tensorflow之并行读入数据详解
最近研究了一下并行读入数据的方式,现在将自己的理解整理如下,理解比较浅,仅供参考。
并行读入数据主要分
1. 创建文件名列表
2. 创建文件名队列
3. 创建Reader和Decoder
4. 创建样例列表
5. 创建批列表(读取时可要可不要,一般情况下样例列表可以执行读取数据操作,但是在实际训练的时候往往需要批列表来分批进行数据的组织,提取)
其具体流程如下:
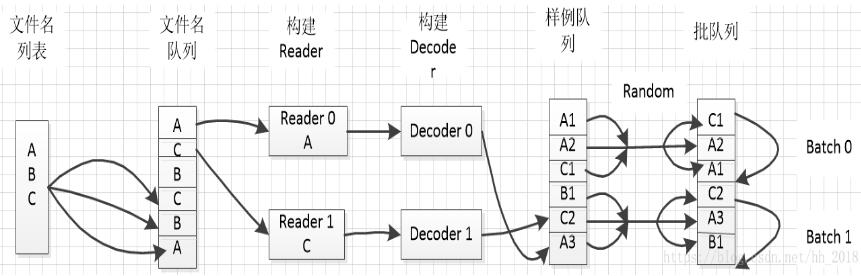
一、 文件名列表:
文件名列表是一个list类型的数据,里面的内容是需要用的数据文件名。可以使用常规的python语法入:[file1, file2]。也可以使用tf.train.match_filename_once方法通过匹配输入。
二、文件名队列
一般使用tf.train.string_input_producer的方法创建文件名队列。该方法传入的是一个文件名列表,输出的是一个先进先出队列。在该方法中存在两个重要参数,num_epochs和shuffle。num_epochs表示列表遍历的次数,主要是由于有时候训练模型需要反复的遍历数据集便于更新模型参数,默认情况下是None(循环遍历)。shuffle表示是否随机遍历,默认情况下是true,表示数据会随机输入队列,当想顺序读入数据时shuffle设置为false。至于其他的capacity表示列表的容量,shared_name表示共享时的名字。
三、Reader和Decoder
Reader的功能是读取数据记录,Decoder的功能是将数据的记录转化为张量格式。在使用时需要先创建输入数据文件对应的Reader,然后从文件名队列中取出文件名,在调用Reader.read的方法返回一个类似于(输入文件名,数据记录)的元组。最后使用Decoder方法将每一列数据都转化为张量的形式。

四、批队列
批队列可以在构建图之前事先构建好,样例队列需要在图中直接产生不用直接预定义。所以先介绍批队列的构建方式。批队列主要是样例打包聚集成批数据,能供模型训练使用。一般是使用tf.train.shuffle_batch和tf.train.batch的方法构建。可以控制批的大小(一次性读入的 数据大小),线程个数,然后在图中直接调用。

五、样例队列
样例队列的创建方式是隐式的,一般在图中为了计算任务顺利的输入数据,我们一般使用tf.train.start_queue_runners方法启动所有的入队操作所需的线程,此时会自动执行所有的文件名入队操作和文件名队列的操作,执行样例队列入队和样例队列的操作。这些都是在后台产生的。
六、线程协调器
并行读取数据离不开多线程操作,多线程操作离不开线程调节器。tensorflow使用tf.train.Coordinatior方法创建管理多线程生命周期的调节器。调节器的工作原理比较简单,它监控Tensoflow后台的所有线程,当某一个线程出现异常时,它的should_stop方法返回true,最后调用request_stop终止所有的线程。但是要注意我们在使用线程调节器之前一定要调用tf.local_variables_initializer方法进行初始化。
七、读入数据类型
tensorflow读入的数据类型可以使csv,TFRecord和自由格式文件。CSV的读取直接调用tf.TextLineReader构建Reader,再调用tf.decoder_csv的方法对文件进行解码变为张量。
TFRecoder是tensorflow标准的输入格式,它是通过protocolBuffer构建的存储数据记录的结构。该数据结构分明,一个样例中包含一组特征Features,一个Features又包含多个特征向量feature。其在读取的时候主要使用tf.TFRecoderReader的方法构建Reader,在使用read的方法读出元组。接着对元组中的value采用tf.parse_single_example()方法进行解析。再解析的时候需要传入features参数,该参数要和构造该文件时输入的字典型变量保持一致(key,value)。key和输入的key一致,value是一个表示该key对应的维度和类型的定西,用tf.FixedLenFeature函数构造,该函数传入参数表示特征形状和特征值的类型。具体如下:

自由格式是指用户自定义的二进制文件,他存储的对象是字符串,每条记录都是一个固定长度的字节块。再读入的时候首先要使用tf.FixedLengthRecoderReader的方法读取对应的二进制文件,然后使用tf.decode_raw的方法将字符串转化为uint8类型的张量。
八、整体代码
具体的相关码如下:


