Python实现七个基本算法的实例代码
1.顺序查找
当数据存储在诸如列表的集合中时,我们说这些数据具有线性或顺序关系。 每个数据元素都存储在相对于其他数据元素的位置。 由于这些索引值是有序的,我们可以按顺序访问它们。 这个过程产实现的搜索即为顺序查找。
顺序查找原理剖析:从列表中的第一个元素开始,我们按照基本的顺序排序,简单地从一个元素移动到另一个元素,直到找到我们正在寻找的元素或遍历完整个列表。如果我们遍历完整个列表,则说明正在搜索的元素不存在。
代码实现:该函数需要一个列表和我们正在寻找的元素作为参数,并返回一个是否存在的布尔值。found 布尔变量初始化为 False,如果我们发现列表中的元素,则赋值为 True。
def search(alist,item): find = False cur = 0 while cur < len(alist): if alist[cur] == item: find = True break else: cur += 1 return find
2.二分查找
有序列表对于我们的实现搜索是很有用的。在顺序查找中,当我们与第一个元素进行比较时,如果第一个元素不是我们要查找的,则最多还有 n-1 个元素需要进行比较。
二分查找则是从中间元素开始,而不是按顺序查找列表。 如果该元素是我们正在寻找的元素,我们就完成了查找。 如果它不是,我们可以使用列表的有序性质来消除剩余元素的一半。
如果我们正在查找的元素大于中间元素,就可以消除中间元素以及比中间元素小的一半元素。如果该元素在列表中,肯定在大的那半部分。然后我们可以用大的半部分重复该过程,继续从中间元素开始,将其与我们正在寻找的内容进行比较。
def search(alist,item): left = 0 right = len(alist) - 1 find = False while left <= right: mid_index = (left + right)//2 if item == alist[mid_index]: find = True break else: if item > alist[mid_index]: left = mid_index + 1 else: right = mid_index -1 return find
3.冒泡排序
原理:
比较相邻的元素。如果第一个比第二个大,就交换他们两个。对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对。在这一点,最后的元素应该会是最大的数。针对所有的元素重复以上的步骤,除了最后一个。持续每次对越来越少的元素重复上面的步骤,直到没有任何一对数字需要比较。
def sort(alist): length = len(alist) for i in range(0,length-1): for j in range(0,length-1-i): if alist[i] > alist[i+1]: alist[i],alist[i+1] = alist[i+1],alist[i]
4.选择排序
工作原理:第一次从待排序的数据元素中选出最小(或最大)的一个元素,存放在序列的起始位置,然后再从剩余的未排序元素中寻找到最小(大)元素,然后放到已排序的序列的末尾。以此类推,直到全部待排序的数据元素的个数为零。选择排序是不稳定的排序方法。
def sort(alist): length = len(alist) for j in range(length-1,0,-1): max_index = 0 for i in range(1,j+1): if alist[max_index] < alist[i]: max_index = i alist[max_index],alist[j] = alist[j],alist[max_index]
5.插入排序
原理:
基本思想是,每步将一个待排序的记录,按其关键码值的大小插入前面已经排序的文件中适当位置上,直到全部插入完为止。关键码是数据元素中某个数据项的值,用它可以标示一个数据元素。
def sort(alist): length = len(alist) for j in range(1,length): i = j while i > 0: if alist[i] < alist[i-1]: alist[i],alist[i-1] = alist[i-1],alist[i] i -= 1 else: break
希尔排序(Shell's Sort)是插入排序的一种又称“缩小增量排序”(Diminishing Increment Sort),是直接插入排序算法的一种更高效的改进版本。希尔排序是非稳定排序算法。
