Python异步爬虫实现原理与知识总结
一、背景
默认情况下,用get请求时,会出现阻塞,需要很多时间来等待,对于有很多请求url时,速度就很慢。因为需要一个url请求的完成,才能让下一个url继续访问。一种很自然的想法就是用异步机制来提高爬虫速度。通过构建线程池或者进程池完成异步爬虫,即使用多线程或者多进程来处理多个请求(在别的进程或者线程阻塞时)。
import time
#串形
def getPage(url):
print("开始爬取网站",url)
time.sleep(2)#阻塞
print("爬取完成!!!",url)
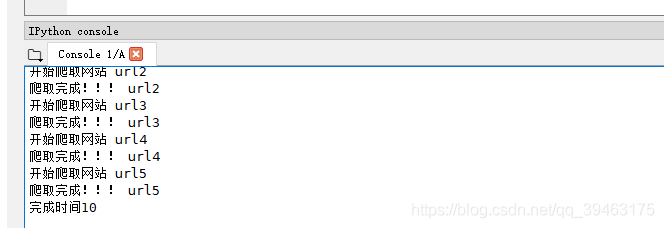
urls = ['url1','url2','url3','url4','url5']
beginTime = time.time()#开始计时
for url in urls:
getPage(url)
endTime= time.time()#结束计时
print("完成时间%d"%(endTime - beginTime))
下面通过模拟爬取网站来完成对多线程,多进程,协程的理解。
二、多线程实现
import time
#使用线程池对象
from multiprocessing.dummy import Pool
def getPage(url):
print("开始爬取网站",url)
time.sleep(2)#阻塞
print("爬取完成!!!",url)
urls = ['url1','url2','url3','url4','url5']
beginTime = time.time()#开始计时
#准备开启5个线程,并示例化对象
pool = Pool(5)
pool.map(getPage, urls)#urls是可迭代对象,里面每个参数都会给getPage方法处理
endTime= time.time()#结束计时
print("完成时间%d"%(endTime - beginTime))
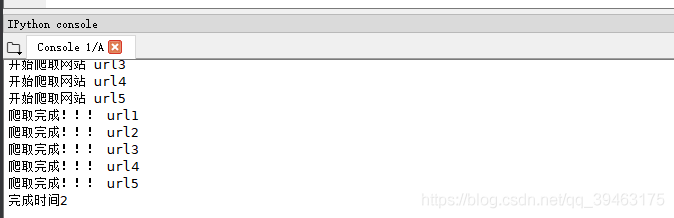
完成时间只需要2s!!!!!!!!
线程池使用原则:适合处理耗时并且阻塞的操作
三、协程实现
单线程+异步协程!!!!!!!!!!强烈推荐,目前流行的方式。
相关概念:

#%%
import time
#使用协程
import asyncio
async def getPage(url): #定义了一个协程对象,python中函数也是对象
print("开始爬取网站",url)
time.sleep(2)#阻塞
print("爬取完成!!!",url)
#async修饰的函数返回的对象
c = getPage(11)
#创建事件对象
loop_event = asyncio.get_event_loop()
#注册并启动looP
loop_event.run_until_complete(c)
#task对象使用,封装协程对象c
'''
loop_event = asyncio.get_event_loop()
task = loop_event.create_task(c)
loop_event.run_until_complete(task)
'''
#Future对象使用,封装协程对象c 用法和task差不多
'''
loop_event = asyncio.get_event_loop()
task = asyncio.ensure_future(c)
loop_event.run_until_complete(task)
'''
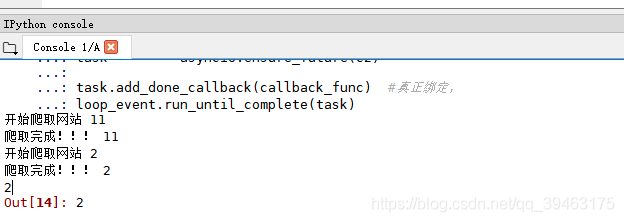
#绑定回调使用
