C++实现优先队列的示例详解
目录
- 前言
- 堆的存储方式
- 维护堆的方法
- 1、上浮操作
- 2、下沉操作
- 附上代码
前言
首先,啊,先简单介绍一下优先队列的概念,学数据结构以及出入算法竞赛的相信都对队列这一数据结构十分熟悉,这是一个线性的数据结构.
针对队列这一特殊数据结构,有时需考虑队列元素的优先级的关系,即根据用户自定义的优先级排序,出队时优先弹出优先级更高(低)的元素,优先队列能更好地满足实际问题中的需求,而在优先队列的各种实现中,堆是一种最高效的数据结构。
什么是堆
堆是一颗具有特定性质的二叉树,堆的基本要求就是堆中所有结点的值必须大于或等于(或小于或等于)其孩子结点的值,这也称为堆的性质,我们也叫堆序性;堆还有另一个性质,就是当 h > 0 时,所有叶子结点都处于第 h 或 h - 1 层(其中 h 为树的高度,完全二叉树),也就是说,堆应该是一颗完全二叉树;
如下:

根据两种堆序性,我们将堆分为两类,即根节点权值≥子节点权值的我们叫大根堆,根节点权值≤子节点权值的我们叫小根堆。道理简单,就不做图演示了。
上文所述,优先队列是由一个堆维护的,堆序性正对应了优先队列的优先级。由此,优先队列就并不是一个线性的数据结构,其所有操作都是logn的时间复杂度。
了解完堆与优先队列的关系,我们就可以开始讨论如何实现优先对列了。
堆的存储方式
我们将一个堆从上到下从左到右(实际上这个顺序也是堆一般的讨论模式),从0开始给每个节点编号。如下图:
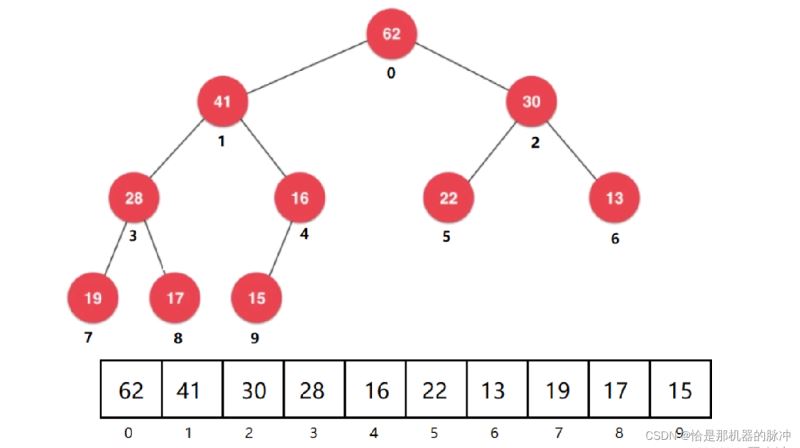
然后按照顺序存储进一个线性的数组之中,那么这就算存储好了~
简不简单?意不意外?是不是最开始想到的是递归生成树?但实际上因为堆序性的存在,我们并不需要那么复杂的存储方式~
同样的道理,我们反过来用一个数组建堆,也就是如上操作的逆操作而已。
问题就来了,如何用一个无序的数组来建堆呢?这就要谈到维护堆序性的两种操作——上浮,下沉。
维护堆的方法
1、上浮操作
首先将一个无序的数组按下标标号,然后开始进行前方所说的建堆操作,我们建堆的过程便是主要用到上浮操作,每操作一步就要与父节点比较,如果大于(此处以大根堆为例子)父节点,则与父节点进行交换,然后跳转到交换后的位置,继续与父节点进行比较,直到不大于父节点后,就算完成了一次调整。光说肯定有些童鞋无法想象得那么明白,下面放图!
这里用数组a[6] = {3,5,8,9,1,2}做模板,别多想,很随机的数字罢了。
第一步,将下标为0的节点做根节点,就是3啦~

