Python通过VGG16模型实现图像风格转换操作详解
本文实例讲述了Python通过VGG16模型实现图像风格转换操作。分享给大家供大家参考,具体如下:
1、图像的风格转化
卷积网络每一层的激活值可以看作一个分类器,多个分类器组成了图像在这一层的抽象表示,而且层数越深,越抽象
内容特征:图片中存在的具体元素,图像输入到CNN后在某一层的激活值
风格特征:绘制图片元素的风格,各个内容之间的共性,图像在CNN网络某一层激活值之间的关联
风格转换:在一幅图片内容特征的基础上添加另一幅图片的风格特征从而生成一幅新的图片。在卷积模型训练中,通过输入固定的图片来调整网络的参数从而达到利用图片训练网络的目的。而在生成特定风格图片时,固定已有的网络参数不变,调整图片从而使图片向目标风格转化。在内容风格转换时,调整图像的像素值,使其向目标图片在卷积网络输出的内容特征靠拢。在风格特征计算时,通过多个神经元的输出两两之间作内积求和得到Gram矩阵,然后对G矩阵做差求均值得到风格的损失函数。

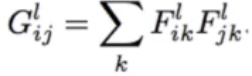
将内容损失函数和风格损失函数对应乘以权重再加起来就得到了总的损失函数,最后的生成图既有内容特征也有风格特征
2、通过Vgg16实现
2.1、预训练模型读取
通过预训练好的Vgg16模型来对图片进行风格转换,首先需要准备好vgg16的模型参数。链接: https://pan.baidu.com/s/1shw2M3Iv7UfGjn78dqFAkA 提取码: ejn8
通过numpy.load()导入并查看参数的内容:
import numpy as np
data=np.load('./vgg16_model.npy',allow_pickle=True,encoding='bytes')
# print(data.type())
data_dic=data.item()
# 查看网络层参数的键值
print(data_dic.keys())
打印键值如下,可以看到分别有不同的卷积和全连接层:
dict_keys([b'conv5_1', b'fc6', b'conv5_3', b'conv5_2', b'fc8', b'fc7', b'conv4_1', b'conv4_2', b'conv4_3', b'conv3_3', b'conv3_2', b'conv3_1', b'conv1_1', b'conv1_2', b'conv2_2', b'conv2_1'])
接着查看具体每层的参数,通过data_dic[key]可以获取到key对应层次的参数,例如可以看到卷积层1_1的权值w为3个3×3的卷积核,对应64个输出通道
# 查看卷积层1_1的参数w,b w,b=data_dic[b'conv1_1'] print(w.shape,b.shape) # (3, 3, 3, 64) (64,) # 查看全连接层的参数 w,b=data_dic[b'fc8'] print(w.shape,b.shape) # (4096, 1000) (1000,)
2.2、构建VGG网络
通过将已经训练好的参数填充到网络之中就可以搭建VGG网络了。
在类初始化函数中读取预训练模型文件中的参数到self.data_dic
首先构建卷积层,通过传入的各个卷积层name参数,读取模型中对应的卷积层参数并填充到网络中。例如读取第一个卷积层的权值和偏置值,传入name='conv1_1,则data_dic[name][0]可以得到权值weight,data_dic[name][1]得到偏置值bias。通过tf.constant构建常量,再执行卷积操作,加偏置项,经激活函数后输出。
接下来实现池化操作,由于池化不需要参数,所以直接对输入进行最大池化操作后输出即可
接着经过展开层,由于卷积池化后的数据是四维向量[batch_size,image_width,image_height,chanel],需要将最后三维展开,将最后三个维度相乘,通过tf.reshape()展开
最后需要把结果经过全连接层,它的实现和卷积层类似,读取权值和偏置参数后进行全连接操作后输出。
class VGGNet:
def __init__(self, data_dir):
data = np.load(data_dir, allow_pickle=True, encoding='bytes')
self.data_dic = data.item()
def conv_layer(self, x, name):
# 实现卷积操作
with tf.name_scope(name):
# 从模型文件中读取各卷积层的参数值
weight = tf.constant(self.data_dic[name][0], name='conv')
bias = tf.constant(self.data_dic[name][1], name='bias')
# 进行卷积操作
y = tf.nn.conv2d(x, weight, [1, 1, 1, 1], padding='SAME')
y = tf.nn.bias_add(y, bias)
return tf.nn.relu(y)
def pooling_layer(self, x, name):
# 实现池化操作
return tf.nn.max_pool(x, ksize=[1, 2, 2, 1], strides=[1, 2, 2, 1], padding='SAME', name=name)
def flatten_layer(self, x, name):
# 实现展开层
with tf.name_scope(name):
# x_shape->[batch_size,image_width,image_height,chanel]
x_shape = x.get_shape().as_list()
dimension = 1
# 计算x的最后三个维度积
for d in x_shape[1:]:
dimension *= d
output = tf.reshape(x, [-1, dimension])
return output
def fc_layer(self, x, name, activation=tf.nn.relu):
# 实现全连接层
with tf.name_scope(name):
# 从模型文件中读取各全连接层的参数值
weight = tf.constant(self.data_dic[name][0], name='fc')
