Python2与Python3关于字符串编码处理的差别总结
0x00 字符的编码
计算机毕竟是西方国家的发明,最开始并没有想到会普及到全世界,只用一个字节中的7位(ASCII)来表示字符对于现在庞大的文字数量来说显然不够,所以先后经历了好几套编码方案,不同国家和地区又有自己的方案,造成了现在诸多的历史遗留问题。
0x01 Python中的字符串
Python有两种不同的字符串,一种存储文本,一种存储字节。对于文本,Python内部采用Unicode存储,而字节字符串显示原始字节序列或者ASCII。
什么叫编码(encode)?
按照字面意思和以往经验,我要把这个文本或字符串用“UTF-8”编码,感觉上应该是对字节数据进行编码然后显示正确的文字。大多数人都是这么想的,可事实呢?
编码的意思是将Unicode字符按照编码规则(如UTF-8)编成字节序列:

有人此时会问,我用 print 语句打印出来怎么是乱码或者是中文,并不是字节序列。这是因为你调用 print 语句的时候,默认进行了隐式解码,为的是让人类看见友好的字符数据 ,也就是默认的进行了str()包装,想看见背后真正的十六进制数,你需要调用魔术方法 _repr_() 。
什么叫解码(decode)?
对应的,解码就是将字节序列按照编码规则(如UTF-8)解释成unicode形式。
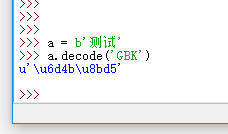
这里或许又会有疑问,编码解码都是十六进制,那中文字符咋显示的?
这又要结合你的环境了。看完我上面推荐的文章,你就会明白,Unicode只是一种标准,而具体的编码才是实现方式。有了正确的Unicode编码,仅仅代表你有了正确的英文文献,想翻译成中文,还得再转换一次。而这一次转换,是你的环境帮你完成。举个例子,你打开一个文档,发现是乱码,多半是文本编辑器的解码方式有问题,换个解码规则就好了。
0x02 Python2 和 Python3 之间的区别
Python3 一切都很美好
在Python3当中,文本字符串类型(使用Unicode数据存储)被命名为 str , 字节字符串类型被命名为 bytes 。一般情况下,实例化一个字符串会得到一个 str 对象 :

所以现在很多人都说,Python3默认是Unicode,也就是这个意思。
如果你想得到bytes,那就在文本之前加上前缀 b , 或者 encode 一下。

所以,很显然,str 对象有一个encode方法,bytes 对象有一个decode方法。
Python2 相当的操蛋,甚至会误导你
在Python3中的 str 对象在Python2中叫做 unicode ,感觉很通俗对吧?但 bytes 对象在Python2中叫做 str ,对。。就是你平时用的 str , 默认的那个。。。
如果你想得到一个文本字符串,你需要在字符串之前加上前缀 u 或者 decode 一下。
搞笑的还不止这么点,Python2中的 str (字节) 对象,竟然有一个 encode 方法!!!而且你别指望它有什么特殊用处,它就是用来报错的,永远都别使用它!!!
同样的,unicode (文本字符) 对象也有一个用来报错的 decode 方法。
我们尝试一下:

不知道大家注意到错误信息没有,我们在进行解码,规则是GBK,但它说 无法用 ascii 进行编码 ,这是为什么?
这就是Python2自作聪明为了对一个unicode对象执行解码而进行的隐式编码 ,等于以下代码:
b.encode('ascii').decode('GBK')
这就是为什么很多人说,Python2的编码很操蛋。
0x03 小结
如果你在用2.X,请养成在字符串加上 u 前缀的习惯,统一编码UTF-8,如果windows控制台或者Pycharm控制台依旧出现乱码,那多半是控制台编码不同,改过来就好。
参考书籍 《Python 高级编程》
总结
到此这篇关于Python2与Python3关于字符串编码处理的差别总结的文章就介绍到这了,更多相关Python2与Python3字符串编码处理差别内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python判断字符串编码的简单实现方法(使用chardet)
本文实例讲述了python判断字符串编码的方法.分享给大家供大家参考,具体如下: 安装chardet模块 chardet文件夹放在/usr/lib/python2.4/site-packages目录下 [root@sha-sso-data01 chardet]# python Python 2.4.3 (#1, Sep 21 2011, 19:55:41) [GCC 4.1.2 20080704 (Red Hat 4.1.2-51)] on linux2 Type "help", &q
-
Python 十六进制整数与ASCii编码字符串相互转换方法
在使用Pyserial与STM32进行通讯时,遇到了需要将十六进制整数以Ascii码编码的字符串进行发送并且将接收到的Ascii码编码的字符串转换成十六进制整型的问题.查阅网上的资料后,均没有符合要求的,遂结合各家之长,用了以下方法. 环境 Python2.7 + Binascii模块 十六进制整数转ASCii编码字符串 # -*- coding: utf-8 -*- import binascii #16进制整数转ASCii编码字符串 a = 0x665554 b = hex(a) #转换成相
-
Python中的字符串操作和编码Unicode详解
本文主要给大家介绍了关于 Python中的字符串操作和编码Unicode的一些知识,下面话不多说,需要的朋友们下面来一起学习吧. 字符串类型 str:Unicode字符串.采用''或者r''构造的字符串均为str,单引号可以用双引号或者三引号来代替.无论用哪种方式进行制定,在Python内部存储时没有区别. bytes:二进制字符串.由于jpg等其他格式的文件不能用str进行显示,所以才用bytes来表示,bytes的每个字节为一个0-255的数字.如果打印的时候,Python会把能够用ASCI
-

