Python简单爬虫导出CSV文件的实例讲解
流程:模拟登录→获取Html页面→正则解析所有符合条件的行→逐一将符合条件的行的所有列存入到CSVData[]临时变量中→写入到CSV文件中
核心代码:
####写入Csv文件中
with open(self.CsvFileName, 'wb') as csvfile:
spamwriter = csv.writer(csvfile, dialect='excel')
#设置标题
spamwriter.writerow(["游戏账号","用户类型","游戏名称","渠道","充值类型","充值金额","返利金额","单号","日期"])
#将CsvData中的数据循环写入到CsvFileName文件中
for item in self.CsvData:
spamwriter.writerow(item)
完整代码:
# coding=utf-8
import urllib
import urllib2
import cookielib
import re
import csv
import sys
class Pyw():
#初始化数据
def __init__(self):
#登录的Url地址
self.LoginUrl="http://v.pyw.cn/login/check"
#所要获取的Url地址
self.PageUrl="http://v.pyw.cn/Data/accountdetail/%s"
# 传输的数据:用户名、密码、是否记住用户名
self.PostData = urllib.urlencode({
"username": "15880xxxxxx",
"password": "a123456",
"remember": "1"
})
#第几笔记录
self.PageIndex=0;
#循环获取共4页内容
self.PageTotal=1
#正则解析出tr
self.TrExp=re.compile("(?isu)<tr[^>]*>(.*?)</tr>")
#正则解析出td
self.TdExp = re.compile("(?isu)<td[^>]*>(.*?)</td>")
#创建cookie
self.cookie = cookielib.CookieJar()
#构建opener
self.opener=urllib2.build_opener(urllib2.HTTPCookieProcessor(self.cookie))
#解析页面总页数
self.Total=4
#####设置csv文件
self.CsvFileName="Pyw.csv"
#####存储Csv数据
self.CsvData=[]
#解析网页中的内容
def GetPageItem(self,PageHtml):
#循环取出Table中的所有行
for row in self.TrExp.findall(PageHtml):
#取出当前行的所有列
coloumn=self.TdExp.findall(row)
#判断符合的记录
if len(coloumn) == 9:
# print "游戏账号:%s" % coloumn[0].strip()
# print "用户类型:%s" % coloumn[1].strip()
# print "游戏名称:%s" % coloumn[2].strip()
# print "渠道:%s" % coloumn[3].strip()
# print "充值类型:%s" % coloumn[4].strip()
# print "充值金额:%s" % coloumn[5].strip().replace("¥", "")
# print "返利金额:%s" % coloumn[6].strip().replace("¥", "")
# print "单号:%s" % coloumn[7].strip()
# print "日期:%s" % coloumn[8].strip()
#拼凑行数据
d=[coloumn[0].strip(),
coloumn[1].strip(),
coloumn[2].strip(),
coloumn[3].strip(),
coloumn[4].strip(),
coloumn[5].strip().replace("¥", ""),
coloumn[6].strip().replace("¥", ""),
coloumn[7].strip(),
coloumn[8].strip()]
self.CsvData.append(d)
#模拟登录并获取页面数据
def GetPageHtml(self):
try:
#模拟登录
request=urllib2.Request(url=self.LoginUrl,data=self.PostData)
ResultHtml=self.opener.open(request)
#开始执行获取页面数据
while self.PageTotal<=self.Total:
#动态拼凑所要解析的Url
m_PageUrl = self.PageUrl % self.PageTotal
#计算当期第几页
self.PageTotal = self.PageTotal + 1
#获取当前解析页面的所有内容
ResultHtml=self.opener.open(m_PageUrl)
#解析网页中的内容
self.GetPageItem(ResultHtml.read())
####写入Csv文件中
with open(self.CsvFileName, 'wb') as csvfile:
spamwriter = csv.writer(csvfile, dialect='excel')
#设置标题
spamwriter.writerow(["游戏账号","用户类型","游戏名称","渠道","充值类型","充值金额","返利金额","单号","日期"])
#将CsvData中的数据循环写入到CsvFileName文件中
for item in self.CsvData:
spamwriter.writerow(item)
print "成功导出CSV文件!"
