Python爬虫实战之网易云音乐加密解析附源码
目录
- 环境
- 知识点
- 第一步
- 第二步
- 开始代码
- 先导入所需模块
- 请求数据
- 提取我们真正想要的 音乐的名称 id
- 导入js文件
- 保存文件
- 完整代码
环境
- python3.8
- pycharm2021.2
知识点
- requests >>> pip install requests
- execjs >>> pip install PyExecJS
第一步
打开这个网站 在里面去分析我们需要的数据 每个音乐的名称 id
去网页源代码查找数据,发现并没有,这个网页 并不是一个静态页面
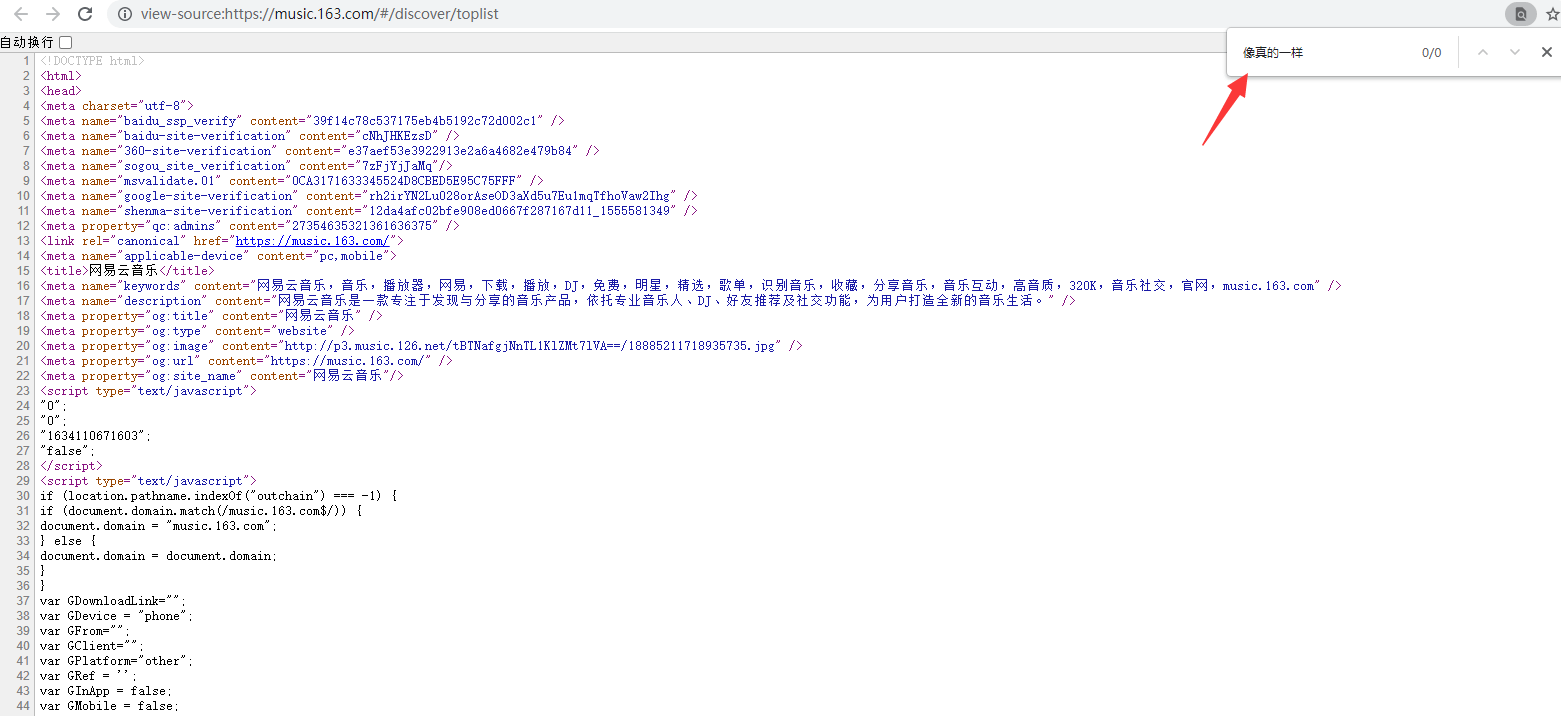
打开开发者工具,找到歌曲的id
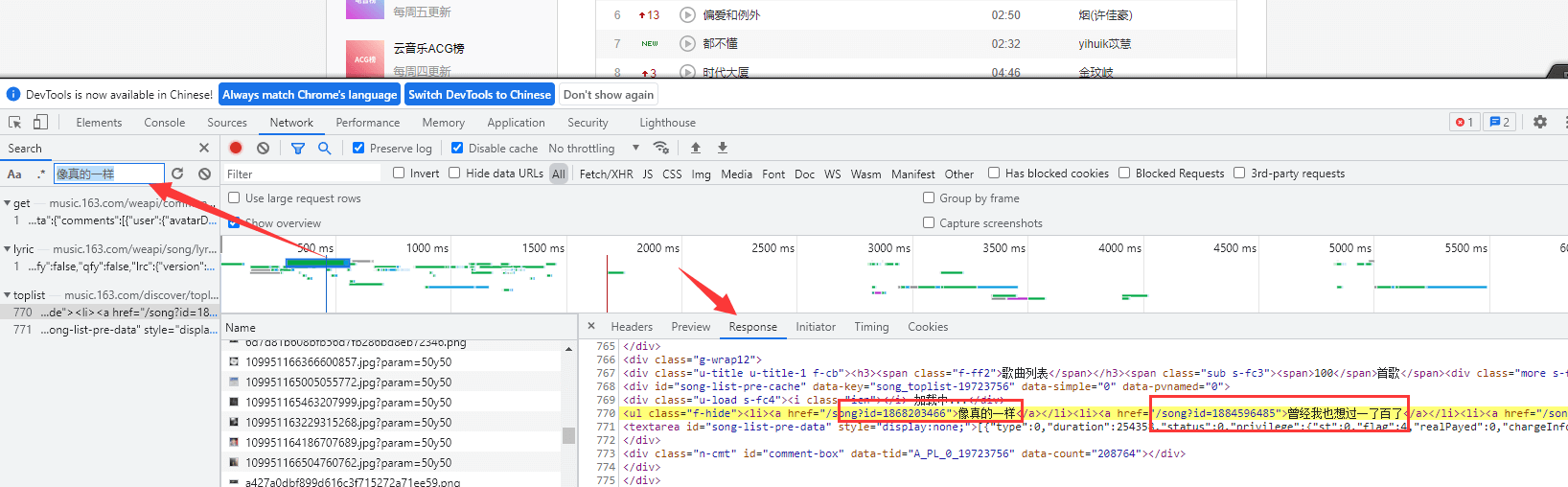
找到真正的目标网址https://music.163.com/discover/toplist
【付费VIP完整版】只要看了就能学会的教程,80集Python基础入门视频教学
第二步
通过代码去实现当前这一个步骤
- 通过代码去访问当这个页面 – 拿到网页源代码
- 提取我们真正想要的 音乐的名称 id
- 下载音乐: id获取是为了下载音乐分析里面音乐数据的 加密规则 去下载歌曲
开始代码
先导入所需模块
import requests import re import execjs
请求数据
# 通过代码去访问当这个页面 -- 拿到网页源代码
url = 'https://music.163.com/discover/toplist'
# 伪装
headers = {
'cookie': '_ntes_nuid=063717de540d3ec18d9b4a0bdf51e931; WM_TID=sxztjH%2FJbYZBEREFBQZvAgttUnJPrvYf; ntes_kaola_ad=1; NMTID=00OSBNvfChgV2TD7k5IhSzky6R8lXgAAAF0zoWmoA; _ntes_nnid=063717de540d3ec18d9b4a0bdf51e931,1607344992641; _iuqxldmzr_=32; OUTFOX_SEARCH_USER_ID_NCOO=2145381542.3273497; WEVNSM=1.0.0; WNMCID=sazafu.1624080681192.01.0; UM_distinctid=17b784cb58a17-097be09ee87fb9-c343365-1aeaa0-17b784cb58b8bc; __root_domain_v=.163.com; _qddaz=QD.159230735652240; vinfo_n_f_l_n3=11aae7905aa2179b.1.11.1575470964063.1625470009945.1632894007779; usertrack=ezq0J2FlcQWNYypxAx88Ag==; JSESSIONID-WYYY=Yvm62%5Cnd8XNkT2ryCNOJx9urqXsxCDMF6srNnGRegtmuNdB5MrrS9ou%2FWw3JbVf960uHnGW3Bb%2Fbhv2xZm3Vn%2B%2BonZSX38sqKiUMuRd6TDKD39HRzGmrZ%5Cp9IUaNs%5C5nYt9xltJBt5qRgWsl0PZsxDhSu26ugGAozPffXXAjemm0o%2Fv%5C%3A1634111694844; WM_NI=au9XpuutN3GwymEoZsAgWl6%2BH4cTcHgYKos%2BWibR3hSntTQhrpX%2FLoCAycOKLnZteLb1LlluoIk9jlKxaaUThS4tfZr9jWB3LVjXKQUH4%2BMpukbEPcnHaN80J8%2FhoqeeYms%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee8de74b85b18eb3b27bae8e8ab2d44e969f9aafae3388af8f98d06da59b968ecf2af0fea7c3b92aa3abf7b9f37fb7ac82d4c67dbbb38b90d97983b9998db5218cecadb5e244a5878590f22195b7aeb3b26491b2bcb5d464b2b098d0cf65819fb784ce4190b29695e848a2ef848def7fad97a5dae96889a8af82d860ac8dfc95e552b2e7a6b8c139908aa6b9ca5b9798fcccd07cb7b5aea6d369ae98afafbb3c8ae8e189ee7ba7bb978ef237e2a3; playerid=29374327',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
# url: 分析出来的真正数据链接
# headers: 伪装请求头
response = requests.get(url, headers).text
# <Response [200]>: 告诉你访问成功了
提取我们真正想要的 音乐的名称 id
zip_data = re.findall('<li><a href="/song\?id=(.*?)" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>', response)
for music_id, title in zip_data:
# url_1 = 'http://music.163.com/song/media/outer/url?id=' + music_id
url_1 = 'https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token='
result = ctx.call('start', music_id)
data = {
'params': result['encText'],
'encSecKey': result['encSecKey']
}
# 发送请求
# 当前的音乐数据
music_url = requests.post(url_1, data=data, headers=headers).json()['data'][0]['url']
music_data = requests.get(music_url, headers).content
title = re.sub(r'[/\\:*?"<>|]', '_', title)
导入js文件
# js文件导入
js = open('music163.js', mode='r', encoding='utf-8').read()
ctx = execjs.compile(js)
保存文件
with open('music/' + title + '.mp3', mode='wb') as f:
f.write(music_data)
print(title)
完整代码
import requests
import re
import execjs
url = 'https://music.163.com/discover/toplist'
# 伪装
headers = {