第二步,将下标为1的节点也就是5作为3的左孩子~

很明显啊,5要比它的父节点3要大,那么,交换位置~
再看5并没有比它小的根节点了,那么继续下一步~
第三步,将下标为2的节点也就是8,放在5的下边作为右孩子~

很明显哦,8比它的父节点大,那么~,交换位置~

很明显,8并没有比它更小的父节点了,那么继续下一步~
再接下去我就不讲了,很简单,序号从上到下从左到右。
那么任一的一个节点如果它足够大(小),就一定会最底下一层爬到最大的根节点,是不是上浮呢,生动而形象,在建堆的时候每插入一个元素,就要对该元素进行一次上浮调整,将其放在正确的地方。
相信聪明的童鞋已经发现了,同层的节点不存在任何的关系!!!甚至不同根节点的同层节点也不存在任何关系,每一个节点仅仅只是在其子堆中的最大值,即局部最大值。
2、下沉操作
该操作在队列的基本操作,也就是弹出队顶操作时所用,即删除最大(小)根节点的操作。
原理也很简单,将编号为0的节点与编号最大的节点权值互换,然后弹出编号最大的节点(此时即前一步的队顶元素),此时再对队顶节点进行下沉操作:
先与左子树进行比较,按照堆序性交换,直到换回它应在的位置,此时所有局部均为优先队列,其也维护完成。
上图:
这里还是前面那个数组,顺便也给大家看看建堆后的亚子~
a[6] = {3,5,8,9,1,2}

第一步, 将编号为0的节点与编号最大的节点权值互换
即将9与2进行互换。

第二步, 弹出编号最大的节点(此时即前一步的队顶元素)
即9

第三步, 对队顶节点进行下沉操作
即先和8,5进行顺序比较,按照优先级,明显与8互换,换完后如下
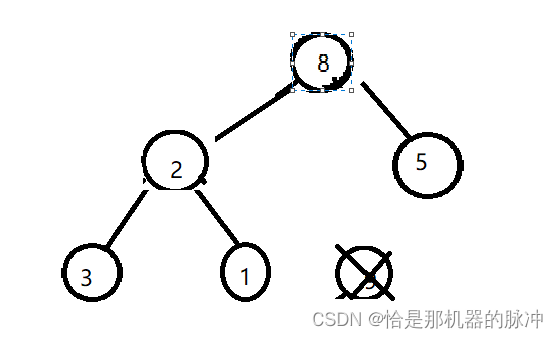
再与3先比较,无法交换再与1比较~最后应该是这个样子的。

