R语言中assign函数和get函数的用法
assign函数在循环时候,给变量赋值,算是比较方便
1、给变量赋值
for (i in 1:(length(rowSeq)-1)){
assign(paste("nginx_server_fields7_", i, sep = ""), nginx_server_fields7[(rowSeq[(i-1)+1]):(rowSeq[i+1]), ])
}
2、通过for循环给变量a1、a2、a3赋值
for (i in 1:3){
assign(paste("a", i, sep = ""), i:10)
}
ls()
[1] "a1" "a2" "a3" "i"
> a1
[1] 1 2 3 4 5 6 7 8 9 10
> a2
[1] 2 3 4 5 6 7 8 9 10
3、get和assign联合用法
rm(list = ls()) #这个命令千万慎重使用
for(i in 1:3){
assign(paste("p", i, sep=""), i)
tmp <- get(paste("p", i, sep=""))
print(tmp)
}
[1] 1
[1] 2
[1] 3
ls()
[1] "i" "p1" "p2" "p3" "tmp"
补充:R语言函数的简单理解
R语言结合了面向对象编程语言和函数式编程语言的特性,由于拥有函数式编程的特性,R的每一个运算符,实际上也是函数,同样,面向对象的特性决定了你接触到的R中所有东西(从数字到字符串到矩阵等)都是对象。
这些综合的特质决定了R这门语言的特殊性,最大的特点就是开源,R中有许多用户无私贡献的包,通过这些包,可以实现强大的功能,因此,在在的统计处理或者数据挖掘等数据处理相关工作中,R常常作为数据预处理和建立初步模型的强大工具,但作为一门解释型语言,R的运行效率比不上同等下的C等编译型语言,特别是在高性能计算中。
因此,个人认为未来或者是现在将流行这样一种数据处理方式:用R对数据进行预处理,同时通过R建立初步的数据处理模型,待对模型进行评估并确定如何实施之后通过更高效的语言(C语言等)来实现。
R中变量作用域的层次结构同C语言类似,但最大的不同在于,在R函数中可以创建新的函数,这样会增加新的层次。
R拥有函数式编程的特性,基于函数式编程语言的特征,函数不会修改非局部变量,在R中,函数几乎没有副作用,简单的理解为,函数的一般代码可以读但是不能写非全局变量(当然通过特定函数是可以修改全局变量的)。
一般代码表面上可以给全局变量重新赋值,但实际上这些操作只会修改全局变量在特定层次中的备份,而全局变量本身不会发生变化。如下面例子所示:
i <- 1
test <- function(){
i <- 2
print(sprintf("the value from test(): %i", i))
}
test()
print(sprintf("the value from global:%i", i))
执行以上代码,结果如下所示:

在以上代码中,i是全局变量,顺序执行test()函数,在test中给i赋值为2,此时打印的结果是局部变量中的值。test()函数执行完之后再打印i的值,结果却仍然是1,说明test中的赋值并没有修改全局变量i。
一般情况下,使用R中的函数不会有副作用,可以有以下几点理解:
1)只引用而不改变全局变量,局部变量与全局变量共享内存空间,此时的值必然相同;
2)一旦函数对全局变量重新赋值,系统将会创建一个与全局变量同名的新变量,并为这个变量分配新的内存空间,但这个新变量只处在宿主函数这个层次中,根据变量的引用关系,优先引用离自己较近的本层或者上层环境中变量,所以在该函数中基本上只会用全局变量的同名局部变量了;
3)随着函数调用结束,系统会释放函数中的局部变量,新创建的全局变量的同名局部变量也将销毁,而全局变量的值并没有因为在函数中使用而发生变化。
当然,R中也提供了特定的函数来对函数的上级层次进行写操作,那就是<<-和assign()。
1.超赋值运算符<<-的机理为:使用<<-进行赋值操作
系统会从第一个上级层次开始,由低到高逐层进行查找,直到在某个层次中找到该变量,如果找不到该变量,系统会在顶层环境中创建一个新的变量。注意,超赋值运算符<<-只查上级,不会对本级进行查找。
如下例所示:
A)
i <- 1
testA <- function()
{
i <<- 2
print(sprintf("the value from testA(): %i", i))
}
testA()
print(sprintf("the value from global:%i", i))
B)
testB<-function()
{
i<<-2
print(sprintf("the value from testB(): %i", i))
}
testB()
print(sprintf("the value from global:%i", i))
结果如下:
A)

B)

两次运行的结果相同,在A)中,<<-修改了全局变量值i,在testA函数中引用了修改后的值,结果为2,在B)中,<<-向上查找,没有找到名为i的全局变量,但是系统在全局环境中创建了名为i的全局变量并为其赋值为2。