bias = tf.constant(self.data_dic[name][1], name='bias')
# 进行全连接操作
y = tf.matmul(x, weight)
y = tf.nn.bias_add(y, bias)
if activation==None:
return y
else:
return tf.nn.relu(y)
通过self.build()函数实现Vgg16网络的搭建.数据输入后首先需要进行归一化处理,将输入的RGB数据拆分为R、G、B三个通道,再将三个通道分别减去一个固定值,最后将三通道按B、G、R顺序重新拼接为一个新的数据。
接下来则是通过上面的构建函数来搭建VGG网络,依次将五层的卷积池化网络、展开层、三个全连接层的参数读入各层,并搭建起网络,最后经softmax输出
def build(self,x_rgb):
s_time=time.time()
# 归一化处理,在第四维上将输入的图片的三通道拆分
r,g,b=tf.split(x_rgb,[1,1,1],axis=3)
# 分别将三通道上减去特定值归一化后再按bgr顺序拼起来
VGG_MEAN = [103.939, 116.779, 123.68]
x_bgr=tf.concat(
[b-VGG_MEAN[0],
g-VGG_MEAN[1],
r-VGG_MEAN[2]],
axis=3
)
# 判别拼接起来的数据是否符合期望,符合再继续往下执行
assert x_bgr.get_shape()[1:]==[668,668,3]
# 构建各个卷积、池化、全连接等层
self.conv1_1=self.conv_layer(x_bgr,b'conv1_1')
self.conv1_2=self.conv_layer(self.conv1_1,b'conv1_2')
self.pool1=self.pooling_layer(self.conv1_2,b'pool1')
self.conv2_1=self.conv_layer(self.pool1,b'conv2_1')
self.conv2_2=self.conv_layer(self.conv2_1,b'conv2_2')
self.pool2=self.pooling_layer(self.conv2_2,b'pool2')
self.conv3_1=self.conv_layer(self.pool2,b'conv3_1')
self.conv3_2=self.conv_layer(self.conv3_1,b'conv3_2')
self.conv3_3=self.conv_layer(self.conv3_2,b'conv3_3')
self.pool3=self.pooling_layer(self.conv3_3,b'pool3')
self.conv4_1 = self.conv_layer(self.pool3, b'conv4_1')
self.conv4_2 = self.conv_layer(self.conv4_1, b'conv4_2')
self.conv4_3 = self.conv_layer(self.conv4_2, b'conv4_3')
self.pool4 = self.pooling_layer(self.conv4_3, b'pool4')
self.conv5_1 = self.conv_layer(self.pool4, b'conv5_1')
self.conv5_2 = self.conv_layer(self.conv5_1, b'conv5_2')
self.conv5_3 = self.conv_layer(self.conv5_2, b'conv5_3')
self.pool5 = self.pooling_layer(self.conv5_3, b'pool5')
self.flatten=self.flatten_layer(self.pool5,b'flatten')
self.fc6=self.fc_layer(self.flatten,b'fc6')
self.fc7 = self.fc_layer(self.fc6, b'fc7')
self.fc8 = self.fc_layer(self.fc7, b'fc8',activation=None)
self.prob=tf.nn.softmax(self.fc8,name='prob')
print('模型构建完成,用时%d秒'%(time.time()-s_time))
2.3、图像风格转换
首先需要定义网络的输入与输出。网络的输入是风格图像和内容图像,两张图象都是668×668的3通道图片。首先通过PIL库中的Image对象完成读入内容图像style_img和风格图像content_img,并将其转化为数组,定义对应的占位符style_in和content_in,在训练时将图片填入。
网络的输出是一张结果图片668×668的3通道,通过随机函数初始化一个结果图像的数组res_out。
利用上面定义的VGGNet类来创建图片对象,并完成build操作。
vgg16_dir = './data/vgg16_model.npy' style_img = './data/starry_night.jpg' content_img = './data/city_night.jpg' output_dir = './data' def read_image(img): img = Image.open(img) img_np = np.array(img) # 将图片转化为[668,668,3]数组 img_np = np.asarray([img_np], ) # 转化为[1,668,668,3]的数组 return img_np # 输入风格、内容图像数组 style_img = read_image(style_img) content_img = read_image(content_img) # 定义对应的输入图像的占位符 content_in = tf.placeholder(tf.float32, shape=[1, 668, 668, 3]) style_in = tf.placeholder(tf.float32, shape=[1, 668, 668, 3]) # 初始化输出的图像 initial_img = tf.truncated_normal((1, 668, 668, 3), mean=127.5, stddev=20) res_out = tf.Variable(initial_img) # 构建VGG网络对象 res_net = VGGNet(vgg16_dir) style_net = VGGNet(vgg16_dir) content_net = VGGNet(vgg16_dir) res_net.build(res_out) style_net.build(style_in) content_net.build(content_in)