两种操作方式也已经说完,这里就会有童鞋问道,那么如何在数组中进行所谓的上浮下沉,操作呢?
这里就有一个很重要的知识了,就是父节点和子节点在数组编号中的关系!
其实也并不难发现,根据堆的性质,有如下的关系:
设某个节点编号为i:
其父节点:dad = (i - 1) / 2
左/右子节点:left = 2 * i + 1
right = 2 * i + 2
这样大家就可以将上浮、下沉操作的每一步在数组中实现了!
附上代码
#include<iostream>
#include<cmath>
#include<stdlib.h>
#define bug cout<<"nug is here"<<endl;
#include<vector>
using namespace std;
typedef size_t ull;
//堆
template<typename P>
class Heap{
private:
vector<int> heap_elem;//堆容器
ull heap_depth;//深度
bool Priority; //优先级
ull heap_size; //容量
void Up_adjust(int now);//上浮调整
void Down_adjust(int now);//下沉调整
//now指代下标
public:
//构造堆
enum{max_heap = true, min_heap = false};
Heap(vector<P> &l, bool priority = max_heap){
heap_size = l.size();
heap_depth = log2(heap_size);
Priority = priority;//设置优先级
for(int i = 0;i < heap_size;i++){
heap_elem.push_back(l[i]);
Up_adjust(i);//上浮调整
}
}
Heap(int a[], ull n, bool priority = max_heap){
heap_size = n;
heap_depth = log2(heap_size);
Priority = priority;//设置优先级
for(int i = 0;i < n;i++){
heap_elem.push_back(a[i]);
Up_adjust(i);//上浮调整
}
}
Heap(){
heap_size = 0;
heap_depth = 0;
Priority = max_heap;
};
//堆的成员函数
ull Depth(){
return heap_depth;
}
ull Size(){
return heap_size;
}
void Push(P x){
heap_elem.push_back(x);
++heap_size;
heap_depth = log2(heap_size);
swap(heap_elem[heap_elem.size() - 1], heap_elem[heap_size - 1]);//将加入的元素放入有效位
Up_adjust(heap_size - 1);
}
void Pop(){
heap_depth = log2(heap_size);
swap(heap_elem[--heap_size], heap_elem[0]);//将第一个元素与最后一个元素交换,并且缩短有效位数
//其实这里可以用vector的函数pop_back(),相应的上面的Push函数也不用换位置,但是这样更快
Down_adjust(0);
}
P &Top(){
return heap_elem[0];
}
void show_as_tree(){//以树的形式输出
int _size = max(log10(heap_elem[0]),log10(heap_elem[heap_size - 1])) + 1;
ull max_size = (pow(2, heap_depth) * 2) * _size;
ull _max_size = _size * pow(2, heap_depth + 1);
int start = -1;
for(int i = 0;i <= heap_depth;i++){
max_size >>= 1;
max_size++;
if(i == heap_depth) cout<<heap_elem[++start];
else printf("%*d",max_size,heap_elem[++start]);
int w = pow(2, i);
for(int j = 1;j < w && start < heap_size - 1;j++) printf("%*d",_max_size,heap_elem[++start]);
_max_size >>= 1;
_max_size++;
printf("\n");
}
}
void show_as_array(){//数组方式输出
for(int i = 0;i < heap_size;i++) cout<<heap_elem[i]<<" ";
cout<<endl;
}
};
//上浮调整
template<typename P>
void Heap<P>::Up_adjust(int now){
if(Priority)
while(now > 0 && heap_elem[now] > heap_elem[(now - 1) / 2]){//如果当前节点的权值比父亲大
swap(heap_elem[now], heap_elem[(now - 1) / 2]);//交换
now = (now - 1) / 2;
}
else
while(now > 0 && heap_elem[now] < heap_elem[(now - 1) / 2]){
swap(heap_elem[now], heap_elem[(now - 1) / 2]);
now = (now - 1) / 2;
}
}
//下沉调整
template<typename P>
void Heap<P>::Down_adjust(int now){
ull left = now * 2 + 1;
ull right;
while(left < heap_size){//能换的时候
left = now * 2 + 1;
right = now * 2 + 2;
if(Priority){
if(heap_elem[now] < heap_elem[left]){//比左孩子小,下沉
swap(heap_elem[now], heap_elem[left]);
now = left;
}
else if(right < heap_size){//比右孩子小,下沉
if(heap_elem[now] > heap_elem[right]){
swap(heap_elem[now], heap_elem[right]);
now = right;
}
}
}
else{
if(heap_elem[now] > heap_elem[left]){//比左孩子大,下沉
swap(heap_elem[now], heap_elem[left]);
now = left;
}
else if(right > heap_size){//比右孩子大,下沉
if(heap_elem[now] < heap_elem[right]){
swap(heap_elem[now], heap_elem[right]);
now = right;
}
}
}
}
}
int main(){
int a[6] = {3,5,8,9,1,2};
Heap<int> h(a, 6, true);
//输出堆
h.show_as_tree();
// h.Push(12);
// h.show_as_tree();
//
// h.Pop();
// h.show_as_tree();
//
// cout<<h.Top()<<endl;
// vector<int> a;
// Heap<int> h(a, Heap<int>::max_heap);
// for(int i=0;i < 10;++i)
// h.Push(rand()%100);
//
// h.show_as_tree();
return 0;
}
按照前面那个数组运行,结果如下:

是不是很神奇呢?
以上就是C++实现优先队列的示例详解的详细内容,更多关于C++优先队列的资料请关注我们其它相关文章!
相关推荐
-

C++高级数据结构之优先队列
目录 前言 高级数据结构(Ⅱ)优先队列(Priority Queue) API 实现 堆的定义 二叉堆表示法 堆的算法 插入元素 删除最大元素 基于堆的优先队列 堆排序 前言 高级数据结构(Ⅱ)优先队列(Priority Queue) API 堆的定义 二叉堆表示法 堆的算法 基于堆的优先队列 堆排序 高级数据结构(Ⅱ)优先队列(Priority Queue) 许多应用程序都需要处理有序的元素,但不一定要求它们全部有序,或是不一定要一次就将它们排序.很多情况下我们会收集一些元素,处理当前键值最大
-
C++ 实现优先队列的简单实例
C++ 实现优先队列的简单实例 优先队列类模版实现: BuildMaxHeap.h头文件: #include<iostream> using namespace std; #define Left(i) i*2+1 #define Right(i) i*2+2 #define Parent(i) (i-1)/2 void Max_Heapify(int a[],int length,int i) { int left,right; left=Left(i); right=Right(i); i
-
C++优先队列用法案例详解
c++优先队列(priority_queue)用法详解 普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除. 在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有最高级先出 (first in, largest out)的行为特征. 首先要包含头文件#include<queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队. 优先队列具有队列的所有特性,包括队列的基本操作,只是在这基础上
-
c++优先队列(priority_queue)用法详解
普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除. 在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有最高级先出 (first in, largest out)的行为特征. 首先要包含头文件#include<queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队列前面,优先出队. 优先队列具有队列的所有特性,包括队列的基本操作,只是在这基础上添加了内部的一个排序,它本质是一个堆实现的. 和队列基本
-
c++优先队列用法知识点总结
c++优先队列用法详解 优先队列也是队列这种数据结构的一种.它的操作不仅局限于队列的先进先出,可以按逻辑(按最大值或者最小值等出队列). 普通的队列是一种先进先出的数据结构,元素在队列尾追加,而从队列头删除. 在优先队列中,元素被赋予优先级.当访问元素时,具有最高优先级的元素最先删除.优先队列具有最高级先出 (first in, largest out)的行为特征. 首先要包含头文件#include<queue>, 他和queue不同的就在于我们可以自定义其中数据的优先级, 让优先级高的排在队
-
C++实现优先队列的示例详解
目录 前言 堆的存储方式 维护堆的方法 1.上浮操作 2.下沉操作 附上代码 前言 首先,啊,先简单介绍一下优先队列的概念,学数据结构以及出入算法竞赛的相信都对队列这一数据结构十分熟悉,这是一个线性的数据结构. 针对队列这一特殊数据结构,有时需考虑队列元素的优先级的关系,即根据用户自定义的优先级排序,出队时优先弹出优先级更高(低)的元素,优先队列能更好地满足实际问题中的需求,而在优先队列的各种实现中,堆是一种最高效的数据结构. 什么是堆 堆是一颗具有特定性质的二叉树,堆的基本要求就是堆中所有结点
-
C++示例详解Prim算法与优先队列
目录 Prim算法 prim代码实现 优先队列 优先队列代码实现 自定义类型优先序列 贪心算法的本质是:一个问题的局部最优解,也是该问题的全局最优解. 最小生成树的最优子结构性质:假设一个无向图包含两部分A,B,其中A为最小生成树部分,B为剩余部分,则存在以下性质:该无向图中一个顶点在A部分,另一个顶点在B部分的边中,权值最小的边一定属于整个无向图的最小生成树,即部分最小权值是整个最小生成树的局部最有解,该性质符合贪心算法的特点. Prim算法 基于最小生成树的该性质,使用prim算法来求解最小
-
Java基本语法之内部类示例详解