async def getPage2(url): #定义了一个协程对象,python中函数也是对象
print("开始爬取网站",url)
time.sleep(2)#阻塞
print("爬取完成!!!",url)
return url
#async修饰的函数返回的对象
c2 = getPage2(2)
def callback_func(task):
print(task.result()) #task.result()返回任务对象中封装的协程对象对应函数的返回值
#绑定回调
loop_event = asyncio.get_event_loop()
task = asyncio.ensure_future(c2)
task.add_done_callback(callback_func) #真正绑定,
loop_event.run_until_complete(task)
输出:
四、多任务协程实现
import time
#使用多任务协程
import asyncio
urls = ['url1','url2','url3','url4','url5']
async def getPage(url): #定义了一个协程对象,python中函数也是对象
print("开始爬取网站",url)
#在异步协程中如果出现同步模块相关的代码,那么无法实现异步
#time.sleep(2)#阻塞
await asyncio.sleep(2)#遇到阻塞操作必须手动挂起
print("爬取完成!!!",url)
return url
beginTime = time.time()
#任务列表,有多个任务
tasks = []
for url in urls:
c = getPage(url)
task = asyncio.ensure_future(c)#创建任务对象
tasks.append(task)
loop = asyncio.get_event_loop()
loop.run_until_complete(asyncio.wait(tasks))#不能直接放task,需要封装进入asyncio,wait()方法中
endTime = time.time()
print("完成时间%d"%(endTime - beginTime))
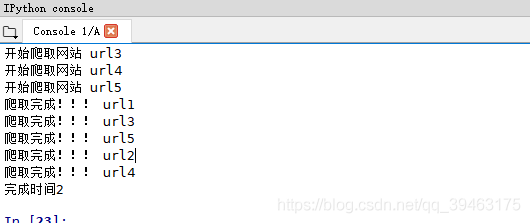
此时不能用time.sleep(2),用了还是10秒
对于真正爬取过程中,如在getPage()方法中真正爬取数据时,即requests.get(url) ,它是基于同步方式实现。应该使用异步网络请求模块aiohttp
参考下面代码:
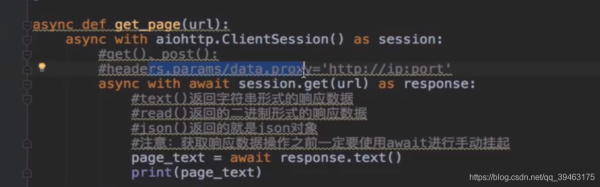
async def getPage(url): #定义了一个协程对象,python中函数也是对象
print("开始爬取网站",url)
#在异步协程中如果出现同步模块相关的代码,那么无法实现异步
#requests.get(url)#阻塞
async with aiohttp.ClintSession() as session:
async with await session.get(url) as response: #手动挂起
page_text = await response.text() #.text()返回字符串,read()返回二进制数据,注意不是content
print("爬取完成!!!",url)
return page_text
到此这篇关于Python异步爬虫实现原理与知识总结的文章就介绍到这了,更多相关Python异步爬虫内容请搜索我们以前的文章或继续浏览下面的相关文章希望大家以后多多支持我们!