'cookie': '_ntes_nuid=063717de540d3ec18d9b4a0bdf51e931; WM_TID=sxztjH%2FJbYZBEREFBQZvAgttUnJPrvYf; ntes_kaola_ad=1; NMTID=00OSBNvfChgV2TD7k5IhSzky6R8lXgAAAF0zoWmoA; _ntes_nnid=063717de540d3ec18d9b4a0bdf51e931,1607344992641; _iuqxldmzr_=32; OUTFOX_SEARCH_USER_ID_NCOO=2145381542.3273497; WEVNSM=1.0.0; WNMCID=sazafu.1624080681192.01.0; UM_distinctid=17b784cb58a17-097be09ee87fb9-c343365-1aeaa0-17b784cb58b8bc; __root_domain_v=.163.com; _qddaz=QD.159230735652240; vinfo_n_f_l_n3=11aae7905aa2179b.1.11.1575470964063.1625470009945.1632894007779; usertrack=ezq0J2FlcQWNYypxAx88Ag==; JSESSIONID-WYYY=Yvm62%5Cnd8XNkT2ryCNOJx9urqXsxCDMF6srNnGRegtmuNdB5MrrS9ou%2FWw3JbVf960uHnGW3Bb%2Fbhv2xZm3Vn%2B%2BonZSX38sqKiUMuRd6TDKD39HRzGmrZ%5Cp9IUaNs%5C5nYt9xltJBt5qRgWsl0PZsxDhSu26ugGAozPffXXAjemm0o%2Fv%5C%3A1634111694844; WM_NI=au9XpuutN3GwymEoZsAgWl6%2BH4cTcHgYKos%2BWibR3hSntTQhrpX%2FLoCAycOKLnZteLb1LlluoIk9jlKxaaUThS4tfZr9jWB3LVjXKQUH4%2BMpukbEPcnHaN80J8%2FhoqeeYms%3D; WM_NIKE=9ca17ae2e6ffcda170e2e6ee8de74b85b18eb3b27bae8e8ab2d44e969f9aafae3388af8f98d06da59b968ecf2af0fea7c3b92aa3abf7b9f37fb7ac82d4c67dbbb38b90d97983b9998db5218cecadb5e244a5878590f22195b7aeb3b26491b2bcb5d464b2b098d0cf65819fb784ce4190b29695e848a2ef848def7fad97a5dae96889a8af82d860ac8dfc95e552b2e7a6b8c139908aa6b9ca5b9798fcccd07cb7b5aea6d369ae98afafbb3c8ae8e189ee7ba7bb978ef237e2a3; playerid=29374327',
'user-agent': 'Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/94.0.4606.81 Safari/537.36'
}
response = requests.get(url, headers).text
zip_data = re.findall('<li><a href="/song\?id=(.*?)" rel="external nofollow" rel="external nofollow" >(.*?)</a></li>', response)