目录 1.内部类概念及分类 2.实例内部类 2.1实例内部类的创建 2.2使用.this和.new 2.3内部类实现迭代打印 2.4内部类的继承 3.静态内部类 4.匿名内部类 1.内部类概念及分类 将一个类定义在另一个类的内部或者接口内部或者方法体内部,这个类就被称为内部类,我们不妨将内部类所在的类称为外围类,除了定义在类,接口,方法中的内部类,还有一种特殊的内部类,那就是使用关键字new创建一个匿名类的对象,而这个匿名类其实就是一个内部类,具体说是一个匿名内部类,经常用于传入构造器实参构造对
-
C++实现贪心算法的示例详解
目录 区间问题 区间选点 最大不相交区间数量 区间分组 区间覆盖 Huffman树 合并果子 排序不等式 排队打水 绝对值不等式 货舱选址 区间问题 区间选点 给定 N 个闭区间 [ai,bi],请你在数轴上选择尽量少的点,使得每个区间内至少包含一个选出的点. 输出选择的点的最小数量. 位于区间端点上的点也算作区间内. 输入格式 第一行包含整数 N,表示区间数. 接下来 N 行,每行包含两个整数 ai,bi,表示一个区间的两个端点. 输出格式 输出一个整数,表示所需的点的最小数量. 数据范围 1
-
Java 数据结构算法Collection接口迭代器示例详解
目录 Java合集框架 Collection接口 迭代器 Java合集框架 数据结构是以某种形式将数据组织在一起的合集(collection).数据结构不仅存储数据,还支持访问和处理数据的操作 在面向对象的思想里,一种数据结构也被认为是一个容器(container)或者容器对象(container object),它是一个能存储其他对象的对象,这里的其他对象常被称为数据或者元素 定义一种数据结构从实质上讲就是定义一个类.数据结构类应该使用数据域存储数据,并提供方法支持查找.插入和删除等操作 Ja
-
AngularJS的Filter的示例详解
贴上几个有关Filter使用的几个示例. 1. 首先创建一个表格 <body ng-app="app"> <div class="divAll" ng-controller="tableFilter"> <input type="text" placeholder="输入你要搜索的内容" ng-model="key"> <br><br
-
bat批处理 if 命令示例详解
if 命令示例详解 if,正如它E文中的意思,就是"如果"的意思,用来进行条件判断.翻译过来的意思就是:如果符合某一条件,便执行后面的命令. 主要用来判断,1.两个"字符串"是否相等:2.两个数值是大于.小于.等于,然后执行相应的命令. 当然还有特殊用法,如结合errorlevel:if errorlevel 1 echo error 或者结合defined(定义的意思):if defined test (echo It is defined) else echo
-
Docker-Compose的使用示例详解
Docker Compose是一个用来定义和运行复杂应用的Docker工具.使用Compose,你可以在一个文件中定义一个多容器应用,然后使用一条命令来启动你的应用,完成一切准备工作. - github.com/docker/compose docker-compose是用来在Docker中定义和运行复杂应用的工具,比如在一个yum文件里定义多个容器,只用一行命令就可以让一切就绪并运行. 使用docker compose我们可以在Run的层面解决很多实际问题,如:通过创建compose(基于YU
-
jQuery.Validate表单验证插件的使用示例详解
jQuery Validate 插件为表单提供了强大的验证功能,让客户端表单验证变得更简单,同时提供了大量的定制选项,满足应用程序各种需求. 请在这里查看示例 validate示例 示例包含 验证错误时,显示红色错误提示 自定义验证规则 引入中文错误提示 重置表单需要执行2句话 源码示例 <!DOCTYPE html> <html lang="en"> <head> <meta charset="UTF-8"> <
-
JavaScript中自带的 reduce()方法使用示例详解
1.方法说明 , Array的reduce()把一个函数作用在这个Array的[x1, x2, x3...]上,这个函数必须接收两个参数,reduce()把结果继续和序列的下一个元素做累积计算,其效果就是: [x1, x2, x3, x4].reduce(f) = f(f(f(x1, x2), x3), x4) 2. 使用示例 'use strict'; function string2int(s){ if(!s){ alert('the params empty'); return; } if