相关推荐
-

Python爬虫之必备chardet库
一.chardet库的安装与介绍 玩儿过爬虫的朋友应该知道,在爬取不同的网页时,返回结果会出现乱码的情况.比如,在爬取某个中文网页的时候,有的页面使用GBK/GB2312,有的使用UTF8,如果你需要去爬一些页面,知道网页编码很重要的. 虽然HTML页面有charset标签,但是有些时候是不对的,那么chardet就能帮我们大忙了.使用 chardet 可以很方便的实现字符串/文件的编码检测. 如果你安装过Anaconda,那么可以直接使用chardet库.如果你只是安装了Python的话,就需
-
Django利用Cookie实现反爬虫的例子
我们知道,Diango 接收的 HTTP 请求信息里带有 Cookie 信息.Cookie的作用是为了识别当前用户的身份,通过以下例子来说明Cookie的作用.例: 浏览器向服务器(Diango)发送请求,服务器做出响应之后,二者便会断开连接(会话结束),下次用户再来请求服务器,服务器没有办法识别此用户是谁,比如用户登录功能,如果没有 Cookie 机制支持,那么只能通过查询数据库实现,并且每次刷新页面都要重新操作一次用户登录才可以识别用户,这会给开发人员带来大量的冗余工作,简单的用户登录功能会
-
Python爬虫框架-scrapy的使用
Scrapy Scrapy是纯python实现的一个为了爬取网站数据.提取结构性数据而编写的应用框架. Scrapy使用了Twisted异步网络框架来处理网络通讯,可以加快我们的下载速度,并且包含了各种中间件接口,可以灵活的完成各种需求 1.安装 sudo pip3 install scrapy 2.认识scrapy框架 2.1 scrapy架构图 Scrapy Engine(引擎): 负责Spider.ItemPipeline.Downloader.Scheduler中间的通讯,信号.数据传递
-
python爬虫请求库httpx和parsel解析库的使用测评
Python网络爬虫领域两个最新的比较火的工具莫过于httpx和parsel了.httpx号称下一代的新一代的网络请求库,不仅支持requests库的所有操作,还能发送异步请求,为编写异步爬虫提供了便利.parsel最初集成在著名Python爬虫框架Scrapy中,后独立出来成立一个单独的模块,支持XPath选择器, CSS选择器和正则表达式等多种解析提取方式, 据说相比于BeautifulSoup,parsel的解析效率更高. 今天我们就以爬取链家网上的二手房在售房产信息为例,来测评下http
-
python爬虫基础之简易网页搜集器
简易网页搜集器 前面我们已经学会了简单爬取浏览器页面的爬虫.但事实上我们的需求当然不是爬取搜狗首页或是B站首页这么简单,再不济,我们都希望可以爬取某个特定的有信息的页面. 不知道在学会了爬取之后,你有没有跟我一样试着去爬取一些搜索页面,比如说百度.像这样的页面 注意我红笔划的部分,这是我打开的网页.现在我希望能爬取这一页的数据,按我们前面学的代码,应该是这样写的: import requests if __name__ == "__main__": # 指定URL url = &quo
-
Python爬虫之爬取最新更新的小说网站
一.引言 这个五一假期自驾回老家乡下,家里没装宽带,用手机热点方式访问网络.这次回去感觉4G信号没有以前好,通过百度查找小说最新更新并打开小说网站很慢,有时要打开好多个网页才能找到可以正常打开的最新更新.为了躲懒,老猿决定利用Python爬虫知识,写个简单应用自己查找小说最新更新并访问最快的网站,花了点时间研究了一下相关报文,经过近一天时间研究和编写,终于搞定,下面就来介绍一下整个过程. 二.关于相关访问请求及应答报文 2.1.百度搜索请求 我们通过百度网页的搜索框进行搜索时,提交的url请求是
-
python基础之爬虫入门