该方法的基本思想是:先将整个待排元素序列分割成若干个子序列(由相隔某个“增量(gap)”的元素组成的)分别进行直接插入排序,然后依次缩减增量再进行排序,待整个序列中的元素基本有序(增量足够小)时,再对全体元素进行一次直接插入排序。因为直接插入排序在元素基本有序的情况下(接近最好情况),效率是很高的,因此希尔排序在时间效率比直接插入排序有较大提高。
def sort(alist): gap = len(alist)//2 while gap >= 1: for j in range(gap,len(alist)): i = j while i > 0: if alist[i] < alist[i-gap]: alist[i],alist[i-gap] = alist[i-gap],alist[i] i -= gap else: break gap = gap // 2
6.快速排序
基本思想是:通过一趟排序将要排序的数据分割成独立的两部分,其中一部分的所有数据都比另外一部分的所有数据都要小,然后再按此方法对这两部分数据分别进行快速排序,整个排序过程可以递归进行,以此达到整个数据变成有序序列。
def sort(alist,start,end): low = start high = end if low >= high: return mid = alist[low] while low < high: while low < high: if alist[high] >= mid: high -= 1 else: alist[low] = alist[high] break while low < high: if alist[low] < mid: low += 1 else: alist[high] = alist[low] break alist[low] = mid sort(alist,start,low-1) sort(alist,high+1,end)
7.归并排序
归并排序(MERGE-SORT)是建立在归并操作上的一种有效的排序算法,该算法是采用分治法(Divide and Conquer)的一个非常典型的应用。将已有序的子序列合并,得到完全有序的序列;即先使每个子序列有序,再使子序列段间有序。
def merge_sort(alist): n = len(alist) #结束递归的条件 if n <= 1: return alist #中间索引 mid = n//2 left_li = merge_sort(alist[:mid]) right_li = merge_sort(alist[mid:]) #指向左右表中第一个元素的指针 left_pointer,right_pointer = 0,0 #合并数据对应的列表:该表中存储的为排序后的数据 result = [] while left_pointer < len(left_li) and right_pointer < len(right_li): #比较最小集合中的元素,将最小元素添加到result列表中 if left_li[left_pointer] < right_li[right_pointer]: result.append(left_li[left_pointer]) left_pointer += 1 else: result.append(right_li[right_pointer]) right_pointer += 1 #当左右表的某一个表的指针偏移到末尾的时候,比较大小结束,将另一张表中的数据(有序)添加到result中 result += left_li[left_pointer:] result += right_li[right_pointer:] return result alist = [3,8,5,7,6] print(merge_sort(alist))
8.各个算法的时间复杂度
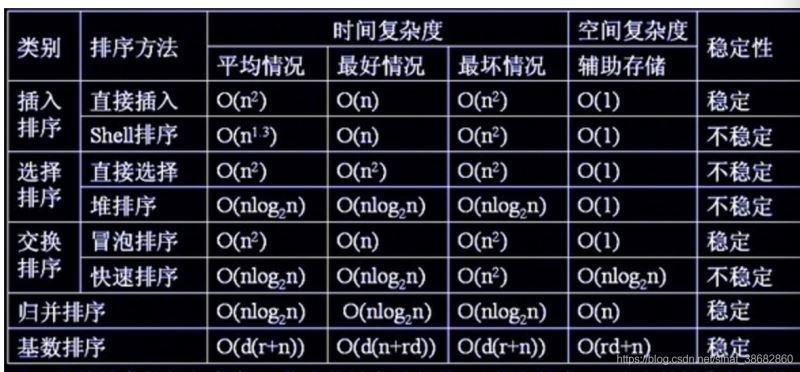
到此这篇关于Python实现七个基本算法的实例代码的文章就介绍到这了,更多相关Python基本算法内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python实现的数据结构与算法之基本搜索详解
本文实例讲述了Python实现的数据结构与算法之基本搜索.分享给大家供大家参考.具体分析如下: 一.顺序搜索 顺序搜索 是最简单直观的搜索方法:从列表开头到末尾,逐个比较待搜索项与列表中的项,直到找到目标项(搜索成功)或者 超出搜索范围 (搜索失败). 根据列表中的项是否按顺序排列,可以将列表分为 无序列表 和 有序列表.对于 无序列表,超出搜索范围 是指越过列表的末尾:对于 有序列表,超过搜索范围 是指进入列表中大于目标项的区域(发生在目标项小于列表末尾项时)或者指越过列表的末尾(发生在目标项
