(isupdate){
val numFields = rddSchema.fields.length * 2
}else{
val numFields = rddSchema.fields.length
}

row[1,2,3] setter(0,1) //index of setter , index of row setter(1,2) setter(2,3) setter(3,1) setter(4,2) setter(5,3)
所以在prepareStatment中的占位符应该是row的两倍,而且应该是类似这样的一个逻辑
因此,代码改造前样子:


改造后的样子:
try {
if (supportsTransactions) {
conn.setAutoCommit(false) // Everything in the same db transaction.
conn.setTransactionIsolation(finalIsolationLevel)
}
// val stmt = insertStatement(conn, table, rddSchema, dialect)
//此处采用最新自己的sql语句,封装成prepareStatement
val stmt = conn.prepareStatement(sqlStmt)
println(sqlStmt)
/**
* 在mysql中有这样的操作:
* INSERT INTO user_admin_t (_id,password) VALUES ('1','第一次插入的密码')
* INSERT INTO user_admin_t (_id,password)VALUES ('1','第一次插入的密码') ON DUPLICATE KEY UPDATE _id = 'UpId',password = 'upPassword';
* 如果是下面的ON DUPLICATE KEY操作,那么在prepareStatement中的游标会扩增一倍
* 并且如果没有update操作,那么他的游标是从0开始计数的
* 如果是update操作,要算上之前的insert操作
* */
//makeSetter也要适配update操作,即游标问题
val isUpdate = saveMode == CustomSaveMode.Update
val setters: Array[JDBCValueSetter] = isUpdate match {
case true =>
val setters: Array[JDBCValueSetter] = rddSchema.fields.map(_.dataType)
.map(makeSetter(conn, dialect, _)).toArray
Array.fill(2)(setters).flatten
case _ =>
rddSchema.fields.map(_.dataType)
val numFieldsLength = rddSchema.fields.length
val numFields = isUpdate match{
case true => numFieldsLength *2
case _ => numFieldsLength
val cursorBegin = numFields / 2
try {
var rowCount = 0
while (iterator.hasNext) {
val row = iterator.next()
var i = 0
while (i < numFields) {
if(isUpdate){
//需要判断当前游标是否走到了ON DUPLICATE KEY UPDATE
i < cursorBegin match{
//说明还没走到update阶段
case true =>
//row.isNullAt 判空,则设置空值
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i, 0)
}
//说明走到了update阶段
case false =>
if (row.isNullAt(i - cursorBegin)) {
//pos - offset
stmt.setNull(i + 1, nullTypes(i - cursorBegin))
setters(i).apply(stmt, row, i, cursorBegin)
}
}else{
if (row.isNullAt(i)) {
stmt.setNull(i + 1, nullTypes(i))
} else {
setters(i).apply(stmt, row, i ,0)
}
//滚动游标
i = i + 1
}
stmt.addBatch()
rowCount += 1
if (rowCount % batchSize == 0) {
stmt.executeBatch()
rowCount = 0
}
if (rowCount > 0) {
stmt.executeBatch()
} finally {
stmt.close()
conn.commit()
committed = true
Iterator.empty
} catch {
case e: SQLException =>
val cause = e.getNextException
if (cause != null && e.getCause != cause) {
if (e.getCause == null) {
e.initCause(cause)
} else {
e.addSuppressed(cause)
throw e
} finally {
if (!committed) {
// The stage must fail. We got here through an exception path, so
// let the exception through unless rollback() or close() want to
// tell the user about another problem.
if (supportsTransactions) {
conn.rollback()
conn.close()
} else {
// The stage must succeed. We cannot propagate any exception close() might throw.
try {
conn.close()
} catch {
case e: Exception => logWarning("Transaction succeeded, but closing failed", e)
// A `JDBCValueSetter` is responsible for setting a value from `Row` into a field for
// `PreparedStatement`. The last argument `Int` means the index for the value to be set
// in the SQL statement and also used for the value in `Row`.