前言 python基础爬虫主要针对一些反爬机制较为简单的网站,是对爬虫整个过程的了解与爬虫策略的熟练过程. 爬虫分为四个步骤:请求,解析数据,提取数据,存储数据.本文也会从这四个角度介绍基础爬虫的案例. 一.简单静态网页的爬取 我们要爬取的是一个壁纸网站的所有壁纸 http://www.netbian.com/dongman/ 1.1 选取爬虫策略--缩略图 首先打开开发者模式,观察网页结构,找到每一张图对应的的图片标签,可以发现我们只要获取到标黄的img标签并向它发送请求就可以得到壁纸的预览图
-
python爬虫之爬取百度翻译
破解百度翻译 翻译是一件麻烦的事情,如果可以写一个爬虫程序直接爬取百度翻译的翻译结果就好了,可当我打开百度翻译的页面,输入要翻译的词时突然发现不管我要翻译什么,网址都没有任何变化,那么百度翻译要怎么爬取呢? 爬取百度翻译之前,我们先要明白百度翻译是怎么在不改变网址的情况下实现翻译的.百度做到这一点是用 AJAX 实现的,简单地说,AJAX的作用是在不重新加载网页的情况下进行局部的刷新. 了解了这一点,那么我们要怎么得到 AJAX 工作时请求的URL呢?老规矩,使用抓包工具. 爬虫步骤 在 "百度
-
Python中利用aiohttp制作异步爬虫及简单应用
摘要: 简介 asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--aiohttp,它可以帮助我们异步地实现HTTP请求,从而使得我们的程序效率大大提高. 简介 asyncio可以实现单线程并发IO操作,是Python中常用的异步处理模块.关于asyncio模块的介绍,笔者会在后续的文章中加以介绍,本文将会讲述一个基于asyncio实现的HTTP框架--ai
-
python爬虫之生活常识解答机器人
一.前言 今天教大家如何用Python爬虫去搭建一个「生活常识解答」机器人. 思路:这个机器人主要是依托于"阿里达摩院发布的语言模型PLUG",通过爬虫的方式,发送post请求(提问),然后返回json数据(回答) 二.问答平台 这个「生活常识解答」机器人采用的是:阿里达摩院发布的语言模型PLUG(最近刚发布的,目前是测试阶段) 该模型参数规模达270亿,采用1TB以上高质量中文文本训练数据,包括了新闻.小说.诗歌.常识问答等类型. 三.原页面效果 这里是需要登录阿里云账号,登录之后可
-
Python爬虫之爬取二手房信息
前言 说到二手房信息,不知道你们心里最先跳出来的公司(网站)是什么,反正我心里第一个跳出来的是网站是 58 同城.哎呦,我这暴脾气,想到就赶紧去干. 但很显然,我失败了.说显然,而不是不幸,这是因为 58 同城是大公司,我这点本事爬不了数据是再正常不过的了.下面来看看 58 同城的反爬手段了.这是我爬取下来的网页源码. 我们看到爬取下来的源码有很多英文大写字母和数字是网页源码中没有的,后来我了解到 58 同城对自己的网站的源码进行了文本加密,所以就出现了我爬取到的情况. 爬取二手房信息 我打开
-
用Python爬虫破解滑动验证码的案例解析
做爬虫总会遇到各种各样的反爬限制,反爬的第一道防线往往在登录就出现了,为了限制爬虫自动登录,各家使出了浑身解数,所谓道高一尺魔高一丈. 今天分享个如何简单处理滑动图片的验证码的案例. 类似这种拖动滑块移动到图片中缺口位置与之重合的登录验证在很多网站或者APP都比较常见,因为它对真实用户体验友好,容易识别.同时也能拦截掉大部分初级爬虫. 作为一只python爬虫,如何正确地自动完成这个验证过程呢? 先来分析下,核心问题其实是要怎么样找到目标缺口的位置,一旦知道了位置,我们就可以借用selenium
-
Python爬虫之线程池的使用
一.前言 学到现在,我们可以说已经学习了爬虫的基础知识,如果没有那些奇奇怪怪的反爬虫机制,基本上只要有时间分析,一般的数据都是可以爬取的,那么到了这个时候我们需要考虑的就是爬取的效率了,关于提高爬虫效率,也就是实现异步爬虫,我们可以考虑以下两种方式:一是线程池的使用(也就是实现单进程下的多线程),一是协程的使用(如果没有记错,我所使用的协程模块是从python3.4以后引入的,我写博客时使用的python版本是3.9). 今天我们先来讲讲线程池. 二.同步代码演示 我们先用普通的同步的形式写一段