js = open('music163.js', mode='r', encoding='utf-8').read()
ctx = execjs.compile(js)
for music_id, title in zip_data:
url_1 = 'https://music.163.com/weapi/song/enhance/player/url/v1?csrf_token='
result = ctx.call('start', music_id)
data = {
'params': result['encText'],
'encSecKey': result['encSecKey']
}
music_url = requests.post(url_1, data=data, headers=headers).json()['data'][0]['url']
music_data = requests.get(music_url, headers).content
title = re.sub(r'[/\\:*?"<>|]', '_', title)
with open('music/' + title + '.mp3', mode='wb') as f:
f.write(music_data)
print(title)
到此这篇关于Python爬虫实战之网易云音乐加密解析附源码的文章就介绍到这了,更多相关Python 网易云音乐解析内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-
python爬取网易云音乐热歌榜实例代码
首先找到要下载的歌曲排行榜的链接,这里用的是: https://music.163.com/discover/toplist?id=3778678 然后更改你要保存的目录,目录要先建立好文件夹,例如我的是保存在D盘-360下载-网易云热歌榜文件夹内,就可以完成下载. 如果文件夹没有提前建好,会报错[Errno 2] No such file or directory. 代码实现: from urllib import request from bs4 import BeautifulSoup i
-

用Python实现网易云音乐的数据进行数据清洗和可视化分析
目录 Python实现对网易云音乐的数据进行一个数据清洗和可视化分析 对音乐数据进行数据清洗与可视化分析 对音乐数据进行数据清洗与可视化分析 歌词文本分析 总结 Python实现对网易云音乐的数据进行一个数据清洗和可视化分析 对音乐数据进行数据清洗与可视化分析 关于数据的清洗,实际上在上一一篇文章关于抓取数据的过程中已经做了一部分,后面我又做了一下用户数据的抓取 歌曲评论: 包括后台返回的空用户信息.重复数据的去重等.除此之外,还要进行一些清洗:用户年龄错误.用户城市编码转换等. 关于数据的去重
-
Python下载网易云歌单歌曲的示例代码
今天写了个下载脚本,记录一下 效果: 直接上代码: # 网易云 根据歌单链接下载MP3歌曲 import requests from bs4 import BeautifulSoup def main(): url = "https://music.163.com/#/playlist?id=3136952023" # 歌单地址 请自行更换 if '/#/' in url: url = url.replace('/#/', '/') headers = { 'Referer': 'ht
-
Python模拟登录网易云音乐并自动签到