//PreparedStatement, Row, position , cursor
private type JDBCValueSetter = (PreparedStatement, Row, Int , Int) => Unit
private def makeSetter(
conn: Connection,
dialect: JdbcDialect,
dataType: DataType): JDBCValueSetter = dataType match {
case IntegerType =>
(stmt: PreparedStatement, row: Row, pos: Int,cursor:Int) =>
stmt.setInt(pos + 1, row.getInt(pos - cursor))
case LongType =>
stmt.setLong(pos + 1, row.getLong(pos - cursor))
case DoubleType =>
stmt.setDouble(pos + 1, row.getDouble(pos - cursor))
case FloatType =>
stmt.setFloat(pos + 1, row.getFloat(pos - cursor))
case ShortType =>
stmt.setInt(pos + 1, row.getShort(pos - cursor))
case ByteType =>
stmt.setInt(pos + 1, row.getByte(pos - cursor))
case BooleanType =>
stmt.setBoolean(pos + 1, row.getBoolean(pos - cursor))
case StringType =>
// println(row.getString(pos))
stmt.setString(pos + 1, row.getString(pos - cursor))
case BinaryType =>
stmt.setBytes(pos + 1, row.getAs[Array[Byte]](pos - cursor))
case TimestampType =>
stmt.setTimestamp(pos + 1, row.getAs[java.sql.Timestamp](pos - cursor))
case DateType =>
stmt.setDate(pos + 1, row.getAs[java.sql.Date](pos - cursor))
case t: DecimalType =>
stmt.setBigDecimal(pos + 1, row.getDecimal(pos - cursor))
case ArrayType(et, _) =>
// remove type length parameters from end of type name
val typeName = getJdbcType(et, dialect).databaseTypeDefinition
.toLowerCase.split("\\(")(0)
val array = conn.createArrayOf(
typeName,
row.getSeq[AnyRef](pos - cursor).toArray)
stmt.setArray(pos + 1, array)
case _ =>
(_: PreparedStatement, _: Row, pos: Int,cursor:Int) =>
throw new IllegalArgumentException(
s"Can't translate non-null value for field $pos")
}
完整代码:
https://github.com/niutaofan/bazinga
到此这篇关于教你如何让spark sql写mysql的时候支持update操作的文章就介绍到这了,更多相关spark sql写mysql支持update内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

pyspark对Mysql数据库进行读写的实现
pyspark是Spark对Python的api接口,可以在Python环境中通过调用pyspark模块来操作spark,完成大数据框架下的数据分析与挖掘.其中,数据的读写是基础操作,pyspark的子模块pyspark.sql 可以完成大部分类型的数据读写.文本介绍在pyspark中读写Mysql数据库. 1 软件版本 在Python中使用Spark,需要安装配置Spark,这里跳过配置的过程,给出运行环境和相关程序版本信息. win10 64bit java 13.0.1 spark 3.0
-
spark rdd转dataframe 写入mysql的实例讲解
dataframe是在spark1.3.0中推出的新的api,这让spark具备了处理大规模结构化数据的能力,在比原有的RDD转化方式易用的前提下,据说计算性能更还快了两倍.spark在离线批处理或者实时计算中都可以将rdd转成dataframe进而通过简单的sql命令对数据进行操作,对于熟悉sql的人来说在转换和过滤过程很方便,甚至可以有更高层次的应用,比如在实时这一块,传入kafka的topic名称和sql语句,后台读取自己配置好的内容字段反射成一个class并利用出入的sql对实时数据进行
-
教你如何让spark sql写mysql的时候支持update操作
目录 1.首先了解背景 2.如何让sparkSQL支持update 3.改造源码前,需要了解整体的代码设计和执行流程 4.改造源码 如何让sparkSQL在对接mysql的时候,除了支持:Append.Overwrite.ErrorIfExists.Ignore:还要在支持update操作 1.首先了解背景 spark提供了一个枚举类,用来支撑对接数据源的操作模式 通过源码查看,很明显,spark是不支持update操作的 2.如何让sparkSQL支持update 关键的知识点就是: 我们正常