2.使用assign()函数来对非局部变量进行写操作
该函数的特性为:向指定层次(本级或上级)中的某个变量赋值,有则修改,无则创建。
如下代码所示:
test <-function()
{
i <- 1
innertest<-function(x)
{
i<-3
assign("i",2*x,pos=.GlobalEnv)
print(sprintf("the value from innertest(): %i",i))
}
innertest(5)
print(sprintf("the value from test(): %i", i))
}
test()
print(sprintf("the value from global:%i", i))
结果为:
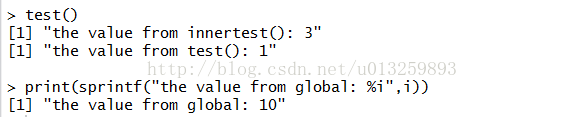
由结果可知,在test()和innertest()中的i值都没有发生变化,而在最顶层的全局层次中没有定义i的值,结果显示该值为10。
原因在于,在函数test()内部定义的函数innertest()中执行了assign函数,该函数在最顶层全局层次中的变量i赋值10,但是该层中并没有该变量,于是就就在最顶层.GlobalEnv中创建了该变量i并给其赋值,这样在不同的函数层次中都有变量i,优先引用离自己最近的同级(已顺序执行)或者上级层次中的变量,所以i出现了三个不同的输出值。
以上为个人经验,希望能给大家一个参考,也希望大家多多支持我们。如有错误或未考虑完全的地方,望不吝赐教。
相关推荐
-
R语言中if(){}else{}语句和ifelse()函数的区别详解
首先看看定义: # if statement if(cond) expr if(cond) cons.expr else alt.expr # ifelse function ifelse(test, yes, no) 这两个函数(R语言中都是函数)相同的地方都是根据条件返回对应的值. 区别在于: if语句的条件是个TRUE/FALSE值,如果是个长度>1的逻辑向量,只判断第一个TRUE/FALSE值:而ifelse是长度任意的逻辑向量,返回根据逻辑向量对应对的yes/no值组合的新向量 ife
-

R语言中cut()函数的用法说明
R语言cut()函数使用 cut()切割将x的范围划分为时间间隔,并根据其所处的时间间隔对x中的值进行编码. 参数:breaks:两个或更多个唯一切割点或单个数字(大于或等于2)的数字向量,给出x被切割的间隔的个数. breaks采用fivenum():返回五个数据:最小值.下四分位数.中位数.上四分位数.最大值. labels为区间数,打标签 ordered_result 逻辑结果应该是一个有序的因素吗? 先用fivenum求出5个数,再用labels为每两个数之间,贴标签,采用(]的区间,
-
R语言-summary()函数的用法解读
summary():获取描述性统计量,可以提供最小值.最大值.四分位数和数值型变量的均值,以及因子向量和逻辑型向量的频数统计等. 结果解读如下: 1. 调用:Call lm(formula = DstValue ~ Month + RecentVal1 + RecentVal4 + RecentVal6 + RecentVal8 + RecentVal12, data = trainData) 当创建模型时,以上代码表明lm是如何被调用的. 2. 残差统计量:Residuals Min 1Q M
-
R语言中c()函数与paste()函数的区别说明
c()函数:将括号中的元素连接起来,并不创建向量 paste()函数:连接括号中的元素 例如 c(1, 2:4),结果为1 2 3 4 paste(1, 2:4),结果为"1 2" "1 3" "1 4" c(2, "and"),结果为"2" "and" paste(2, "and"),结果为"2 and" 补充:R语言中paste函数的参数sep
-
R语言中的fivenum与quantile()函数算法详解
fivenum()函数: 返回五个数据:最小值.下四分位数数.中位数.上四分位数.最大值 对于奇数个数字=5,fivenum()先排序,依次返回最小值.下四分位数.中位数.上四分位数.最大值 > fivenum(c(1,12,40,23,13)) [1] 1 12 13 23 40 对于奇数个数字>5,fivenum()先排序,我们可以求取最小值,最大值,中位数.在排序中,最小值与中位数中间,若为奇数,取其中位数为下四分位数,若为偶数,取最中间两个数的平均值为下四分位数:在排序中,中位数与最大
-
R语言-生成频数表和列联表crosstable函数介绍
列联表crosstable 列联表不仅可以用来做简单的描述性统计,还可以在机器学习中用来比较识别正确率,FPR,TPR等等数据,以便我们比较不同的ML模型 or 调参. 2x2列联表一般长下面这样: Total Observations in Table: 143 | test_cancer$diagnosis lda.class | 0 | 1 | Row Total | -------------|-----------|-----------|-----------| 0 | 82 | 1