一.开发工具 **Python****版本:**3.6.4 相关模块: DecryptLogin模块: argparse模块: 以及一些Python自带的模块. 二.环境搭建 安装Python并添加到环境变量,pip安装需要的相关模块即可. 三.原理简介 既然要签到,首先,自然是需要模拟登录啦,这里我们还是简单地利用我们开源的DecryptLogin库来实现网易云音乐的模拟登录: '''模拟登录''' @staticmethod def login(username, password): lg
-
python 根据列表批量下载网易云音乐的免费音乐
运行效果 代码 # -*- coding:utf-8 -*- import requests, hashlib, sys, click, re, base64, binascii, json, os from Crypto.Cipher import AES from http import cookiejar """ Website:http://cuijiahua.com Author:Jack Cui Refer:https://github.com/darknesso
-
Python爬虫实战之网易云音乐加密解析附源码
目录 环境 知识点 第一步 第二步 开始代码 先导入所需模块 请求数据 提取我们真正想要的 音乐的名称 id 导入js文件 保存文件 完整代码 环境 python3.8 pycharm2021.2 知识点 requests >>> pip install requests execjs >>> pip install PyExecJS 第一步 打开这个网站 在里面去分析我们需要的数据 每个音乐的名称 id 去网页源代码查找数据,发现并没有,这个网页 并不是一个静态页面
-
Python爬虫逆向分析某云音乐加密参数的实例分析
本文转自:https://blog.csdn.net/qq_42730750/article/details/108415551 前言 各大音乐平台是从何时开始收费的这个问题没有追溯过,印象中酷狗在16年就已经开始收费了,貌似当时的收费标准是付费音乐下载一首2元,会员一月8元,可以下载300首.虽然下载收费,但是还可以正常听歌.陆陆续续,各平台不仅收费,而且还更在乎版权问题,因为缺少版权,酷狗上以前收藏的音乐也不能听了,更过分的是,有些歌非VIP会员只能试听60秒(•́へ•́╬). 版权
-
详解python selenium 爬取网易云音乐歌单名
目标网站: 首先获取第一页的数据,这里关键要切换到iframe里 打印一下 获取剩下的页数,这里在点击下一页之前需要设置一个延迟,不然会报错. 结果: 一共37页,爬取完毕后关闭浏览器 完整代码: url = 'https://music.163.com/#/discover/playlist/' from selenium import webdriver import time # 创建浏览器对象 window = webdriver.Chrome('./chromedriver') win
-
Python爬虫实战JS逆向AES逆向加密爬取
目录 爬取目标 工具使用 项目思路解析 简易源码分享 爬取目标 网址:监管平台 工具使用 开发工具:pycharm 开发环境:python3.7, Windows10 使用工具包:requests,AES,json 涉及AES对称加密问题 需要 安装node.js环境 使用npm install 安装 crypto-js 项目思路解析 确定数据 在这个网页可以看到数据是动态返回的 但是 都是加密的 如何确定是我们需要的? 突然想到 如果我分页 是不是会直接加载第二个页面 然后查看相似度 找到第
-
python基于tkinter制作无损音乐下载工具(附源码)