接着需要定义损失函数loss。
对于内容损失,先选定内容风格图像和结果图像的卷积层,要相同,比如这里选取了卷积层1_1和2_1。然后这两个特征层的后三个通道求平方差,然后取均值,就是内容损失。
对于风格损失,首先需要对风格图像和结果图像的特征层求gram矩阵,然后对gram矩阵求平方差的均值。
最后按照系数比例将两个损失函数相加即可得到loss
# 计算损失,分别需要计算内容损失和风格损失 # 提取内容图像的内容特征 content_features = [ content_net.conv1_2, content_net.conv2_2 # content_net.conv2_2 ] # 对应结果图像提取相同层的内容特征 res_content = [ res_net.conv1_2, res_net.conv2_2 # res_net.conv2_2 ] # 计算内容损失 content_loss = tf.zeros(1, tf.float32) for c, r in zip(content_features, res_content): content_loss += tf.reduce_mean((c - r) ** 2, [1, 2, 3]) # 计算风格损失的gram矩阵 def gram_matrix(x): b, w, h, ch = x.get_shape().as_list() features = tf.reshape(x, [b, w * h, ch]) # 对features矩阵作内积,再除以一个常数 gram = tf.matmul(features, features, adjoint_a=True) / tf.constant(w * h * ch, tf.float32) return gram # 对风格图像提取特征 style_features = [ # style_net.conv1_2 style_net.conv4_3 ] style_gram = [gram_matrix(feature) for feature in style_features] # 提取结果图像对应层的风格特征 res_features = [ res_net.conv4_3 ] res_gram = [gram_matrix(feature) for feature in res_features] # 计算风格损失 style_loss = tf.zeros(1, tf.float32) for s, r in zip(style_gram, res_gram): style_loss += tf.reduce_mean((s - r) ** 2, [1, 2]) # 模型内容、风格特征的系数 k_content = 0.1 k_style = 500 # 按照系数将两个损失值相加 loss = k_content * content_loss + k_style * style_loss
接下来开始进行100轮的训练,打印并查看过程中的总损失、内容损失、风格损失值。并将每轮的生成结果图片输出到指定目录下
# 进行训练
learning_steps = 100
learning_rate = 10
train_op = tf.train.AdamOptimizer(learning_rate).minimize(loss)
with tf.Session() as sess:
sess.run(tf.global_variables_initializer())
for i in range(learning_steps):
t_loss, c_loss, s_loss, _ = sess.run(
[loss, content_loss, style_loss, train_op],
feed_dict={content_in: content_img, style_in: style_img}
)
print('第%d轮训练,总损失:%.4f,内容损失:%.4f,风格损失:%.4f'
% (i + 1, t_loss[0], c_loss[0], s_loss[0]))
# 获取结果图像数组并保存
res_arr = res_out.eval(sess)[0]
res_arr = np.clip(res_arr, 0, 255) # 将结果数组中的值裁剪到0~255
res_arr = np.asarray(res_arr, np.uint8) # 将图片数组转化为uint8
img_path = os.path.join(output_dir, 'res_%d.jpg' % (i + 1))
# 图像数组转化为图片
res_img = Image.fromarray(res_arr)
res_img.save(img_path)
运行结果如下可以看到依次分别为内容图片、风格图片、训练12轮、46轮、100轮结果图片





更多关于Python相关内容感兴趣的读者可查看本站专题:《Python数据结构与算法教程》、《Python加密解密算法与技巧总结》、《Python编码操作技巧总结》、《Python函数使用技巧总结》、《Python字符串操作技巧汇总》及《Python入门与进阶经典教程》
希望本文所述对大家Python程序设计有所帮助。
相关推荐
-
Python OpenCV读取png图像转成jpg图像存储的方法
如下所示: import os import cv2 import sys import numpy as np path = "F:\\ImageLib\\VRWorks_360_Video _SDK_1.1\\footage14\\" print(path) for filename in os.listdir(path): if os.path.splitext(filename)[1] == '.png': # print(filename) img = cv2.imread(
-