-
Spark SQL常见4种数据源详解
通用load/write方法 手动指定选项 Spark SQL的DataFrame接口支持多种数据源的操作.一个DataFrame可以进行RDDs方式的操作,也可以被注册为临时表.把DataFrame注册为临时表之后,就可以对该DataFrame执行SQL查询. Spark SQL的默认数据源为Parquet格式.数据源为Parquet文件时,Spark SQL可以方便的执行所有的操作. 修改配置项spark.sql.sources.default,可修改默认数据源格式. scala> val
-
Spark学习笔记之Spark SQL的具体使用
1. Spark SQL是什么? 处理结构化数据的一个spark的模块 它提供了一个编程抽象叫做DataFrame并且作为分布式SQL查询引擎的作用 2. Spark SQL的特点 多语言的接口支持(java python scala) 统一的数据访问 完全兼容hive 支持标准的连接 3. 为什么学习SparkSQL? 我们已经学习了Hive,它是将Hive SQL转换成MapReduce然后提交到集群上执行,大大简化了编写MapReduce的程序的复杂性,由于MapReduce这种计算模型执
-
Spark SQL的整体实现逻辑解析
1.sql语句的模块解析 当我们写一个查询语句时,一般包含三个部分,select部分,from数据源部分,where限制条件部分,这三部分的内容在sql中有专门的名称: 当我们写sql时,如上图所示,在进行逻辑解析时会把sql分成三个部分,project,DataSource,Filter模块,当生成执行部分时又把他们称为:Result模块. DataSource模块和Opertion模块. 那么在关系数据库中,当我们写完一个查询语句进行执行时,发生的过程如下图所示: 整个执行流程是:query
-
Spark SQL配置及使用教程
目录 SparkSQL版本: SparkSQL DSL语法 SparkSQL和Hive的集成 Spark应用依赖第三方jar包文件解决方案 SparkSQL的ThriftServer服务 SparkSQL的ThriftServer服务测试 Spark中beeline的使用 通过jdbc来访问spark的ThriftServer接口 SparkSQL案例 案例一:SparkSQL读取HDFS上Json格式的文件 案例二:DataFrame和Dataset和RDD之间的互相转换
-
Spark SQL配置及使用教程
目录 SparkSQL版本: SparkSQL DSL语法 SparkSQL和Hive的集成 Spark应用依赖第三方jar包文件解决方案 SparkSQL的ThriftServer服务 SparkSQL的ThriftServer服务测试 Spark中beeline的使用 通过jdbc来访问spark的ThriftServer接口 SparkSQL案例 案例一:SparkSQL读取HDFS上Json格式的文件 案例二:DataFrame和Dataset和RDD之间的互相转换
-
Spark SQL数据加载和保存实例讲解
一.前置知识详解 Spark SQL重要是操作DataFrame,DataFrame本身提供了save和load的操作, Load:可以创建DataFrame, Save:把DataFrame中的数据保存到文件或者说与具体的格式来指明我们要读取的文件的类型以及与具体的格式来指出我们要输出的文件是什么类型. 二.Spark SQL读写数据代码实战 import org.apache.spark.SparkConf; import org.apache.spark.api.java.JavaRDD;
-
关于sql和mysql对于别名不能调用的一些理解
在写sql的时候,由于有部分语句别名不能调用,百度了一下原因,原来是由于别名机制不同引起的.为了避免下一次再犯同样的错误,今天把网上找到资料总结了一下,sql和mysql执行顺序,发现内部机制是一样的.最大区别是在别名的引用上. 一.sql执行顺序 (1)from (3) join (2) on (4) where (5)group by (6) avg,sum.... (7)having (8) select (9) distinct (10) order by 从这个顺序中我们不难发现,所有
-
Spark SQL操作JSON字段的小技巧
前言 介绍Spark SQL的JSON支持,这是我们在Databricks中开发的一个功能,可以在Spark中更容易查询和创建JSON数据.随着网络和移动应用程序的普及,JSON已经成为Web服务API以及长期存储的常用的交换格式.使用现有的工具,用户通常会使用复杂的管道来在分析系统中读取和写入JSON数据集.在Apache Spark 1.1中发布Spark SQL的JSON支持,在Apache Spark 1.2中增强,极大地简化了使用JSON数据的端到端体验. 很多时候,比如用struct
-
workerman写mysql连接池的实例代码
首先要了解为什么用连接池,连接池能为你解决什么问题 连接池主要的作用: 1.减少与数据服务器建立TCP连接三次握手及连接关闭四次挥手的开销,从而降低客户端和mysql服务端的负载,缩短请求响应时间 2.减少数据库的并发连接数,即解决应用服务器过多导致的数据库 too many connections 问题 如果是为了解决问题1 则在workerman中数据库连接池不是最高效的方法,反而是自找麻烦的做法.由于PHP是单进程单线程的,使用PHP实现数据库连接池,肯定需要用单独的进程去做,那么就会涉及