继续写GUI,本次依然使用Tkinter设计一款图形界面,使用Tkinter做一款音乐下载软件,听起来听平常的,但是我这款软件能够下载 无损音乐下载软件,听起来不错吧,Let`s go! 一.准备工作 python Tkinter 二.预览 1.搜索 2.下载 3.结果 无损音乐就这样下载完了. 三.详细设计 这里仅展示我设计的整体思路. 四.源代码 4.1 Music_Search-v1.0.py from tkinter import * from tkinter import ttk fr
-
python爬虫今日热榜数据到txt文件的源码
今日热榜:https://tophub.today/ 爬取数据及保存格式: 爬取后保存为.txt文件: 部分内容: 源码及注释: import requests from bs4 import BeautifulSoup def download_page(url): headers = {"User-Agent": "Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko
-
Python编写一个验证码图片数据标注GUI程序附源码
做验证码图片的识别,不论是使用传统的ORC技术,还是使用统计机器学习或者是使用深度学习神经网络,都少不了从网络上采集大量相关的验证码图片做数据集样本来进行训练. 采集验证码图片,可以直接使用Python进行批量下载,下载完之后,就需要对下载下来的验证码图片进行标注.一般情况下,一个验证码图片的文件名就是图片中验证码的实际字符串. 在不借助工具的情况下,我们对验证码图片进行上述标注的流程是: 1.打开图片所在的文件夹: 2.选择一个图片: 3.鼠标右键重命名: 4.输入正确的字符串: 5.保存 州
-
使用Python给头像加上圣诞帽或圣诞老人小图标附源码
随着圣诞的到来,想给给自己的头像加上一顶圣诞帽.如果不是头像,就加一个圣诞老人陪伴. 用Python给头像加上圣诞帽,看了下大概也都是来自2017年大神的文章:https://zhuanlan.zhihu.com/p/32283641 主要流程 素材准备 人脸检测与人脸关键点检测 调整大小,添加帽子 用dlib的正脸检测器进行人脸检测,用dlib提供的模型提取人脸的五个关键点 调整帽子大小,带帽 选取两个眼角的点,求中心作为放置帽子的x方向的参考坐标,y方向的坐标用人脸框上线的y坐标表示.然后我
-
python opencv实现直线检测并测出倾斜角度(附源码+注释)
由于学习需要,我想要检测出图片中的直线,并且得到这些直线的角度.于是我在网上搜了好多直线检测的代码,但是没有搜到附有计算直线倾斜角度的代码,所以我花了一点时间,自己写了一份直线检测并测出倾斜角度的代码,希望能够帮助到大家! 注:这份代码只能够检测简单结构图片的直线,复杂结构的图片还需要设置合理的参数 下面展示 源码. import cv2 import numpy as np def line_detect(image): # 将图片转换为HSV hsv = cv2.cvtColor(image
-
我用Python给班主任写了一个自动阅卷脚本(附源码)
导语 幼儿园升小学,小学升中学,中学升高中.......... 每个人都要经历的九年义务教育:伴随的都是作业.随堂考.以及每个科目的大大小小的考试.当然小编被考试支配的恐惧以及过去了哈~除了学生考试的压力之外. 有调查发现,目前老师大量的时间被小型考试,如课堂测验.周测等高频次测验的批改客观题.计分.登分等占用,被迫压缩了备课.精准辅导的时间. 今天小编带大家做一款解放教师的自动阅卷系统. 几千张的答题卡扫描录入电脑阅卷系统,老师们只需打开电脑登陆,即可找到自己要批改的那道题. 大大提高了改卷效