-
Python排序搜索基本算法之归并排序实例分析
本文实例讲述了Python排序搜索基本算法之归并排序.分享给大家供大家参考,具体如下: 归并排序最令人兴奋的特点是:不论输入是什么样的,它对N个元素的序列排序所用时间与NlogN成正比.代码如下: # coding:utf-8 def mergesort(seq): if len(seq)<=1: return seq mid=int(len(seq)/2) left=mergesort(seq[:mid]) right=mergesort(seq[mid:]) return merge(lef
-
Python排序搜索基本算法之冒泡排序实例分析
本文实例讲述了Python排序搜索基本算法之冒泡排序.分享给大家供大家参考,具体如下: 冒泡排序和选择排序类似,也是第n次把最小的元素排在第n的位置上,也是该元素的绝对位置,只是冒泡排序的过程中,其他的元素也逐渐向自己最终位置逼近.代码如下: def bubbleSort(seq): length=len(seq) for i in range(length): for j in range(length-1,i,-1): if seq[j-1]>seq[j]: seq[j-1],seq[j]=
-
Python聚类算法之基本K均值实例详解
本文实例讲述了Python聚类算法之基本K均值运算技巧.分享给大家供大家参考,具体如下: 基本K均值 :选择 K 个初始质心,其中 K 是用户指定的参数,即所期望的簇的个数.每次循环中,每个点被指派到最近的质心,指派到同一个质心的点集构成一个.然后,根据指派到簇的点,更新每个簇的质心.重复指派和更新操作,直到质心不发生明显的变化. # scoding=utf-8 import pylab as pl points = [[int(eachpoint.split("#")[0]), in
-
Python排序搜索基本算法之希尔排序实例分析
本文实例讲述了Python排序搜索基本算法之希尔排序.分享给大家供大家参考,具体如下: 希尔排序是插入排序的扩展,通过允许非相邻的元素进行交换来提高执行效率.希尔排序最关键的是选择步长,本程序选用Knuth在1969年提出的步长序列:1 4 13 40 121 364 1093 3280 ...后一个元素是前一个元素*3+1,非常方便选取,而且效率还不错.代码如下: #-*- coding: UTF-8 -*- def shellSort(seq): length=len(seq) inc=0
-
Python排序搜索基本算法之堆排序实例详解
本文实例讲述了Python排序搜索基本算法之堆排序.分享给大家供大家参考,具体如下: 堆是一种完全二叉树,堆排序是一种树形选择排序,利用了大顶堆堆顶元素最大的特点,不断取出最大元素,并调整使剩下的元素还是大顶堆,依次取出最大元素就是排好序的列表.举例如下,把序列[26,5,77,1,61,11,59,15,48,19]排序,如下: 基于堆的优先队列算法代码如下: def fixUp(a): #在堆尾加入新元素,fixUp恢复堆的条件 k=len(a)-1 while k>1 and a[k//2
-
Python实现七个基本算法的实例代码
1.顺序查找 当数据存储在诸如列表的集合中时,我们说这些数据具有线性或顺序关系. 每个数据元素都存储在相对于其他数据元素的位置. 由于这些索引值是有序的,我们可以按顺序访问它们. 这个过程产实现的搜索即为顺序查找. 顺序查找原理剖析:从列表中的第一个元素开始,我们按照基本的顺序排序,简单地从一个元素移动到另一个元素,直到找到我们正在寻找的元素或遍历完整个列表.如果我们遍历完整个列表,则说明正在搜索的元素不存在. 代码实现:该函数需要一个列表和我们正在寻找的元素作为参数,并返回一个是否存在的布尔值
-
python实现kmp算法的实例代码
kmp算法 kmp算法用于字符串的模式匹配,也就是找到模式字符串在目标字符串的第一次出现的位置 比如 abababc 那么bab在其位置1处,bc在其位置5处 我们首先想到的最简单的办法就是蛮力的一个字符一个字符的匹配,但那样的时间复杂度会是O(m*n) kmp算法保证了时间复杂度为O(m+n) 基本原理 举个例子: 发现x与c不同后,进行移动 a与x不同,再次移动 此时比较到了c与y, 于是下一步移动成了下面这样 这一次的移动与前两次的移动不同,之前每次比较到上面长字符串的字符位置后,直接把模
-
Python找出最小的K个数实例代码