以上这篇tensorflow之并行读入数据详解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-
tensorflow实现对张量数据的切片操作方式
如下所示: import tensorflow as tf a=tf.constant([[[1,2,3,4],[4,5,6,7],[7,8,9,10]], [[11,12,13,14],[20,21,22,23],[15,16,17,18]]]) print(a.shape) b,c=tf.split(a,2,0) #参数1.张量 2.获得的切片数 3.切片的维度 将两个切片分别赋值给b,c print(b.shape) print(c.shape with tf.Session() as s
-
利用Tensorflow的队列多线程读取数据方式
在tensorflow中,有三种方式输入数据 1. 利用feed_dict送入numpy数组 2. 利用队列从文件中直接读取数据 3. 预加载数据 其中第一种方式很常用,在tensorflow的MNIST训练源码中可以看到,通过feed_dict={},可以将任意数据送入tensor中. 第二种方式相比于第一种,速度更快,可以利用多线程的优势把数据送入队列,再以batch的方式出队,并且在这个过程中可以很方便地对图像进行随机裁剪.翻转.改变对比度等预处理,同时可以选择是否对数据随机打乱,可以说是
-
Tensorflow 实现分批量读取数据
之前的博客里使用tf读取数据都是每次fetch一条记录,实际上大部分时候需要fetch到一个batch的小批量数据,在tf中这一操作的明显变化就是tensor的rank发生了变化,我目前使用的人脸数据集是灰度图像,因此大小是92*112的,所以最开始fetch拿到的图像数据集经过reshape之后就是一个rank为2的tensor,大小是92*112的(如果考虑通道,也可以reshape为rank为3的,即92*112*1). 如果加入batch,比如batch大小为5,那么拿到的tensor的
-
tensorflow tf.train.batch之数据批量读取方式
在进行大量数据训练神经网络的时候,可能需要批量读取数据.于是参考了这篇文章的代码,结果发现数据一直批量循环输出,不会在数据的末尾自动停止. 然后发现这篇博文说slice_input_producer()这个函数有一个形参num_epochs,通过设置它的值就可以控制全部数据循环输出几次. 于是我设置之后出现以下的报错: tensorflow.python.framework.errors_impl.FailedPreconditionError: Attempting to use uninit
-
tensorflow mnist 数据加载实现并画图效果
关于 TensorFlow TensorFlow™ 是一个采用数据流图(data flow graphs),用于数值计算的开源软件库.节点(Nodes)在图中表示数学操作,图中的线(edges)则表示在节点间相互联系的多维数据数组,即张量(tensor).它灵活的架构让你可以在多种平台上展开计算,例如台式计算机中的一个或多个CPU(或GPU),服务器,移动设备等等.TensorFlow 最初由Google大脑小组(隶属于Google机器智能研究机构)的研究员和工程师们开发出来,用于机器学习和深度
-
tensorflow使用range_input_producer多线程读取数据实例
先放关键代码: i = tf.train.range_input_producer(NUM_EXPOCHES, num_epochs=1, shuffle=False).dequeue() inputs = tf.slice(array, [i * BATCH_SIZE], [BATCH_SIZE]) 原理解析: 第一行会产生一个队列,队列包含0到NUM_EXPOCHES-1的元素,如果num_epochs有指定,则每个元素只产生num_epochs次,否则循环产生.shuffle指定是否打乱顺
-
使用Tensorflow将自己的数据分割成batch训练实例
学习神经网络的时候,网上的数据集已经分割成了batch,训练的时候直接使用batch.next()就可以获取batch,但是有的时候需要使用自己的数据集,然而自己的数据集不是batch形式,就需要将其转换为batch形式,本文将介绍一个将数据打包成batch的方法. 一.tf.slice_input_producer() 首先需要讲解两个函数,第一个函数是 :tf.slice_input_producer(),这个函数的作用是从输入的tensor_list按要求抽取一个tensor放入文件名队列
-
Tensorflow 多线程与多进程数据加载实例
在项目中遇到需要处理超级大量的数据集,无法载入内存的问题就不用说了,单线程分批读取和处理(虽然这个处理也只是特别简单的首尾相连的操作)也会使瓶颈出现在CPU性能上,所以研究了一下多线程和多进程的数据读取和预处理,都是通过调用dataset api实现 1. 多线程数据读取 第一种方法是可以直接从csv里读取数据,但返回值是tensor,需要在sess里run一下才能返回真实值,无法实现真正的并行处理,但如果直接用csv文件或其他什么文件存了特征值,可以直接读取后进行训练,可使用这种方法. imp
-
tensorflow之并行读入数据详解
最近研究了一下并行读入数据的方式,现在将自己的理解整理如下,理解比较浅,仅供参考. 并行读入数据主要分 1. 创建文件名列表 2. 创建文件名队列 3. 创建Reader和Decoder 4. 创建样例列表 5. 创建批列表(读取时可要可不要,一般情况下样例列表可以执行读取数据操作,但是在实际训练的时候往往需要批列表来分批进行数据的组织,提取) 其具体流程如下: 一. 文件名列表: 文件名列表是一个list类型的数据,里面的内容是需要用的数据文件名.可以使用常规的python语法入:[file1
-

