Python算法中的时间复杂度问题
在实现算法的时候,通常会从两方面考虑算法的复杂度,即时间复杂度和空间复杂度。顾名思义,时间复杂度用于度量算法的计算工作量,空间复杂度用于度量算法占用的内存空间。

本文将从时间复杂度的概念出发,结合实际代码示例分析算法的时间复杂度。
渐进时间复杂度
时间复杂度是算法运算所消耗的时间,因为不同大小的输入数据,算法处理所要消耗的时间是不同的,因此评估一个算运行时间是比较困难的,所以通常关注的是时间频度,即算法运行计算操作的次数,记为T(n),其中n称为问题的规模。
同样,因为n是一个变量,n发生变化时,时间频度T(n) 也在发生变化,我们称时间复杂度的极限情形称为算法的渐近时间复杂度,记为O(n),不包含函数的低阶和首项系数。
我们以如下 例子来解释一下:

如上例子中,我们根据代码上执行的平均时间假设,计算 run_time(n) 函数的时间复杂度,如下:

上述时间复杂度计算公式T(n) ,是我们对函数 run_time(n) 进行的时间复杂度的估算。当n 值非常大的时候,T(n)函数中常数项 time0 以及n的系数 (time1+time2+time3+time4) 对n的影响也可以忽略不计了,因此这里函数run_time(n) 的时间复杂度我们可以表示为 O(n)。
因为我们计算的是极限状态下(如,n非常大)的时间复杂度,因此其中存在以下两种特性:
低阶项相对于高阶项产生的影响很小,可以忽略不计。 最高项系数对最高项的影响也很小,可以忽略不计。
根据上述两种特性,时间复杂度的计算方法:
1.只取最高阶项,去掉低阶项。
2.去掉最高项的系数。
3.针对常数阶,取时间复杂度为O(1)。
我们通过下面例子理解一下常见的时间复杂度,如下:
时间复杂度:常数阶 O(1)

时间复杂度:线性阶 O(n)

时间复杂度:线性阶 O(n)

时间复杂度:平方阶 O(n^2)

时间复杂度:平方阶 O(n^2)

时间复杂度:平方阶 O(n^2)

时间复杂度:立方阶 O(n^3)

时间复杂度:对数阶 O(logn)
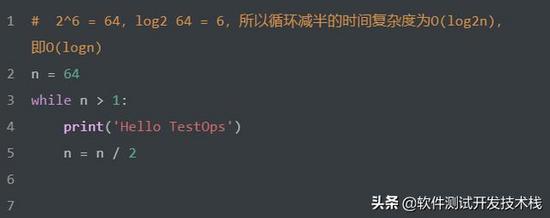
随着问题规模n的不断增大,上述时间复杂度不断增大,算法的执行效率越低,时间复杂度排序如下:

练习一下
如下count_sort 函数实现了计数排序,列表中的数范围都在0到100之间,列表长度大约为100万。

如上count_sort 函数的 空间复杂度为 O(n),公式如下:

总结
以上所述是小编给大家介绍的Python算法中的时间复杂度问题,希望对大家有所帮助,如果大家有任何疑问请给我留言,小编会及时回复大家的。在此也非常感谢大家对我们网站的支持!
如果你觉得本文对你有帮助,欢迎转载,烦请注明出处,谢谢!
相关推荐
-
Python算法的时间复杂度和空间复杂度(实例解析)
算法复杂度分为时间复杂度和空间复杂度. 其作用: 时间复杂度是指执行算法所需要的计算工作量: 而空间复杂度是指执行这个算法所需要的内存空间. (算法的复杂性体现在运行该算法时的计算机所需资源的多少上,计算机资源最重要的是时间和空间(即寄存器)资源,因此复杂度分为时间和空间复杂度). 简单来说,时间复杂度指的是语句执行次数,空间复杂度指的是算法所占的存储空间 计算时间复杂度的方法: 用常数1代替运行时间中的所有加法常数 修改后的运行次数函数中,只保留最高阶项 去除最高阶项的系数 时间复杂度 算法的
-
Python算法中的时间复杂度问题
在实现算法的时候,通常会从两方面考虑算法的复杂度,即时间复杂度和空间复杂度.顾名思义,时间复杂度用于度量算法的计算工作量,空间复杂度用于度量算法占用的内存空间. 本文将从时间复杂度的概念出发,结合实际代码示例分析算法的时间复杂度. 渐进时间复杂度 时间复杂度是算法运算所消耗的时间,因为不同大小的输入数据,算法处理所要消耗的时间是不同的,因此评估一个算运行时间是比较困难的,所以通常关注的是时间频度,即算法运行计算操作的次数,记为T(n),其中n称为问题的规模. 同样,因为n是一个变量,n发生变化时
-
Python算法之栈(stack)的实现
本文以实例形式展示了Python算法中栈(stack)的实现,对于学习数据结构域算法有一定的参考借鉴价值.具体内容如下: 1.栈stack通常的操作: Stack() 建立一个空的栈对象 push() 把一个元素添加到栈的最顶层 pop() 删除栈最顶层的元素,并返回这个元素 peek() 返回最顶层的元素,并不删除它 isEmpty() 判断栈是否为空 size() 返回栈中元素的个数 2.简单案例以及操作结果: Stack Operation Stack Contents Return
-