-
R语言:数据筛选match的使用详解
数据筛选是在分析中最常用的步骤,如微生物组分析中,你的OTU表.实验设计.物种注释之间都要不断筛选,来进行数据对齐,或局部分析. 今天来详解一下此函数的用法. match match:匹配两个向量,返回x中存在的返回索引或TRUE.FALSE match函数使用格式有如下两种: 第一种方便设置参数,返回x中元素在table中的位置 match(x, table, nomatch = NA_integer_, incomparables = NULL) 第二种简洁,返回x中每个元素在table中是
-
R语言中assign函数和get函数的用法
assign函数在循环时候,给变量赋值,算是比较方便 1.给变量赋值 for (i in 1:(length(rowSeq)-1)){ assign(paste("nginx_server_fields7_", i, sep = ""), nginx_server_fields7[(rowSeq[(i-1)+1]):(rowSeq[i+1]), ]) } 2.通过for循环给变量a1.a2.a3赋值 for (i in 1:3){ assign(paste(&quo
-
R语言中na.fail和na.omit的用法
实际工作中,数据集很少是完整的,许多情况下样本中都会包括若干缺失值NA,这在进行数据分析和挖掘时比较麻烦. R语言通过na.fail和na.omit可以很好地处理样本中的缺失值 1.na.fail(<向量a>): 如果向量a内包括至少1个NA,则返回错误:如果不包括任何NA,则返回原有向量a 2.na.omit(<向量a>): 返回删除NA后的向量a 3.attr( na.omit(<向量a>) ,"na.action"): 返回向量a中元素为NA的
-
R语言中ifelse、which、%in%的用法详解
ifelse.which.%in%是R语言里极其重要的函数,以后会经常在别的程序中看到. ifelse ifelse是if条件判断语句的简写,它的用法如下: ifelse(test,yes,no) 参数 描述 test 一个可以判断逻辑表达式 yes 判断为 true 后返回的对象 no 判断为 flase 后返回的对象 举例: x = 5 ifelse(x,1,0) 如果x不等于0,就返回1,等于0就返回0. which which 返回条件为真的句柄,给正确的逻辑对象返回一个它的索引. wh
-
R语言中cbind、rbind和merge函数的使用与区别
cbind: 根据列进行合并,即叠加所有列,m列的矩阵与n列的矩阵cbind()最后变成m+n列,合并前提:cbind(a, c)中矩阵a.c的行数必需相符 rbind: 根据行进行合并,就是行的叠加,m行的矩阵与n行的矩阵rbind()最后变成m+n行,合并前提:rbind(a, c)中矩阵a.c的列数必需相符 > a <- matrix(1:12, 3, 4) > print(a) [,1] [,2] [,3] [,4] [1,] 1 4 7 10 [2,] 2 5 8 11 [3,
-
R语言中merge函数详解
1.创建测试数据: name <- c('A','B','A','A','C','D') school <- c('s1','s2','s1','s1','s1','s3') class <- c(10, 5, 4, 11, 1, 8) English <- c(85, 50, 90 ,90, 12, 96) w <- data.frame(name, school, class, English) w name <- c('A','B','C','F') school
-
R语言中set.seed()函数的作用详解
目录 001.首先查看不使用set.seed函数的情况 002.使用set.seed函数的情况 003.改变种子序号的情况 R语言中set.seed()函数的作用是保证前后生成的随机数保持一致. 001.首先查看不使用set.seed函数的情况 x=rnorm(10) ## 生成10个平均值为0, 标准差为1的符合正太分布的随机数 x plot(x) 再次运行以上代码(可以发现生成的随机数发生了编号): x=rnorm(10) x plot(x) 002.使用set.seed函数的情况 set.
-
C语言中strlen() strcpy() strcat() strcmp()函数的实现方法
strlen函数原型:unsigned int strlen(const char *);返回的是字符串中第一个\0之前的字符个数. 1.strcat函数原型char* strcat(char* dest,const char* src); 进行字符串的拼接,将第二个字符串连接到第一个字符串中第一个出现\0开始的地方.返回的是拼接后字符的首地址.并不检查第一个数组的大小是否可以容纳第二个字符串.如果第一个数组的已分配的内存不够容纳第二个字符串,则多出来的字符将会溢出到相邻的内存单元. 2.str