Python 实现判断图片格式并转换,将转换的图像存到生成的文件夹中
我就废话不多说了,直接上代码吧! import Image from datetime import datetime import os str = '/home/dltest/caffe/examples/sgg_datas/images/result_test/zutest/' + datetime.now().strftime("%Y%m%d_%H%M%S") while True==os.path.exists(str): str = str + datetime.now()
-
Python 将RGB图像转换为Pytho灰度图像的实例
问题: 我正尝试使用matplotlib读取RGB图像并将其转换为灰度. 在matlab中,我使用这个: img = rgb2gray(imread('image.png')); 在matplotlib tutorial中他们没有覆盖它.他们只是在图像中阅读 import matplotlib.image as mpimg img = mpimg.imread('image.png') 然后他们切片数组,但是这不是从我所了解的将RGB转换为灰度. lum_img = img[:,:,0] 编辑:
-
python实现批量nii文件转换为png图像
之前介绍过单个nii文件转换成png图像: https://www.jb51.net/article/165693.htm 这里介绍将多个nii文件(保存在一个文件夹下)转换成png图像.且图像单个文件夹的名称与nii名字相同. import numpy as np import os #遍历文件夹 import nibabel as nib #nii格式一般都会用到这个包 import imageio #转换成图像 def nii_to_image(niifile): filenames =
-
opencv-python 读取图像并转换颜色空间实例
我就废话不多说了,直接上代码吧! #-*- encoding:utf-8 -*- ''' python 绘制颜色直方图 ''' import cv2 import numpy as np from matplotlib import pyplot as plt def readImage(): #读取图片 B,G,R,返回一个ndarray类型 #cv2.IMREAD_COLOR # 以彩色模式读入 1 #cv2.IMREAD_GRAYSCALE # 以灰色模式读入 0 img = cv2.im
-

Python图像处理之图像的缩放、旋转与翻转实现方法示例
本文实例讲述了Python图像处理之图像的缩放.旋转与翻转实现方法.分享给大家供大家参考,具体如下: 图像的几何变换,如缩放.旋转和翻转等,在图像处理中扮演着重要的角色,python中的Image类分别提供了这些操作的接口函数,下面进行逐一介绍. 1.图像的缩放 图像的缩放使用resize()成员函数,直接在入参中指定缩放后的尺寸即可,示例如下: #-*- coding: UTF-8 -*- from PIL import Image #读取图像 im = Image.open("lenna.j
-
在Python下利用OpenCV来旋转图像的教程
OpenCV是应用最被广泛的的开源视觉库.他允许你使用很少的代码来检测图片或视频中的人脸. 这里有一些互联网上的教程来阐述怎么在OpenCV中使用仿射变换(affine transform)旋转图片--他们并没有处理旋转一个图片里的矩形一般会把矩形的边角切掉这一问题,所以产生的图片需要修改.当正确的使用一点代码时,这是一点瑕疵. def rotate_about_center(src, angle, scale=1.): w = src.shape[1] h = src.shape[0] ran
-
Python3+OpenCV2实现图像的几何变换(平移、镜像、缩放、旋转、仿射)
前言 总结一下最近看的关于opencv图像几何变换的一些笔记. 这是原图: 1.平移 import cv2 import numpy as np img = cv2.imread("image0.jpg", 1) imgInfo = img.shape height = imgInfo[0] width = imgInfo[1] mode = imgInfo[2] dst = np.zeros(imgInfo, np.uint8) for i in range( height ): f
-
Python+OpenCV实现将图像转换为二进制格式
在学习tensorflow的过程中,有一个问题,tensorflow在训练的过程中读取的是二进制图像数据库文件,而不是图像文件,因此 在进行训练.测试之前需要将图像文件转换为二进制格式. 下面是我在ubuntu中使用python+OpenCV读取图像并转换为二进制格式文件的代码. #coding=utf-8 ''' Created on 2016年3月24日 使用Opencv读取图像将其保存为二进制格式文件,再读取该二进制文件,转换为图像进行显示 @author: hanchao ''' imp
-
python、PyTorch图像读取与numpy转换实例
Tensor转为numpy np.array(Tensor) numpy转换为Tensor torch.Tensor(numpy.darray) PIL.Image.Image转换成numpy np.array(PIL.Image.Image) numpy 转换成PIL.Image.Image Image.fromarray(numpy.ndarray) 首先需要保证numpy.ndarray 转换成np.uint8型 numpy.astype(np.uint8),像素值[0,255]. 同时灰
-
Python生态圈图像格式转换问题(推荐)
在Python生态圈里,最常用的图像库是PIL--尽管已经被后来的pillow取代,但因为pillow的API几乎完全继承了PIL,所以大家还是约定俗成地称其为PIL.除PIL之外,越来越多的程序员习惯使用openCV来处理图像.另外,在GUI库中,也有各自定义的图像处理机制,比如wxPyton,定义了wx.Image做为图像处理类,定义了wx.Bitmap做为图像显示类. 下图梳理出了PIL读写图像文件.cv2读写图像文件.PIL对象和cv2对象互转.PIL对象和wx.Image对象互转.以及