详解Python数据结构与算法中的顺序表
目录 0. 学习目标 1. 线性表的顺序存储结构 1.1 顺序表基本概念 1.2 顺序表的优缺点 1.3 动态顺序表 2. 顺序表的实现 2.1 顺序表的初始化 2.2 获取顺序表长度 2.3 读取指定位置元素 2.4 查找指定元素 2.5 在指定位置插入新元素 2.6 删除指定位置元素 2.7 其它一些有用的操作 3. 顺序表应用 3.1 顺序表应用示例 3.2 利用顺序表基本操作实现复杂操作 0. 学习目标 线性表在计算机中的表示可以采用多种方法,采用不同存储方法的线性表也有着不同的名称和特
-
python算法深入理解风控中的KS原理
目录 一.业务背景 二.直观理解区分度的概念 三.KS统计量的定义 四.KS计算过程及业务分析 KS常用的计算方法: 上标指标计算逻辑: 五.风控中选择KS的原因 例1:模糊性 例2:连续性 一.业务背景 在金融风控领域,常常使用KS指标来衡量评估模型的区分度(discrimination),这也是风控模型最为追求的指标之一.下面将从区分度概念.KS计算方法.业务指导意义.几何解析.数学思想等角度,对KS进行深入剖析. 二.直观理解区分度的概念 在数据探索中,若想大致判断自变量x对因变量y有没有
-
python算法表示概念扫盲教程
本文为大家讲解了python算法表示概念,供大家参考,具体内容如下 常数阶O(1) 常数又称定数,是指一个数值不变的常量,与之相反的是变量 为什么下面算法的时间复杂度不是O(3),而是O(1). int sum = 0,n = 100; /*执行一次*/ sum = (1+n)*n/2; /*执行一次*/ printf("%d", sum); /*行次*/ 这个算法的运行次数函数是f(n)=3.根据我们推导大O阶的方法,第一步就是把常数项3改为1.在保留最高阶项时发现,它根本没有最高阶
-
Python编程中的反模式实例分析
本文实例讲述了Python编程中的反模式.分享给大家供大家参考.具体分析如下: Python是时下最热门的编程语言之一了.简洁而富有表达力的语法,两三行代码往往就能解决十来行C代码才能解决的问题:丰富的标准库和第三方库,大大节约了开发时间,使它成为那些对性能没有严苛要求的开发任务的首选:强大而活跃的社区,齐全的文档,也使很多编程的初学者选择了它作为自己的第一门编程语言.甚至有国外的报道称,Python已经成为了美国顶尖大学里最受欢迎的编程入门教学语言. 要学好一门编程语言实属不易,在初学阶段,就
-
Python算法之图的遍历
本节主要介绍图的遍历算法BFS和DFS,以及寻找图的(强)连通分量的算法 Traversal就是遍历,主要是对图的遍历,也就是遍历图中的每个节点.对一个节点的遍历有两个阶段,首先是发现(discover),然后是访问(visit).遍历的重要性自然不必说,图中有几个算法和遍历没有关系?! [算法导论对于发现和访问区别的非常明显,对图的算法讲解地特别好,在遍历节点的时候给节点标注它的发现节点时间d[v]和结束访问时间f[v],然后由这些时间的一些规律得到了不少实用的定理,本节后面介绍了部分内容,感
-
python算法与数据结构之冒泡排序实例详解
一.冒泡排序介绍 冒泡排序(英语:Bubble Sort)是一种简单的排序算法.它重复地遍历要排序的数列,一次比较两个元素,如果他们的顺序错误就把他们交换过来.遍历数列的工作是重复地进行直到没有再需要交换,也就是说该数列已经排序完成.这个算法的名字由来是因为越小的元素会经由交换慢慢"浮"到数列的顶端. 二.冒泡排序原理 比较相邻的元素.如果第一个比第二个大,就交换他们两个. 对每一对相邻元素做同样的工作,从开始第一对到结尾的最后一对.这一步做完,最后的元素应该会是最大的数. 针对所有的
-
python算法与数据结构之单链表的实现代码
=一.链表 链表是一种物理存储单元上非连续.非顺序的存储结构,数据元素的逻辑顺序是通过链表中的指针链接次序实现的.链表由一系列结点(链表中每一个元素称为结点)组成,结点可以在运行时动态生成.每个结点包括两个部分:一个是存储数据元素的数据域,另一个是存储下一个结点地址的指针域. 相比于线性表顺序结构,操作复杂.由于不必须按顺序存储,链表在插入的时候可以达到O(1)的复杂度,比另一种线性表顺序表快得多,但是查找一个节点或者访问特定编号的节点则需要O(n)的时间,而线性表和顺序表相应的时间复杂度分别是