except Exception,e:
print "404 error!%s" % e
#实例化类
p=Pyw()
#执行方法
p.GetPageHtml()
导出结果
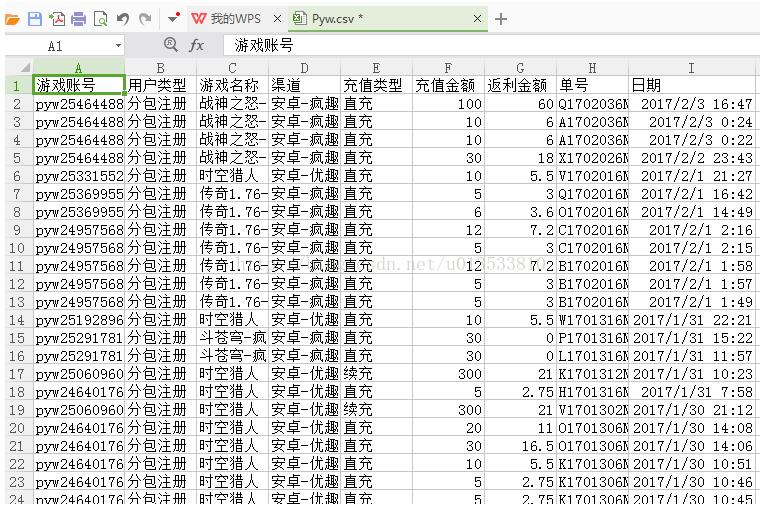
以上这篇Python简单爬虫导出CSV文件的实例讲解就是小编分享给大家的全部内容了,希望能给大家一个参考,也希望大家多多支持我们。
相关推荐
-

Python3爬虫学习之MySQL数据库存储爬取的信息详解
本文实例讲述了Python3爬虫学习之MySQL数据库存储爬取的信息.分享给大家供大家参考,具体如下: 数据库存储爬取的信息(MySQL) 爬取到的数据为了更好地进行分析利用,而之前将爬取得数据存放在txt文件中后期处理起来会比较麻烦,很不方便,如果数据量比较大的情况下,查找更加麻烦,所以我们通常会把爬取的数据存储到数据库中便于后期分析利用. 这里,数据库选择MySQL,采用pymysql 这个第三方库来处理python和mysql数据库的存取,python连接mysql数据库的配置信息 db_
-
Python3实现的爬虫爬取数据并存入mysql数据库操作示例
本文实例讲述了Python3实现的爬虫爬取数据并存入mysql数据库操作.分享给大家供大家参考,具体如下: 爬一个电脑客户端的订单.罗总推荐,抓包工具用的是HttpAnalyzerStdV7,与chrome自带的F12类似.客户端有接单大厅,罗列所有订单的简要信息.当单子被接了,就不存在了.我要做的是新出订单就爬取记录到我的数据库zyc里. 设置每10s爬一次. 抓包工具页面如图: 首先是爬虫,先找到数据存储的页面,再用正则爬出. # -*- coding:utf-8 -*- import re
-
python对csv文件追加写入列的方法
python对csv文件追加写入列,具体内容如下所示: 原始数据 [外链图片转存失败(img-zQSQWAyQ-1563597916666)(C:\Users\innduce\AppData\Roaming\Typora\typora-user-images\1557663419920.png)] import pandas as pd import numpy as np data = pd.read_csv(r'平均值.csv') print(data.columns)#获取列索引值 dat
-
python3爬虫学习之数据存储txt的案例详解
上一篇实战爬取知乎热门话题的实战,并且保存为本地的txt文本 先上代码,有很多细节和坑需要规避,弄了两个半小时 import requests import re headers = { "user-agent" : "Mozilla/5.0 (Windows NT 6.1; Win64; x64)" " AppleWebKit/537.36 (KHTML, like Gecko) Chrome/73.0.3683.86 Safari" &quo
-
python爬虫 猫眼电影和电影天堂数据csv和mysql存储过程解析
字符串常用方法 # 去掉左右空格 'hello world'.strip() # 'hello world' # 按指定字符切割 'hello world'.split(' ') # ['hello','world'] # 替换指定字符串 'hello world'.replace(' ','#') # 'hello#world' csv模块 作用:将爬取的数据存放到本地的csv文件中 使用流程 导入模块 打开csv文件 初始化写入对象 写入数据(参数为列表) import csv with o
-
零基础写python爬虫之抓取百度贴吧并存储到本地txt文件改进版
百度贴吧的爬虫制作和糗百的爬虫制作原理基本相同,都是通过查看源码扣出关键数据,然后将其存储到本地txt文件. 项目内容: 用Python写的百度贴吧的网络爬虫. 使用方法: 新建一个BugBaidu.py文件,然后将代码复制到里面后,双击运行. 程序功能: 将贴吧中楼主发布的内容打包txt存储到本地. 原理解释: 首先,先浏览一下某一条贴吧,点击只看楼主并点击第二页之后url发生了一点变化,变成了: http://tieba.baidu.com/p/2296712428?see_lz=1&pn=
-
Python简单爬虫导出CSV文件的实例讲解
流程:模拟登录→获取Html页面→正则解析所有符合条件的行→逐一将符合条件的行的所有列存入到CSVData[]临时变量中→写入到CSV文件中 核心代码: ####写入Csv文件中 with open(self.CsvFileName, 'wb') as csvfile: spamwriter = csv.writer(csvfile, dialect='excel') #设置标题 spamwriter.writerow(["游戏账号","用户类型","游戏
-
Python使用pandas处理CSV文件的实例讲解
Python中有许多方便的库可以用来进行数据处理,尤其是Numpy和Pandas,再搭配matplot画图专用模块,功能十分强大. CSV(Comma-Separated Values)格式的文件是指以纯文本形式存储的表格数据,这意味着不能简单的使用Excel表格工具进行处理,而且Excel表格处理的数据量十分有限,而使用Pandas来处理数据量巨大的CSV文件就容易的多了. 我用到的是自己用其他硬件工具抓取得数据,硬件环境是在Linux平台上搭建的,当时数据是在运行脚本后直接输出在termin