题目描述 输入n个整数,找出其中最小的K个数.例如输入4,5,1,6,2,7,3,8这8个数字,则最小的4个数字是1,2,3,4,. 这个题目完成的思路有很多,很多排序算法都可以完成既定操作,关键是复杂度性的考虑.以下几种思路当是笔者抛砖引玉,如果读者有兴趣可以自己再使用其他方法一一尝试. 思路1:利用冒泡法 临近的数字两两进行比较,按照从小到大的顺序进行交换,如果前面的值比后面的大,则交换顺序.这样一趟过去后,最小的数字被交换到了第一位:然后是次小的交换到了第二位,...,依次直到第k个数,停
-
Python实现孤立随机森林算法的示例代码
目录 1 简介 2 孤立随机森林算法 2.1 算法概述 2.2 原理介绍 2.3 算法步骤 3 参数讲解 4 Python代码实现 5 结果 1 简介 孤立森林(isolation Forest)是一种高效的异常检测算法,它和随机森林类似,但每次选择划分属性和划分点(值)时都是随机的,而不是根据信息增益或基尼指数来选择. 2 孤立随机森林算法 2.1 算法概述 Isolation,意为孤立/隔离,是名词,其动词为isolate,forest是森林,合起来就是“孤立森林”了,也有叫“独异森林”,好
-
用js实现简单算法的实例代码
一.冒泡排序 var arr1=[3,9,2,7,0,8,4]; for(var i=0;i<arr1.length;i++){ for(var j=i+1;j<arr1.length;j++){ var temp=0; if(arr1[i]>arr1[j]){ temp=arr1[i]; arr1[i]=arr1[j]; arr1[j]=temp; } } } alert(arr1); 二.快速排序 var a=[3,5,0,9,2,7,5]; function quickSort(a
-
python 把数据 json格式输出的实例代码
有个要求需要在python的标准输出时候显示json格式数据,如果缩进显示查看数据效果会很好,这里使用json的包会有很多操作 import json date = {u'versions': [{u'status': u'CURRENT', u'id': u'v2.3', u'links': [{u'href': u'http://controller:9292/v2/', u'rel': u'self'}]}, {u'status': u'SUPPORTED', u'id': u'v2.2'
-
python 实现自动远程登陆scp文件实例代码
python 实现自动远程登陆scp文件实例代码 实现实例代码: #!/usr/bin/expect if {$argc!=3} { send_user "Usage: $argv0 {path1} {path2} {Password}\n\n" exit } set path1 [lindex $argv 0] set path2 [lindex $argv 1] set Password [lindex $argv 2] spawn scp ${path1} ${path2} e
-
python将ansible配置转为json格式实例代码
python将ansible配置转为json格式实例代码 ansible的配置文件举例如下,这种配置文件不利于在前端的展现,因此,我们用一段简单的代码将ansible的配置文件转为json格式的: [webserver] 192.168.204.70 192.168.204.71 [dbserver] 192.168.204.72 192.168.204.73 192.168.204.75 [proxy] 192.168.204.76 192.168.204.77 192.168.204.78
-
Python通过Pygame绘制移动的矩形实例代码
Pygame是一个多用于游戏开发的模块. 本文实例主要是在演示框里实现一个移动的矩形实例代码,完整代码如下: #moving rectangle project import pygame from pygame.locals import * pygame.init() screen = pygame.display.set_mode((600,500)) pygame.display.set_caption("Drawing Rectangles") pos_x = 300 pos
-
Python+tkinter模拟“记住我”自动登录实例代码
本文分享的代码主要是通过Python+tkinter模拟"记住我"自动登录的功能,具体介绍如下. 基本思路:如果某次登录成功,则创建临时文件记录有关信息,每次启动程序时尝试自动获取上次登录成功的信息并自动编写.本文主要演示思路,可根据实际系统中的需要进行改写,例如读取数据库并验证用户名和密码是否正确.对用户名和密码进行本地加密存储等等. import tkinter import tkinter.messagebox import os import os.path # 获取Windo