详解Python当中的字符串和编码
字符编码 我们已经讲过了,字符串也是一种数据类型,但是,字符串比较特殊的是还有一个编码问题. 因为计算机只能处理数字,如果要处理文本,就必须先把文本转换为数字才能处理.最早的计算机在设计时采用8个比特(bit)作为一个字节(byte),所以,一个字节能表示的最大的整数就是255(二进制11111111=十进制255),如果要表示更大的整数,就必须用更多的字节.比如两个字节可以表示的最大整数是65535,4个字节可以表示的最大整数是4294967295. 由于计算机是美国人发明的,因此,最早只有1
-
Python判断文件和字符串编码类型的实例
python判断文件和字符串编码类型可以用chardet工具包,可以识别大多数的编码类型.但是前几天在读取一个Windows记事本保存的txt文件时,GBK却被识别成了KOI8-R,无解. 然后就自己写了个简单的编码识别方法,代码如下: coding.py # 说明:UTF兼容ISO8859-1和ASCII,GB18030兼容GBK,GBK兼容GB2312,GB2312兼容ASCII CODES = ['UTF-8', 'UTF-16', 'GB18030', 'BIG5'] # UTF-8 B
-
python字符串编码识别模块chardet简单应用
python的字符串编码识别模块(第三方库): 官方地址: http://pypi.python.org/pypi/chardet import chardet import urllib # 可根据需要,选择不同的数据 TestData = urllib.urlopen('http://www.baidu.com/').read() print chardet.detect(TestData) # 运行结果: # {'confidence': 0.99, 'encoding': 'GB2312
-
python字符串与url编码的转换实例
主要应用的场景 爬虫生成带搜索词语的网址 1.字符串转为url编码 import urllib poet_name = "李白" url_code_name = urllib.quote(poet_name) print url_code_name #输出 #%E6%9D%8E%E7%99%BD 2.url编码转为字符串 import urllib url_code_name = "%E6%9D%8E%E7%99%BD" name = urllib.unquote(
-
python使用chardet判断字符串编码的方法
本文实例讲述了python使用chardet判断字符串编码的方法.分享给大家供大家参考.具体分析如下: 最近利用python抓取一些网上的数据,遇到了编码的问题.非常头痛,总结一下用到的解决方案. linux中vim下查看文件编码的命令 set fileencoding python中一个强力的编码检测包 chardet ,使用方法非常简单.linux下利用pip install chardet实现简单安装 import chardet f = open('file','r') fencodin
-
Python中还原JavaScript的escape函数编码后字符串的方法
遇到一个问题需要用Python把JavaScript中escape的中文给还原,但找了大半天,也没有找到答案,只好自己深入研究解决方案. 我们先来看在js中escape一段文字的编码 复制代码 代码如下: a = escape('这是一串文字'); alert(a); 输出: 复制代码 代码如下: %u8FD9%u662F%u4E00%u4E32%u6587%u5B57 咋一看,就感觉有点类似json格式,我们来看看标准的json格式编码同样的汉子"这是一串文字" 复制代码 代码如下:
-
浅谈python下含中文字符串正则表达式的编码问题
前言 Python文件默认的编码格式是ascii ,无法识别汉字,因为ascii码中没有中文. 所以py文件中要写中文字符时,一般在开头加 # -*- coding: utf-8 -*- 或者 #coding=utf-8. 这是指定一种编码格式,意味着用该编码存储中文字符(也可以是gbk.gb2312等). 关于测试的几点注意 -------------------------------------------- 注1:代码中有中文,就要在头部指定编码方式,如果用编辑器写代码,还要注意IDE的