-
R语言对CSV文件操作实例讲解
在 R 语言中,我们可以从存储在 R 语言环境外的文件中读取数据. 我们还可以将数据写入将被操作系统存储和访问的文件. R 语言可以读取和写入各种文件格式,如csv,excel,xml等. 在本章中,我们将学习从csv文件读取数据,然后将数据写入csv文件. 该文件应该存在于当前工作目录中,以便 R 语言可以读取它. 当然我们也可以设置我们自己的目录并从那里读取文件. 获取和设置工作目录 您可以使用getwd()函数检查R语言工作区指向的目录. 您还可以使用setwd(
-
使用python scrapy爬取天气并导出csv文件
目录 爬取xxx天气 安装 创建scray爬虫项目 文件说明 开始爬虫 补充:scrapy导出csv时字段的一些问题 1.字段顺序问题: 2.输出csv有空行的问题 总结 爬取xxx天气 爬取网址:https://tianqi.2345.com/today-60038.htm 安装 pip install scrapy 我使用的版本是scrapy 2.5 创建scray爬虫项目 在命令行如下输入命令 scrapy startproject name name为项目名称如,scrapy start
-
php导出csv文件,可导出前导0实例代码
实例一:可导出前导0 //导出csv格式文件 $data数据 $title_arr标题 $file_name文件名 function exportCsv($data,$title_arr,$file_name=''){ ini_set("max_execution_time", "3600"); $csv_data = ''; /** 标题 */ $nums = count($title_arr); for ($i = 0; $i < $nums - 1; +
-
Python拆分大型CSV文件代码实例
这篇文章主要介绍了Python拆分大型CSV文件代码实例,文中通过示例代码介绍的非常详细,对大家的学习或者工作具有一定的参考学习价值,需要的朋友可以参考下 #!/usr/bin/env python3 # -*- coding:utf-8 -*- # @FileName :Test.py # @Software PyCharm import os import pandas as pd # filename为文件路径,file_num为拆分后的文件行数 # 根据是否有表头执行不同程序,默认有表头
-
Python读取mat文件,并转为csv文件的实例
初学Python,遇到需要将mat文件转为csv文件,看了很多博客,最后找到了解决办法,代码如下: #方法1 from pandas import Series,DataFrame import pandas as pd import numpy as np import h5py datapath = 'E:/workspacelxr/contem/data.mat' file = h5py.File(datapath,'r') file.keys() def Print(name):prin
-
JAVA导出CSV文件实例教程
以前导出总是用POI导出为Excel文件,后来当我了解到CSV以后,我发现速度飞快. 如果导出的数据不要求格式.样式.公式等等,建议最好导成CSV文件,因为真的很快. 虽然我们可以用Java再带的文件相关的类去操作以生成一个CSV文件,但事实上有好多第三方类库也提供了类似的功能. 这里我们使用apache提供的commons-csv组件 Commons CSV 文档在这里 http://commons.apache.org/ http://commons.apache.org/proper/co
-
应用Java泛型和反射导出CSV文件的方法
本文实例讲述了应用Java泛型和反射导出CSV文件的方法.分享给大家供大家参考.具体如下: 项目中有需求要把数据导出为CSV文件,因为不同的类有不同的属性,为了代码简单,应用Java的泛型和反射,写了一个函数,完成导出功能. 复制代码 代码如下: public <T> void saveFile(List<T> list, String outFile) throws IOException { if (list == null || list.isEmpty())
-
python中pandas读取csv文件时如何省去csv.reader()操作指定列步骤
优点: 方便,有专门支持读取csv文件的pd.read_csv()函数. 将csv转换成二维列表形式 支持通过列名查找特定列. 相比csv库,事半功倍 1.读取csv文件 import pandas as pd file="c:\data\test.csv" csvPD=pd.read_csv(file) df = pd.read_csv('data.csv', encoding='gbk') #指定编码 read_csv()方法参数介绍 filepath_or_buf