win10 + anaconda3 + python3.6 安装tensorflow + keras的步骤详解
初入深度学习,就遇到了困难,一直安装不了tensorflow和keras库!!!真是让人着急!!!在经过无数次尝试,看了无数篇博客之后,终于安装上了.下面是具体的安装步骤. 首先,创建一个新的环境,这个环境适合python3.5使用: conda create -n py35 python=3.5 anaconda 如果在创建过程中出现如下错误 RemoveError: 'setuptools' is a dependency of conda and cannot be removed fro
-
基于Tensorflow一维卷积用法详解
我就废话不多说了,大家还是直接看代码吧! import tensorflow as tf import numpy as np input = tf.constant(1,shape=(64,10,1),dtype=tf.float32,name='input')#shape=(batch,in_width,in_channels) w = tf.constant(3,shape=(3,1,32),dtype=tf.float32,name='w')#shape=(filter_width,in
-
TensorFlow Autodiff自动微分详解
如下所示: with tf.GradientTape(persistent=True) as tape: z1 = f(w1, w2 + 2.) z2 = f(w1, w2 + 5.) z3 = f(w1, w2 + 7.) z = [z1,z3,z3] [tape.gradient(z, [w1, w2]) for z in (z1, z2, z3)] 输出结果 [[<tf.Tensor: id=56906, shape=(), dtype=float32, numpy=40.0>, <
-
Windows上安装tensorflow 详细教程(图文详解)
一, 前言: 本次安装tensorflow是基于Python的,安装Python的过程不做说明(既然决定按,Python肯定要先了解啊):本次教程是windows下Anaconda安装Tensorflow的过程(cpu版,显卡不支持gpu版的...) 二, 安装环境: (tensorflow支持的系统是64位的,windows和linux,mac都需要64位) windows7(其实和windows版本没什么关系,我的是windows7,安装时参照的有windows10的讲解) Python3.
-
C#多线程开发之任务并行库详解
目录 前言 任务并行库 一.创建任务 二.使用任务执行基本操作 三.处理任务中的异常 总结 前言 之前学习了线程池,知道了它有很多好处. 使用线程池可以使我们在减少并行度花销时节省操作系统资源.可认为线程池是一个抽象层,其向程序员隐藏了使用线程的细节,使我们可以专心处理程序逻辑,而不是各种线程问题. 但也不是说我们所有的项目中都上线程池,其实它也有很多弊端,比如我们需要自定义使用异步委托的方式才可以将线程中的消息或异常传递出来.这些如果在一个大的软件系统中,会导致软件结构过于混乱,各个线程之间消
-
用十张图详解TensorFlow数据读取机制(附代码)
在学习TensorFlow的过程中,有很多小伙伴反映读取数据这一块很难理解.确实这一块官方的教程比较简略,网上也找不到什么合适的学习材料.今天这篇文章就以图片的形式,用最简单的语言,为大家详细解释一下TensorFlow的数据读取机制,文章的最后还会给出实战代码以供参考. TensorFlow读取机制图解 首先需要思考的一个问题是,什么是数据读取?以图像数据为例,读取数据的过程可以用下图来表示: 假设我们的硬盘中有一个图片数据集0001.jpg,0002.jpg,0003.jpg--我们只需要把
-
对Tensorflow中Device实例的生成和管理详解
1. 关键术语描述 kernel 在神经网络模型中,每个node都定义了自己需要完成的操作,比如要做卷积.矩阵相乘等. 可以将kernel看做是一段能够跑在具体硬件设备上的算法程序,所以即使同样的2D卷积算法,我们有基于gpu的Convolution 2D kernel实例.基于cpu的Convolution 2D kernel实例. device 负责运行kernel的具体硬件设备抽象.每个device实例,对应系统中一个具体的处理器硬件,比如gpu:0 device, gpu:1 devic
-
TensorFlow卷积神经网络AlexNet实现示例详解
2012年,Hinton的学生Alex Krizhevsky提出了深度卷积神经网络模型AlexNet,它可以算是LeNet的一种更深更宽的版本.AlexNet以显著的优势赢得了竞争激烈的ILSVRC 2012比赛,top-5的错误率降低至了16.4%,远远领先第二名的26.2%的成绩.AlexNet的出现意义非常重大,它证明了CNN在复杂模型下的有效性,而且使用GPU使得训练在可接受的时间范围内得到结果,让CNN和GPU都大火了一把.AlexNet可以说是神经网络在低谷期后的第一次发声,确立了深
-
详解IOS串行队列与并行队列进行同步或者异步的实例
详解IOS串行队列与并行队列进行同步或者异步的实例 IOS中GCD的队列分为串行队列和并行队列,任务分为同步任务和异步任务,他们的排列组合有四种情况,下面分析这四种情况的工作方式. 同步任务,使用GCD dispatch_sync 进行派发任务 - (void)testSync { dispatch_queue_t serialQueue = dispatch_queue_create("com.zyt.queue", DISPATCH_QUEUE_SERIAL); dispatch_